三十功名尘与土,八千里路云和月
Java
源文件规则
一个完整的Java。源程序应该包括下列部分:
package语句,该部分至多只有一句,必须放在源程序的第一句。
import语句,该部分可以有若干import语句或者没有,必须放在所有的类定义之前。
public classDefinition,公共类定义部分,至多只有一个公共类的定义,Java语言规定该Java源程序的文件名必须与该公共类名完全一致。
classDefinition,类定义部分,可以有0个或者多个类定义。
interfaceDefinition,接口定义部分,可以有0个或者多个接口定义。
1 | package javawork.helloworld; |
Public类 && main
为什么JAVA文件中只能含有一个Public类?
java 程序是从一个 public 类的 main 函数开始执行的,(其实是main线程),就像 C 程序 是从 main() 函数开始执行一样。 只能有一个 public 类是为了给类装载器提供方便。 一个 public 类只能定义在以它的类名为文件名的文件中。
每个编译单元(文件)都只有一个 public 类。因为每个编译单元都只能有一个公共接口,用 public 类来表现。如果有一个以上的 public 类,编译器就会报错。 并且 public类的名称必须与文件名相同(严格区分大小写)。 当然一个编译单元内也可以没有 public 类。
命名规则
package的命名: package 的名字由全部小写的字母组成,例如:com.runoob。
class和interface的命名: class和interface的名字由大写字母开头而其他字母都小写的单词组成(大驼峰),例如:Person,RuntimeException。
class中变量的命名: 变量的名字用一个小写字母开头,后面的单词用大写字母开头,例如:index,currentImage。
class中方法的命名: 方法的名字用一个小写字母开头,后面的单词用大写字母开头,例如:run(),getBalance()。
staticfinal变量的命名: static final变量的名字所有字母都大写,并且能表示完整含义。例如:PI,PASSWORD。
import && package 规则
当在一个源文件中定义多个类,并且还有import语句和package语句时,要特别注意这些规则。
一个源文件中只能有一个 public 类
一个源文件可以有多个非 public 类
源文件的名称应该和 public 类的类名保持一致。例如:源文件中 public 类的类名是 Employee,那么源文件应该命名为Employee.java。
如果一个类定义在某个包中,那么 package 语句应该在源文件的首行。
如果源文件包含 import 语句,那么应该放在 package 语句和类定义之间。如果没有 package 语句,那么 import 语句应该在源文件中最前面。
import 语句和 package 语句对源文件中定义的所有类都有效。在同一源文件中,不能给不同的类不同的包声明。
Java package
包主要用来对类和接口进行分类。当开发 Java 程序时,可能编写成百上千的类,因此很有必要对类和接口进行分类。
package 的作用就是 c++ 的 namespace 的作用,防止名字相同的类产生冲突。Java 编译器在编译时,直接根据 package 指定的信息直接将生成的 class 文件生成到对应目录下。如 package aaa.bbb.ccc 编译器就将该 .java 文件下的各个类生成到 ./aaa/bbb/ccc/ 这个目录。
Java import
在 Java 中,如果给出一个完整的限定名,包括包名、类名,那么 Java 编译器就可以很容易地定位到源代码或者类。import 语句就是用来提供一个合理的路径,使得编译器可以找到某个类。
例如,下面的命令行将会命令编译器载入 java_installation/java/io 路径下的所有类import java.io.*;
java因强制要求类名(唯一的public类)和文件名统一,因此在引用其它类时无需显式声明。在编译时,编译器会根据类名去寻找同名文件。
import 是为了简化使用 package 之后的实例化的代码。假设 ./aaa/bbb/ccc/ 下的 A 类,假如没有 import,实例化A类为:new aaa.bbb.ccc.A(),使用 import aaa.bbb.ccc.A 后,就可以直接使用 new A() 了,也就是编译器匹配并扩展了 aaa.bbb.ccc. 这串字符串。
变量
变量命名规则
实例变量、局部变量、静态变量 、参数
驼峰命名法(Camel Case): 在变量名中使用驼峰命名法,即将每个单词的首字母大写,除了第一个单词外,其余单词的首字母都采用大写形式。例如:myVariableName。
静态变量(类变量)通常也可以使用大写蛇形命名法(Upper Snake Case),全大写字母,单词之间用下划线分隔。
1 | // 使用驼峰命名法 |
常量
使用全大写字母,单词之间用下划线分隔。
常量通常使用 final 修饰。
类名
使用驼峰命名法(大驼峰)。
应该以大写字母开头。
1 | public class MyClass { |
普通变量
一个类可以包含以下类型变量:
局部变量:在方法、构造方法或者语句块中定义的变量被称为局部变量。变量声明和初始化都是在方法中,方法结束后,变量就会自动销毁。
局部变量是在栈上分配的。
局部变量没有默认值,所以局部变量被声明后,必须经过初始化(初始化可以在声明时或后面的代码中进行),才可以使用。如果在使用局部变量之前不初始化它,编译器会报错。
成员变量:成员变量是定义在类中,方法体之外的变量。这种变量在创建对象的时候实例化。成员变量可以被类中方法、构造方法和特定类的语句块访问。
类变量:类变量也声明在类中,方法体之外,但必须声明为 static 类型。
由static修饰的变量称为静态变量,其实质上就是一个全局变量。如果某个内容是被所有对象所共享,那么该内容就应该用静态修饰;没有被静态修饰的内容,其实是属于对象的特殊描述。
不同的对象的实例变量将被分配不同的内存空间, 如果类中的成员变量有类变量,那么所有对象的这个类变量都分配给相同的一处内存,改变其中一个对象的这个类变量会影响其他对象的这个类变量,也就是说对象共享类变量。
调用方式不同
成员变量只能被对象调用。
静态变量可以被对象调用,还可以被类名调用。
static 关键字,是一个修饰符,用于修饰成员(成员变量和成员函数)。
特点:
1、想要实现对象中的共性数据的对象共享。可以将这个数据进行静态修饰。
2、被静态修饰的成员,可以直接被类名所调用。也就是说,静态的成员多了一种调用方式。类名.静态方式。
3、静态随着类的加载而加载。而且优先于对象存在。
成员变量和静态变量的区别:
1、成员变量所属于对象。所以也称为实例变量。
静态变量所属于类。所以也称为类变量。
2、成员变量存在于堆内存中。
静态变量存在于方法区中。
3、成员变量随着对象创建而存在。随着对象被回收而消失。
静态变量随着类的加载而存在。随着类的消失而消失。
4、成员变量只能被对象所调用 。
静态变量可以被对象调用,也可以被类名调用。
所以,成员变量可以称为对象的特有数据,静态变量称为对象的共享数据。
生命周期
静态变量的生命周期与程序的生命周期一样长,即它们在类加载时被创建,在整个程序运行期间都存在,直到程序结束才会被销毁。因此,静态变量可以用来存储整个程序都需要使用的数据,如配置信息、全局变量等。
静态变量的线程安全性
Java 中的静态变量是属于类的,而不是对象的实例。因此,当多个线程同时访问一个包含静态变量的类时,需要考虑其线程安全性。
静态变量在内存中只有一份拷贝,被所有实例共享。因此,如果一个线程修改了静态变量的值,那么其他线程在访问该静态变量时也会看到修改后的值。这可能会导致并发访问的问题,因为多个线程可能同时修改静态变量,导致不确定的结果或数据一致性问题。
为了确保静态变量的线程安全性,需要采取适当的同步措施,如同步机制、原子类或 volatile 关键字,以便在多线程环境中正确地读取和修改静态变量的值。
在 Java 中使用 final 关键字来修饰常量,声明方式和变量类似:final double PI = 3.1415927;
前缀 0 表示 8 进制,而前缀 0x 代表 16 进制, 例如:
int decimal = 100;
int octal = 0144;
int hexa = 0x64;
通常使用大写字母表示常量。
引用类型变量
在Java中,引用类型的变量非常类似于C/C++的指针。引用类型指向一个对象,指向对象的变量是引用变量。这些变量在声明时被指定为一个特定的类型,比如 Employee、Puppy 等。变量一旦声明后,类型就不能被改变了。
对象、数组都是引用数据类型。
所有引用类型的默认值都是null。
引用类型变量在声明后必须通过实例化开辟数据空间,才能对变量所指向的对象进行访问。
MyDate today; //将变量分配一个保存引用的空间
today = new MyDate(); // 这句话是2步,首先执行new MyDate(),给today变量开辟数据空间,然后再执行赋值操作
引用变量赋值:
MyDate a,b; // 在内存开辟两个引用空间
a = new MyDate(); // 开辟MyDate对象的数据空间,并把该空间的首地址赋给a
b = a; // 将a存储空间中的地址写到b的存储空间中
参数变量
方法参数变量的值传递方式有两种:值传递和引用传递。
值传递:在方法调用时,传递的是实际参数的值的副本。当参数变量被赋予新的值时,只会修改副本的值,不会影响原始值。Java 中的基本数据类型都采用值传递方式传递参数变量的值。
引用传递:在方法调用时,传递的是实际参数的引用(即内存地址)。当参数变量被赋予新的值时,会修改原始值的内容。Java 中的对象类型采用引用传递方式传递参数变量的值。
static和final
在Java中,static和final是两个常用的关键字,用于修饰类的成员变量和方法。static和final的区别是:1、作用范围;2、关联性;3、修改能力;4、继承和重写。作用范围是指,static用于修饰类成员(静态变量和静态方法),而final用于修饰类、成员变量和方法。使用static修饰的成员变量称为静态变量,也称为类变量。
重写(Override):是子类对父类允许方位的方法的实现过程进行重新编写,返回值和形参都不能改变。即外壳不变,核心重写。
重载(Overload):是在一个类里面,方法名字相同,二参数不同。返回类型可以相同也可以不同,每个重载的方法(或者构造函数)都必须有一个独一无二的参数类型列表。
一、static关键字
static是一个用于修饰类成员的关键字,可以用于静态变量和静态方法。
静态变量(静态属性): 使用static修饰的成员变量称为静态变量,也称为类变量。静态变量在类加载时被初始化,只有一个副本存在于内存中,并且所有该类的实例共享相同的静态变量。可以通过类名直接访问静态变量,无需创建对象。
静态方法: 使用static修饰的方法称为静态方法。静态方法属于类而不属于对象,可以通过类名直接调用,无需创建对象。静态方法中只能访问静态成员变量,而不能访问非静态成员变量,因为非静态成员变量是属于对象的,而静态方法是属于类的。
注意:
静态方法中不能使用this关键字,因为this代表当前对象,而静态方法不属于任何对象。
静态方法中不能使用super关键字,因为super代表父类对象,而静态方法与对象无关。
二、final关键字
final是一个用于修饰类、成员变量和方法的关键字。
final类: 使用final修饰的类称为final类。final类是不能被继承的,即不能有子类。通常用于确保类的完整性和安全性。
final成员变量(常量): 使用final修饰的成员变量称为final变量或常量。final成员变量必须在声明时或构造函数中进行初始化,并且一旦初始化后就不能再修改其值。常量通常用大写字母表示,并且在多个单词之间用下划线分隔。
final方法: 使用final修饰的方法称为final方法。final方法不能被子类重写,即不能被子类进行覆盖。通常用于确保方法的行为不会被子类修改。
注意:
final成员变量可以在声明时初始化,也可以在构造函数中初始化,但一旦初始化后就不能再修改。
final方法不能被子类重写,但可以被继承。
三、区别和联系
作用范围: static用于修饰类成员(静态变量和静态方法),而final用于修饰类、成员变量和方法。
关联性: static关键字是与类相关联的,可以通过类名直接访问静态成员。而final关键字是与类的实例相关联的,用于限制类、变量或方法的特性。
修改能力: 静态变量可以被修改,其值可以在程序运行过程中发生变化。而final成员变量一旦被初始化后,其值不可再变更,成为常量。
继承和重写: final修饰的类不能被继承,final修饰的方法不能被重写(覆盖),但static修饰的方法可以被重写,但不能被覆盖。
主要参考:
static和final的区别是什么
上面提到对static修饰的方法的重写(Override)和覆盖,总结地说:static修饰的方法可以在子类重写,但是不会起到任何作用,因为父类的静态方法在编译前已经加载,只与类有关,与类的实例对象无关。即:
在Java中,如果父类中含有一个静态方法,且在子类中也含有一个返回类型、方法名、参数列表均与之相同的静态方法,那么该子类实际上只是将父类中的该同名方法进行了隐藏,而非重写(就是上面“可以重写,但没有覆盖”的意思)。换句话说,父类和子类中含有的其实是两个没有关系的方法,它们的行为也并不具有多态性。正如同《Java编程思想》中所说:“一旦你了解了多态机制,可能就会认为所有事物都可以多态地发生。然而,只有普通方法的调用可以是多态的。如果你直接访问某个域,(不管是否是静态static),这个访问就将在编译期间进行解析。”这也很好地理解了,为什么在Java中,static方法和final方法(private方法属于final方法)是前期绑定,而其他所有的方法都是后期绑定了。
参考:
父类静态方法可以重写吗?
【面试】Java static方法能否被重写或重载
类
Java Number && Math 类
在实际开发过程中,我们经常会遇到需要使用对象,而不是内置数据类型的情形。为了解决这个问题,Java 语言为每一个内置数据类型提供了对应的包装类。
所有的包装类(Integer、Long、Byte、Double、Float、Short)都是抽象类 Number 的子类。
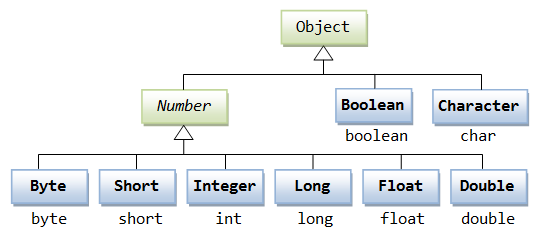
这种由编译器特别支持的包装称为装箱,所以当内置数据类型被当作对象使用的时候,编译器会把内置类型装箱为包装类。相似的,编译器也可以把一个对象拆箱为内置类型。Number 类属于 java.lang 包。
Java 的 Math 包含了用于执行基本数学运算的属性和方法,如初等指数、对数、平方根和三角函数。
Math 的方法都被定义为 static 形式,通过 Math 类可以在主函数中直接调用。System.out.println("90 度的正弦值:" + Math.sin(Math.PI/2));
以下列出 Number & Math 类常用的一些方法:
1 | 1 xxxValue() |
Integer.parseInt转换二进制数为int整数异常
关于java中二进制数存储等一些问题。
请注意,在某些语言(如 Java)中,没有无符号整数类型。
在这种情况下,输入和输出都将被指定为有符号整数类型。
在 Java 中,编译器使用二进制补码记法来表示有符号整数。
注:0和正数补码就是原码,负数的补码是除了符号位取反之后加一。
int pnb3 = Integer.parseUnsignedInt(nb, 2)
Integer.parseInt(s)与Integer.valueOf(s)的区别详解 好文章
Integer.parseInt(s)的作用就是把字符串s解析成有符号的int基本类型。
Integer.valueOf(s)把字符串s解析成Integer对象类型,返回的integer 可以调用对象中的方法。
Integer.parseInt(s)与Integer.valueOf(s)的区别
Integer.parseInt(s)
Integer.parseInt(s)多次解析同一个字符串得到的int基本类型数据是相等的,可以直接通过“==”进行判断是否相等。
int是基本类型,不含有equals方法,所以只能用“==”比较,基本类型用“==”比较的是两个值的大小。
Integer.valueOf(s)
Integer.valueOf(s)多次解析相同的一个字符串时,得到的是Integer类型的对象,得到的对象有时是同一个对象,有时是不同的对象,要根据把s字符串解析的整数值的大小进行决定:
如果s字符串对应的整数值在 -128~127之间,则解析出的Integer类型的对象是同一个对象;如果s字符串对应的整数值不在 -128~127之间,则解析出的Integer类型的对象不是同一个对象。不管对象是否相等,对象中的value值是相等的。
原因: 为什么Integer.valueOf(s)会出现这种情况呢?这是由于JDK中源码已经定义好的。由于在-128127之间的整数值用的比较频繁,当每次要创建一个value值在-128127之间的Integer对象时,直接从缓存中拿到这个对象,所以value值相同的Integer对象都是对应缓存中同一个对象。-128~127之外的整数值用的不是太频繁,每次创建value值相同的Integer对象时,都是重新创建一个对象,所以创建的对象不是同一个对象。
Integer.parseInt(s)与Integer.valueOf(s)的联系
Integer.parseInt(s)是把字符串解析成int基本类型,Integer.valueOf(s)是把字符串解析成Integer对象类型,其实int就是Integer解包装,Integer就是int的包装,在jdk8中已经自动实现了自动解包装和自动包装,所以两种方式都能得到想要的整数值。
把Integer类型自动解包装成int类型。
1 | Integer n = new Integer(100); |
Java Character 类
Character 类用于对单个字符进行操作。
Character 类在对象中包装一个基本类型 char 的值
在实际开发过程中,我们经常会遇到需要使用对象,而不是内置数据类型的情况。为了解决这个问题,Java语言为内置数据类型char提供了包装类Character类。
Character类提供了一系列方法来操纵字符。你可以使用Character的构造方法创建一个Character类对象,例如:Character ch = new Character('a');
将一个char类型的参数传递给需要一个Character类型参数的方法时,那么编译器会自动地将char类型参数转换为Character对象。 这种特征称为装箱,反过来称为拆箱。
1 | 1 isLetter() |
Java String 类
java.lang.String类代表字符串。
Java程序中所有字符串文字都为此类的对象。
注意:String类首字母大写,类的首字母都大写。
以”xx”形式给出的字符串对象,在字符常量池中存储。
字符串类型,可以定义字符串引用变量指向字符串对象。(Java中对象存放在堆中,堆的空间不是连续的所以比较大,引用存放在栈中,栈是连续的并且空间比较小)
String变量每次的修改都是产生了新的字符串对象并且引用修改指向。
原来的字符串对象都是没有改变的,所以称字符串不可变。
以""方式给出的字符串对象,在字符串常量池中储存,而且相同内容只会在其中存储一份。
通过构造器new对象,每new一次都会产生一个新对象,放在堆内存中。
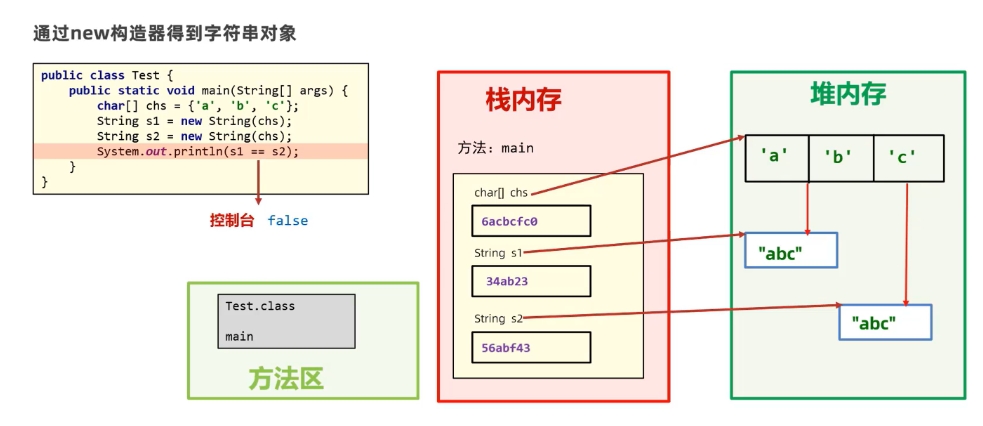
字符串内容比较
直接使用==对比的是字符串对象存储的地址。
比较内容要用.equals()方法。
1 | //创建了两个对象 |
字符串常量池应该是独立于堆区的。
Java存在编译优化机制
1 | String s1 = "abc"; |
直接使用==对比的是字符串对象存储的地址。
比较内容要用.equals()方法。
.equalsIgnoreCase()可以忽略大小写比较,常用于对比验证码。

1 | //模拟用户登录功能 |
Java 正则表达式
正则表达式定义了字符串的模式。
正则表达式可以用来搜索、编辑或处理文本。
Java 提供了 java.util.regex 包,它包含了 Pattern 和 Matcher 类,用于处理正则表达式的匹配操作。
一个字符串其实就是一个简单的正则表达式,例如 Hello World 正则表达式匹配 “Hello World” 字符串。
.(点号)也是一个正则表达式,它匹配任何一个字符如:”a” 或 “1”。
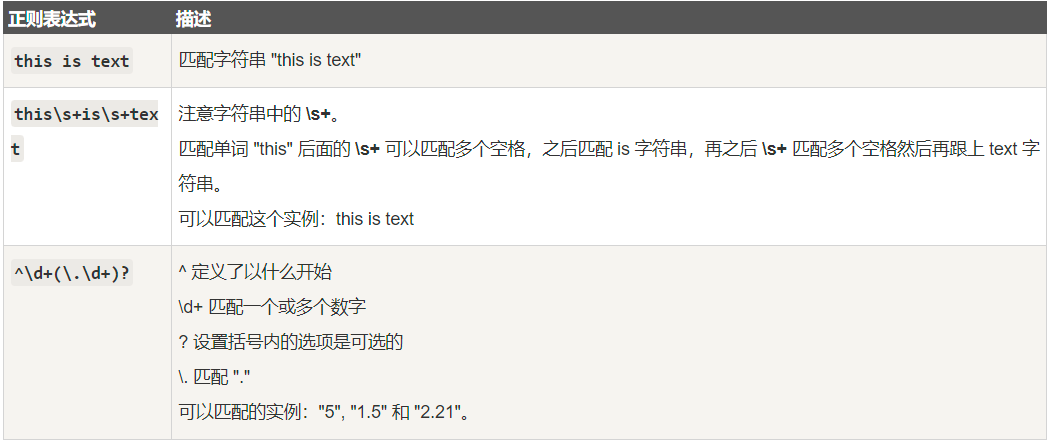
java.util.regex 包
java.util.regex 包是 Java 标准库中用于支持正则表达式操作的包。
java.util.regex 包主要包括以下三个类:
Pattern 类:
pattern 对象是一个正则表达式的编译表示。Pattern 类没有公共构造方法。要创建一个 Pattern 对象,你必须首先调用其公共静态编译方法,它返回一个 Pattern 对象。该方法接受一个正则表达式作为它的第一个参数。
Matcher 类:
Matcher 对象是对输入字符串进行解释和匹配操作的引擎。与Pattern 类一样,Matcher 也没有公共构造方法。你需要调用 Pattern 对象的 matcher 方法来获得一个 Matcher 对象。
PatternSyntaxException:
PatternSyntaxException 是一个非强制异常类,它表示一个正则表达式模式中的语法错误。
除了 Stream、File、IO 和 Scanner类 其他基本都认真看了。
用这些集合框架前一定要使用import语句:import java.util.*;
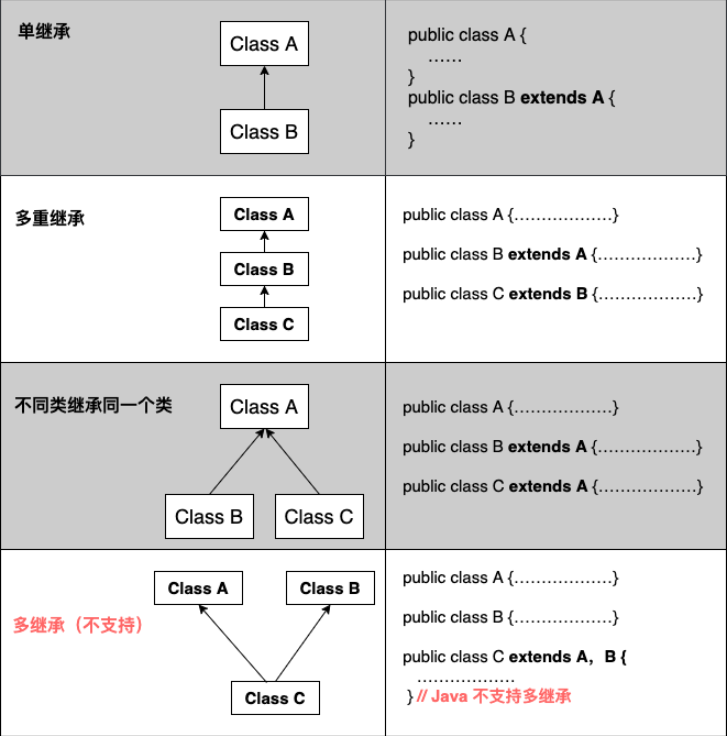
继承
需要注意的是 Java 不支持多继承,但支持多重继承。
继承的特性
子类拥有父类所有的属性、方法,注意是所有的,但是!private是不可见的,明白了吗?private修饰的只能通过父类的方法去访问,但子类依旧继承了,这点很重要。
子类可以拥有自己的属性和方法,即子类可以对父类进行扩展。
子类可以用自己的方式实现父类的方法(Override,重写。区别于重载Overload)。
提高了类之间的耦合性(继承的缺点,耦合度高就会造成代码之间的联系越紧密,代码独立性越差)。
继承关键字
继承可以使用 extends 和 implements 这两个关键字来实现继承,而且所有的类都是继承于 java.lang.Object(显式或隐式继承),当一个类没有继承的两个关键字,则默认继承 Object祖先类(这个类在 java.lang 包中,编译时默认导入这个包,所以不需要 import)。
在 Java 中,类的继承是单一继承,也就是说,一个子类只能拥有一个父类,所以 extends 只能继承一个类。
使用 implements 关键字可以变相的使java具有多继承的特性,使用范围为类继承接口的情况,可以同时继承多个接口(接口跟接口之间采用逗号分隔)。
1 | public class C implements A,B { |
super关键字:我们可以通过super关键字来实现对父类成员的访问,用来引用当前对象的父类。
this关键字:指向自己的引用。
final 可以用来修饰变量(包括类属性、对象属性、局部变量和形参)、方法(包括类方法和对象方法)和类。
final 含义为 “最终的”。
使用 final 关键字声明类,就是把类定义定义为最终类,不能被继承,或者用于修饰方法,该方法不能被子类重写:
1 | class Animal { |
重写(Override)
重写是子类对父类的允许访问的方法的实现过程进行重新编写, 返回值和形参都不能改变。即外壳不变,核心重写!
重写的好处在于子类可以根据需要,定义特定于自己的行为。 也就是说子类能够根据需要实现父类的方法。
重写方法不能抛出新的检查异常或者比被重写方法申明更加宽泛的异常。例如: 父类的一个方法申明了一个检查异常 IOException,但是在重写这个方法的时候不能抛出 Exception 异常,因为 Exception 是 IOException 的父类,抛出 IOException 异常或者 IOException 的子类异常。
在面向对象原则里,重写意味着可以重写任何现有方法。实例如下:
1 | class Animal{ |
在上面的例子中可以看到,尽管 b 属于 Animal 类型,但是它运行的是 Dog 类的 move方法。
这是由于在编译阶段,只是检查参数的引用类型。
然而在运行时,Java 虚拟机(JVM)指定对象的类型并且运行该对象的方法。
因此在上面的例子中,之所以能编译成功,是因为 Animal 类中存在 move 方法,然而运行时,运行的是特定对象的方法。
思考以下例子:
1 | class Animal{ |
方法的重写规则
参数列表与被重写方法的参数列表必须完全相同。
返回类型与被重写方法的返回类型可以不相同,但是必须是父类返回值的派生类(java5 及更早版本返回类型要一样,java7 及更高版本可以不同)。
访问权限不能比父类中被重写的方法的访问权限更低。例如:如果父类的一个方法被声明为 public,那么在子类中重写该方法就不能声明为 protected。
父类的成员方法只能被它的子类重写。
声明为 final 的方法不能被重写。
声明为 static 的方法不能被重写,但是能够被再次声明。
子类和父类在同一个包中,那么子类可以重写父类所有方法,除了声明为 private 和 final 的方法。
子类和父类不在同一个包中,那么子类只能够重写父类的声明为 public 和 protected 的非 final 方法。
重写的方法能够抛出任何非强制异常,无论被重写的方法是否抛出异常。但是,重写的方法不能抛出新的强制性异常,或者比被重写方法声明的更广泛的强制性异常,反之则可以。
构造方法不能被重写。
如果不能继承一个类,则不能重写该类的方法。
重载(Overload)
重载(overloading) 是在一个类里面,方法名字相同,而参数不同。返回类型可以相同也可以不同。
每个重载的方法(或者构造函数)都必须有一个独一无二的参数类型列表。
最常用的地方就是构造器的重载。
重载规则:
被重载的方法必须改变参数列表(参数个数或类型不一样);
被重载的方法可以改变返回类型;
被重载的方法可以改变访问修饰符;
被重载的方法可以声明新的或更广的检查异常;
方法能够在同一个类中或者在一个子类中被重载。
无法以返回值类型作为重载函数的区分标准。

总结
方法的重写(Overriding)和重载(Overloading)是java多态性的不同表现,重写是父类与子类之间多态性的一种表现,重载可以理解成多态的具体表现形式。
(1)方法重载是一个类中定义了多个方法名相同,而他们的参数的数量不同或数量相同而类型和次序不同,则称为方法的重载(Overloading)。
(2)方法重写是在子类存在方法与父类的方法的名字相同,而且参数的个数与类型一样,返回值也一样的方法,就称为重写(Overriding)。
(3)方法重载是一个类的多态性表现,而方法重写是子类与父类的一种多态性表现。

构造器(构造函数)
子类是不继承父类的构造器(构造方法或者构造函数)的,它只是调用(隐式或显式,并且一定会调用一个,并且调用语句是子类构造函数的第一句,因为子类包含父类的东西,创建对象时一定是先构造父类,接着才能构造子类)。如果父类的构造器带有参数,则必须在子类的构造器中显式地通过 super 关键字调用父类的构造器并配以适当的参数列表。
如果父类构造器没有参数,则在子类的构造器中不需要使用 super 关键字调用父类构造器,系统会自动调用父类的无参构造器。
注意一个事实,不写构造函数时编译器默认一个无参构造函数,但如果写了任何一个构造函数,这个无参构造函数便不会再生成了。
如果父类有一个有参构造函数,并且子类构造函数没有使用super显式调用这个构造器,程序便会报错,因为没有默认的父类无参构造器给子类的构造器调用,所以此时还要再手动补一个父类无参构造器。
子类的所有构造方法内部, 第一行会(隐式)自动先调用父类的无参构造函数super();
如果子类构造方法第一行显式调用了父类构造方法,系统就不再调用无参的super()了。
注意:如果父类没有无参构造函数,创建子类时,不能编译,除非在构造函数代码体中的第一行显式调用父类有参构造函数。
1 | class SuperClass { |
super && this
super 关键字
super 表示使用它的类的父类。super 可用于:
调用父类的构造方法;
调用父类的方法(子类覆盖了父类的方法时);
访问父类的数据域或其他未被重写的方法(可以这样用但没有必要这样用)。
this 关键字
this 关键字表示当前对象。可用于:
限定当前对象的数据域变量。一般用于方法内的局部变量与对象的数据域变量同名的情况。如 this.num = num。this.num 表示当前对象的数据域变量 num,而 num 表示方法中的局部变量。就是局部变量和类变量或成员变量(实例变量)重名了。
继承中的private
子类不能直接使用父类中的 private 属性和方法。
1 | /**建立一个公共动物父类*/ |
继承中的转型 (IMPORTANT)
这个很重要!!!
Java 转型问题其实并不复杂,只要记住一句话:父类引用指向子类对象。
什么叫父类引用指向子类对象,且听我慢慢道来。
从 2 个名词开始说起:向上转型(upcasting) 、向下转型(downcasting)。
举个例子:有2个类,Father 是父类,Son 类继承自 Father。
1 | Father f1 = new Son(); // 这就叫 upcasting (向上转型) |
你或许会问,第1个例子中:Son s1 = (Son)f1; 为什么是正确的呢。
很简单因为 f1 指向一个子类对象,Father f1 = new Son(); 子类 s1 引用当然可以指向子类对象了。
1 | Father f2 = new Father(); |
而 f2 被传给了一个 Father 对象,Father f2 = new Father(); 子类 s1 引用不能指向父类对象。
总结:
1、父类引用指向子类对象,而子类引用不能指向父类对象。
2、把子类对象直接赋给父类引用叫upcasting向上转型,向上转型不用强制转换吗,如:
Father f1 = new Son();
3、把指向子类对象的父类引用赋给子类引用叫向下转型(downcasting),要强制转换,如:
f1 就是一个指向子类对象的父类引用。把f1赋给子类引用 s1 即 Son s1 = (Son)f1;
其中 f1 前面的(Son)必须加上,进行强制转换。
Java 转型问题
这篇文章也很重要 不懂就看。
Java – 父类和子类拥有同名的成员变量的情况
java向上转型后方法变量详细使用规则(父类引用创建子类对象实例)
理解继承
对理解继承来说,最重要的事情是,知道哪些东西被继承了,或者说,子类从父类那里得到了什么。答案是:所有的东西,所有的父类的成员,包括变量和方法,都成为了子类的成员,除了构造方法。构造方法是父类所独有的,因为它们的名字就是类的名字,所以父类的构造方法在子类中不存在。除此之外,子类继承得到了父类所有的成员。
但是得到不等于可以随便使用。每个成员有不同的访问属性,子类继承得到了父类所有的成员,但是不同的访问属性使得子类在使用这些成员时有所不同:有些父类的成员直接成为子类的对外的界面,有些则被深深地隐藏起来,即使子类自己也不能直接访问。下表列出了不同访问属性的父类成员在子类中的访问属性:
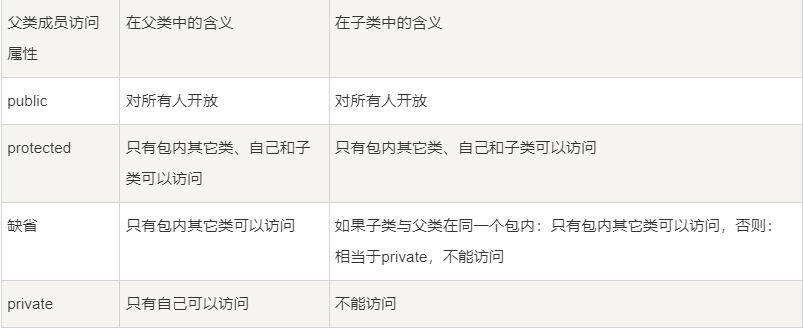
public的成员直接成为子类的public的成员,protected的成员也直接成为子类的protected的成员。Java的protected的意思是包内和子类可访问,所以它比缺省的访问属性要宽一些。而对于父类的缺省的未定义访问属性的成员来说,他们是在父类所在的包内可见,如果子类不属于父类的包,那么在子类里面,这些缺省属性的成员和private的成员是一样的:不可见。父类的private的成员在子类里仍然是存在的,只是子类中不能直接访问。我们不可以在子类中重新定义继承得到的成员的访问属性。如果我们试图重新定义一个在父类中已经存在的成员变量,那么我们是在定义一个与父类的成员变量完全无关的变量,在子类中我们可以访问这个定义在子类中的变量,在父类的方法中访问父类的那个。尽管它们同名但是互不影响。
在构造一个子类的对象时,父类的构造方法也是会被调用的,而且父类的构造方法在子类的构造方法之前被调用。在程序运行过程中,子类对象的一部分空间存放的是父类对象。因为子类从父类得到继承,在子类对象初始化过程中可能会使用到父类的成员。所以父类的空间正是要先被初始化的,然后子类的空间才得到初始化。在这个过程中,如果父类的构造方法需要参数,如何传递参数就很重要了。
多态
多态是同一个行为具有多个不同表现形式或形态的能力。
多态存在的三个必要条件:
继承
重写
父类引用指向子类对象:
Parent p = new Child();(其实就是上面提到的向上向下转型,真的很重要)
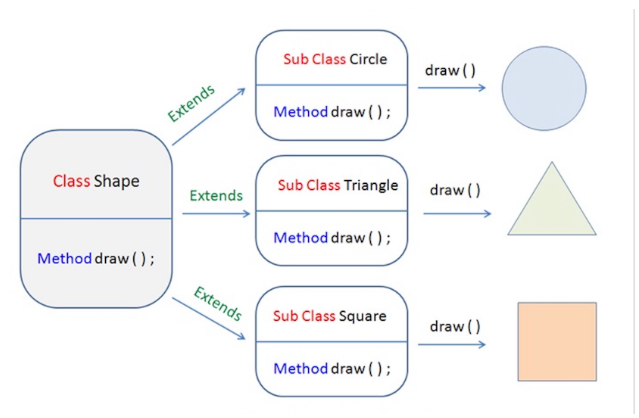
1 | class Shape { |
当使用多态方式调用方法时,首先检查父类中是否有该方法,如果没有,则编译错误;如果有,再去调用子类的同名方法。
多态的好处: 可以使程序有良好的扩展,并可以对所有类的对象进行通用处理。
1 | public class Test { |
如果public static void show(Animal a) 参数不用不用(Animal a),那是不是得写public static void show(Cat a) 和public static void show(Dog a)两个函数,那不是有几个子类要写几个show吗?这就是多态的意义之一。
多态的实现方式
方式一:重写
这个内容已经详细讲过,就不再阐述。
方式二:接口
方式三:抽象类和抽象方法
虚函数
虚函数的存在是为了多态。
Java 中其实没有虚函数的概念,它的普通函数就相当于 C++ 的虚函数(Java 中类的每个普通成员函数都可以被子类重写),动态绑定是Java的默认行为。如果 Java 中不希望某个函数具有虚函数特性,可以加上 final 关键字变成非虚函数。
抽象类 && 抽象方法
在面向对象的概念中,所有的对象都是通过类来描绘的,但是反过来,并不是所有的类都是用来描绘对象的,如果一个类中没有包含足够的信息来描绘一个具体的对象,这样的类就是抽象类。
抽象类除了不能实例化对象之外,类的其它功能依然存在,成员变量、成员方法和构造方法的访问方式和普通类一样。
由于抽象类不能实例化对象,所以抽象类必须被继承,才能被使用。也是因为这个原因,通常在设计阶段决定要不要设计抽象类。
父类包含了子类集合的常见的方法,但是由于父类本身是抽象的,所以不能使用这些方法。
在 Java 中抽象类表示的是一种继承关系,一个类只能继承一个抽象类,而一个类却可以实现多个接口。
抽象方法
如果你想设计这样一个类,该类包含一个特别的成员方法,该方法的具体实现由它的子类确定,那么你可以在父类中声明该方法为抽象方法。
Abstract 关键字同样可以用来声明抽象方法,抽象方法只包含一个方法名,而没有方法体。
抽象方法没有定义,方法名后面直接跟一个分号,而不是花括号。
1 | public abstract class Employee |
声明抽象方法会造成以下两个结果:
如果一个类包含抽象方法,那么该类必须是抽象类。
任何子类必须重写父类的抽象方法,或者声明自身为抽象类。
继承抽象方法的子类必须重写该方法。否则,该子类也必须声明为抽象类。最终,必须有子类实现该抽象方法,否则,从最初的父类到最终的子类都不能用来实例化对象。
如果Salary类继承了Employee类,那么它必须实现computePay()方法:
1 | /* 文件名 : Salary.java */ |
抽象类总结规定
- 抽象类不能被实例化(初学者很容易犯的错),如果被实例化,就会报错,编译无法通过。只有抽象类的非抽象子类可以创建对象。
- 抽象类中不一定包含抽象方法,但是有抽象方法的类必定是抽象类。
- 抽象类中的抽象方法只是声明,不包含方法体,就是不给出方法的具体实现也就是方法的具体功能。
- 构造方法,类方法(用 static 修饰的方法)不能声明为抽象方法。
- 抽象类的子类必须给出抽象类中的抽象方法的具体实现,除非该子类也是抽象类。
接口
接口(英文:Interface),在JAVA编程语言中是一个抽象类型,是抽象方法的集合,接口通常以interface来声明。一个类通过继承接口的方式,从而来继承接口的抽象方法。
接口并不是类,编写接口的方式和类很相似,但是它们属于不同的概念。类描述对象的属性和方法。接口则包含类要实现的方法。
除非实现接口的类是抽象类,否则该类要定义接口中的所有方法。
接口无法被实例化,但是可以被实现。一个实现接口的类,必须实现接口内所描述的所有方法,否则就必须声明为抽象类。另外,在 Java 中,接口类型可用来声明一个变量,他们可以成为一个空指针,或是被绑定在一个以此接口实现的对象。
接口与类相似点:
一个接口可以有多个方法。
接口文件保存在 .java 结尾的文件中,文件名使用接口名。
接口的字节码文件保存在 .class 结尾的文件中。
接口相应的字节码文件必须在与包名称相匹配的目录结构中。
接口与类的区别:
接口不能用于实例化对象。
接口没有构造方法。
接口中所有的方法必须是抽象方法,Java 8 之后 接口中可以使用 default 关键字修饰的非抽象方法。
接口不能包含成员变量,除了 static 和 final 变量。
接口不是被类继承了,而是要被类实现。
接口支持多继承。
接口的声明语法格式如下:
1 | [可见度] interface 接口名称 [extends 其他的接口名] { |
接口有以下特性:
接口是隐式抽象的,当声明一个接口的时候,不必使用abstract关键字。
接口中每一个方法也是隐式抽象的,声明时同样不需要abstract关键字。
接口中的方法都是公有的。
抽象类和接口的区别
- 抽象类中的方法可以有方法体,就是能实现方法的具体功能,但是接口中的方法不行。
- 抽象类中的成员变量可以是各种类型的,而接口中的成员变量只能是 public static final 类型的。
- 接口中不能含有静态代码块以及静态方法(用 static 修饰的方法),而抽象类是可以有静态代码块和静态方法。
- 一个类只能继承一个抽象类,而一个类却可以实现多个接口。
标记接口
最常用的继承接口是没有包含任何方法的接口。
标记接口是没有任何方法和属性的接口.它仅仅表明它的类属于一个特定的类型,供其他代码来测试允许做一些事情。
标记接口作用:简单形象的说就是给某个对象打个标(盖个戳),使对象拥有某个或某些特权。
例如:java.awt.event 包中的 MouseListener 接口继承的 java.util.EventListener 接口定义如下:
1 | package java.util; |
没有任何方法的接口被称为标记接口。标记接口主要用于以下两种目的:
- 建立一个公共的父接口:
正如EventListener接口,这是由几十个其他接口扩展的Java API,你可以使用一个标记接口来建立一组接口的父接口。例如:当一个接口继承了EventListener接口,Java虚拟机(JVM)就知道该接口将要被用于一个事件的代理方案。 - 向一个类添加数据类型:
这种情况是标记接口最初的目的,实现标记接口的类不需要定义任何接口方法(因为标记接口根本就没有方法),但是该类通过多态性变成一个接口类型。
package
为了更好地组织类,Java 提供了包机制,用于区别类名的命名空间。
包的作用
1、把功能相似或相关的类或接口组织在同一个包中,方便类的查找和使用。
2、如同文件夹一样,包也采用了树形目录的存储方式。同一个包中的类名字是不同的,不同的包中的类的名字是可以相同的,当同时调用两个不同包中相同类名的类时,应该加上包名加以区别。因此,包可以避免名字冲突。
3、包也限定了访问权限,拥有包访问权限的类才能访问某个包中的类。
Java 使用包(package)这种机制是为了防止命名冲突,访问控制,提供搜索和定位类(class)、接口、枚举(enumerations)和注释(annotation)等。
包语句的语法格式为:package pkg1[.pkg2[.pkg3…]];
例如,一个Something.java 文件它的内容
1 | package net.java.util; |
那么它的路径应该是 net/java/util/Something.java 这样保存的。 package(包) 的作用是把不同的 java 程序分类保存,更方便的被其他 java 程序调用。
一个包(package)可以定义为一组相互联系的类型(类、接口、枚举和注释),为这些类型提供访问保护和命名空间管理的功能。
以下是一些 Java 中的包:
java.lang-打包基础的类
java.io-包含输入输出功能的函数
开发者可以自己把一组类和接口等打包,并定义自己的包。而且在实际开发中这样做是值得提倡的,当你自己完成类的实现之后,将相关的类分组,可以让其他的编程者更容易地确定哪些类、接口、枚举和注释等是相关的。
由于包创建了新的命名空间(namespace),所以不会跟其他包中的任何名字产生命名冲突。使用包这种机制,更容易实现访问控制,并且让定位相关类更加简单。
创建包
创建包的时候,你需要为这个包取一个合适的名字。之后,如果其他的一个源文件包含了这个包提供的类、接口、枚举或者注释类型的时候,都必须将这个包的声明放在这个源文件的开头。
包声明应该在源文件的第一行,每个源文件只能有一个包声明,这个文件中的每个类型都应用于它。
如果一个源文件中没有使用包声明,那么其中的类,函数,枚举,注释等将被放在一个无名的包(unnamed package,默认应该是放到java.lang包)中。
import 关键字
为了能够使用某一个包的成员,我们需要在 Java 程序中明确导入该包。
在 Java 中,import 关键字用于导入其他类或包中定义的类型,以便在当前源文件中使用这些类型。
import 关键字用于引入其他包中的类、接口或静态成员,它允许你在代码中直接使用其他包中的类,而不需要完整地指定类的包名。
在 java 源文件中 import 语句必须位于 Java 源文件的头部,其语法格式为:
import package1[.package2…].(classname|*);
import 语句位于 package 语句之后:
1 | // 第一行非注释行是 package 语句 |
如果在一个包中,一个类想要使用本包中的另一个类,那么该包名可以省略。
可以使用 import语句来引入一个特定的类:
import com.runoob.MyClass;
这样,你就可以在当前源文件中直接使用 MyClass 类的方法、变量或常量。
也可以使用通配符 * 来引入整个包或包的子包:
import com.runoob.mypackage.*;
这样,你可以导入 com.runoob.mypackage 包中的所有类,从而在当前源文件中使用该包中的任何类的方法、变量或常量。注意,使用通配符 * 导入整个包时,只会导入包中的类,而不会导入包中的子包。
在导入类或包时,你需要提供类的完全限定名或包的完全限定名。完全限定名包括包名和类名的组合,以点号 . 分隔。
1 | import java.util.ArrayList; // 引入 java.util 包中的 ArrayList 类 |
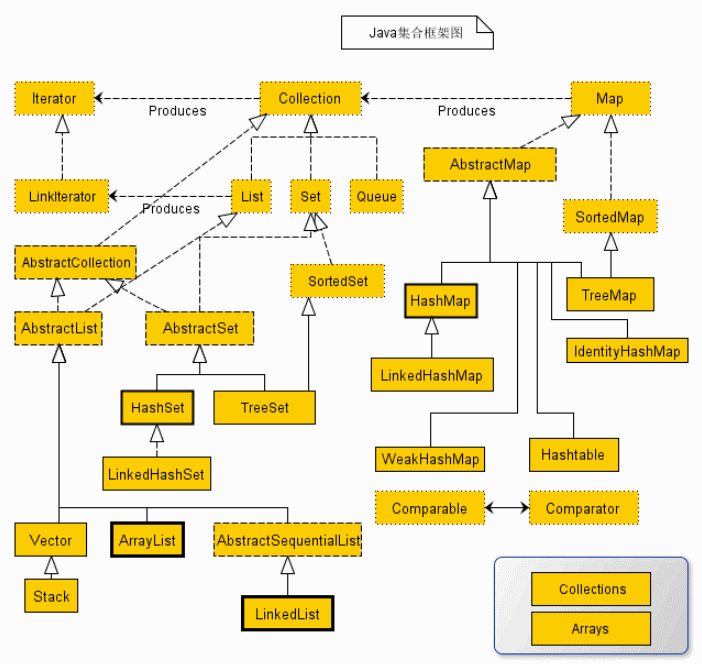
Java 集合框架
实线继承 虚线实现
Java ArrayList
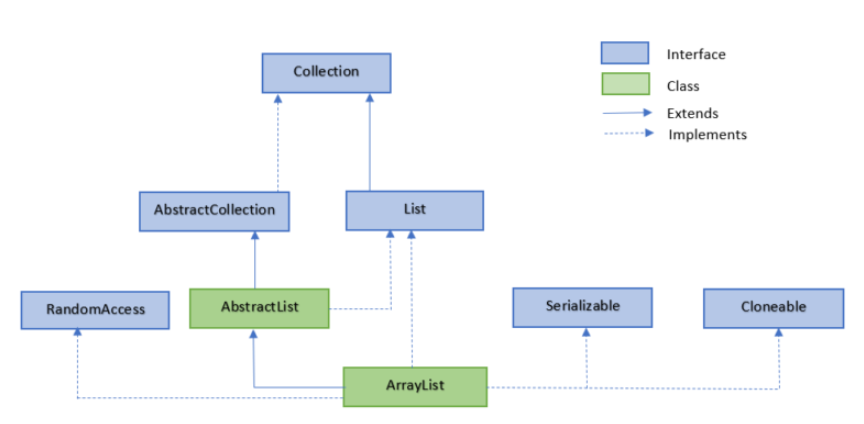
ArrayList 类是一个可以动态修改的数组(当数组用就可以了),与普通数组的区别就是它是没有固定大小的限制,我们可以添加或删除元素。
ArrayList(数组列表) 继承了 AbstractList ,并实现了 List 接口。
1 | import java.util.ArrayList; // 引入 ArrayList 类 |
E: 泛型数据类型,用于设置 objectName 的数据类型,只能为引用数据类型(对立的是普通变量)。也就是E是由类定义的对象变量,即ArrayList 中的元素实际上是对象。
objectName: 对象名。
1 | import java.util.ArrayList; |
如果我们要存储其他类型,而 <E> 只能为引用数据类型,这时我们就需要使用到基本类型的包装类。
基本类型对应的包装类表如下:
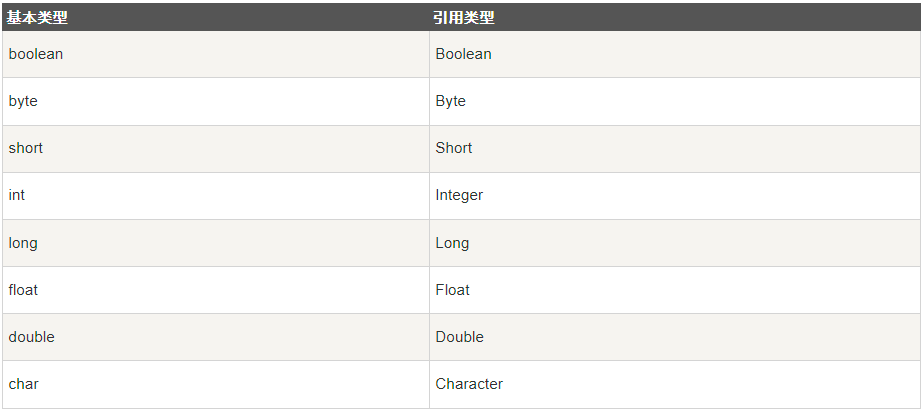
Collections 类(算法类)也是一个非常有用的类,位于 java.util 包中,提供的 sort() 方法可以对字符或数字列表进行排序。
1 | import java.util.Collections; // 引入 Collections 类 |
1 | add() 将元素插入到指定位置的 arraylist 中 |
集合与数组类似,是一种容器,用于装数据。
数组的特点:
数组定义完成并启动后,类型确定,长度固定。
问题:在个数不确定,且要进行增删数据操作时,数组是不太合适的。
集合的特点:
集合的大小不固定,启动后可以动态变化,类型也可以选择不固定。
集合非常适合做元素个数不确定,且要进行增删操作的业务场景。
集合提供了许多丰富好用的功能,而数组的功能很单一。
ArrayList集合的对象添加与获取:
ArrayList是集合的一种,它支持索引。
.add()返回值为boolean,一般不会添加失败,因此我们一般不会注意它的返回值。 System.out.println(list)会直接输出集合内容,而不是地址
1 | //创建ArrayList集合对象 |
ArrayList<E>就是一个泛型,可以在编译阶段约束集合对象,只能操作某种数据类型。
ArrayList<String>:此集合只能操作字符串类型的元素。ArrayList<Integer>:此集合只能操作整数类型的元素。
注意:集合中只能存储引用类型,不支持基本数据类型。ArrayList<Integer>不能填<int>。
代码规范:使用泛型来定义和使用集合
1 | ArrayList<String> list = new ArrayList<String>(); |
ArrayList常用API、遍历
.get()//获取某个索引位置处的元素值
.size()//获取集合大小
.remove()//删除某个索引位置处的值,并返回被删除的值
.set()//修改某个索引位置的值,会返回修改前的值
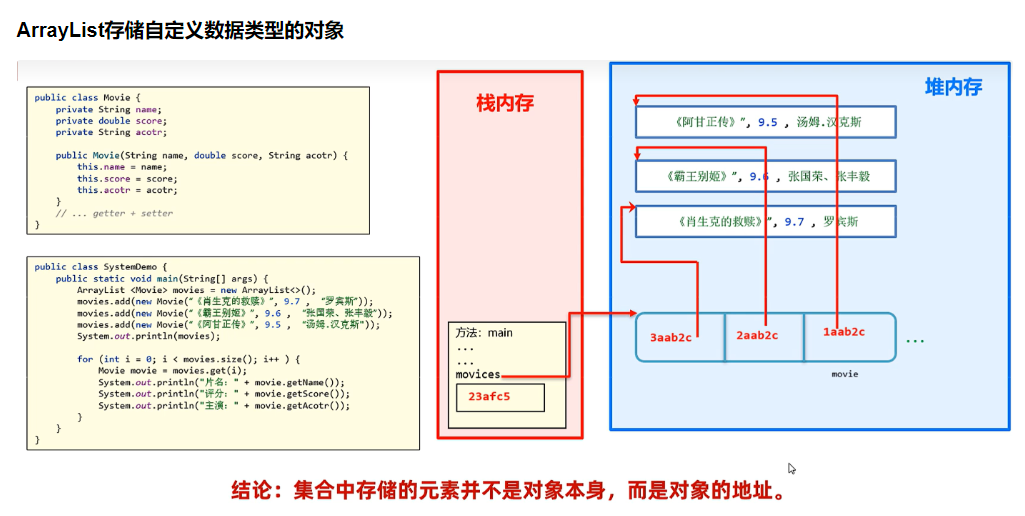
集合中存储的元素并不是对象本身,而是对象地址。
如果用println直接打印集合那输出的就是地址,后面分析println的时候会讲。
1 | class Movie { |
学生信息系统的数据搜索
需求:
后台程序需要存储学生信息并展示,然后要提供按照学号搜索的功能。
分析:
定义Student类,定义ArrayList存储学生对象信息,并遍历展示出来。
提供一个方法,可以接收ArrayList集合,和要搜索的学号,返回搜索到的学生对象信息,并展示。
使用死循环,让用户可以不停的搜索。
1 | public class Student { |
Java LinkedList
链表(Linked list)是一种常见的基础数据结构,是一种线性表,但是并不会按线性的顺序存储数据,而是在每一个节点里存到下一个节点的地址。
以下情况使用 ArrayList :
频繁访问列表中的随机元素(只是ArrayList更高效,不是说LinkedList不能按索引访问元素,LinkedList有方法 get(i))。
只需要在列表末尾进行添加和删除元素操作。
以下情况使用 LinkedList :
你需要通过循环迭代来访问列表中的某些元素。
需要频繁的在列表开头、中间、末尾等位置进行添加和删除元素操作。
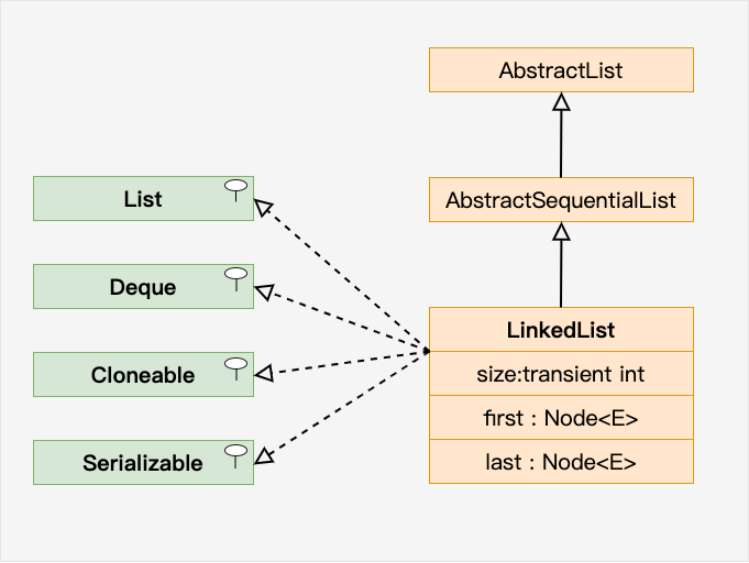
LinkedList 继承了 AbstractSequentialList 类。
LinkedList 实现了 Queue 接口,可作为队列使用。
LinkedList 实现了 List 接口,可进行列表的相关操作。
LinkedList 实现了 Deque 接口,可作为队列使用。
LinkedList 实现了 Cloneable 接口,可实现克隆。
LinkedList 实现了 java.io.Serializable 接口,即可支持序列化,能通过序列化去传输。
(实箭头继承类,虚箭头实现;接口)
1 | // 引入 LinkedList 类 |
1 | LinkedList<String> sites = new LinkedList<String>(); |
1 | public boolean add(E e) 链表末尾添加元素,返回是否成功,成功为 true,失败为 false。 |
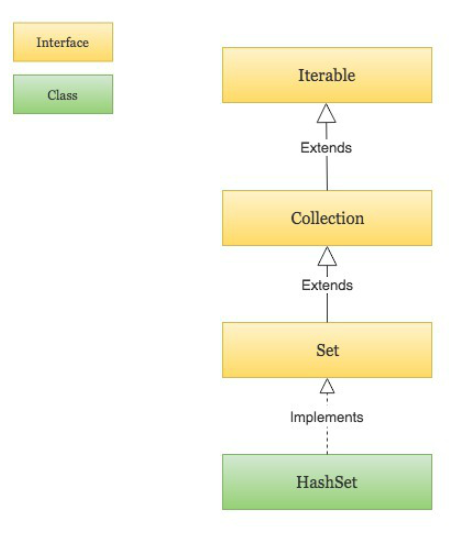
Java HashSet
HashSet 基于 HashMap 来实现的,是一个不允许有重复元素的集合。
HashSet 允许有 null 值。
HashSet 是无序的,即不会记录插入的顺序。
HashSet 不是线程安全的, 如果多个线程尝试同时修改 HashSet,则最终结果是不确定的。 您必须在多线程访问时显式同步对 HashSet 的并发访问。
HashSet 实现了 Set 接口。
HashSet 中的元素实际上是对象,一些常见的基本类型可以使用它的包装类。
1 | import java.util.HashSet; // 引入 HashSet 类 |
Java HashMap
Map 遍历
Entry
由于Map中存放的元素均为键值对,故每一个键值对必然存在一个映射关系。
Map中采用Entry内部类来表示一个映射项,映射项包含Key和Value (我们总说键值对键值对, 每一个键值对也就是一个Entry)
Map.Entry里面包含getKey()和getValue()方法
entrySet
entrySet是 java中 键值对的集合,Set里面的类型是Map.Entry,一般可以通过map.entrySet()得到。
entrySet实现了Set接口,里面存放的是上面所说的键值对也就是一个Map.Entry。
1 | HashMap<Integer, Integer> map = new HashMap<>(); |
也可以试着用map.entrySet的迭代器 iterator
1 | Iterator<Map.Entry<Integer, Integer>> it = map.entrySet().iterator(); |
keySet
还有一种是keySet, keySet是键的集合,Set里面的类型即key的类型
1 | Set<String> set = map.keySet(); |
Java Object 类
Java Object 类是所有类的父类,也就是说 Java 的所有类都继承了 Object,子类可以使用 Object 的所有方法。
Object 类位于 java.lang 包中,编译时会自动导入,我们创建一个类时,如果没有明确继承一个父类,那么它就会自动继承 Object,成为 Object 的子类。
Object 类可以显式继承,也可以隐式继承,以下两种方式是一样的:
1 | 显式继承: |
栈 队列 优先队列
栈 队列 用 ArrayDeque 比较好,如:Queue<TreeNode> queue = new ArrayDeque<TreeNode>();
Java 程序员,别用 Stack?!
理解了接口含义,就是封装。
原来stack继承vector,继承了多余的方法,破坏了封装性。
当然,用Dueue<Integer> stk = new ArrayDeque<Integer>();也有这个问题,但已经是历史遗留问题,无解了。
优先队列有 PriorityQueue
各种类型相互转化问题
Java 中数组即对象。
只要跟集合交流的数组都是引用类型的数组。因为集合本身不与基本类型打交道。如果你要交流,他们的包装类型就是交流的桥梁。而包装类型和基本类型数组之间的转换就要你自己写循环体去一个一个转型了。
char[] 与 String 互相转换
1 | char[] chars = str.toCharArray(); //通过toCharArray方法 |
包装类数组 与 List 互相转换
copyOfRange是输入java.util包中的Arrays类的静态内部方法,可以被类直接调用。下面以int[]型传递参数为例,来测试其用法。
copyOfRange(int []original,int from,int to),original为原始的int型数组,from为开始角标值,to为终止角标值。(其中包括from角标,不包括to角标。即处于[from,to)状态)
包装类数组转换为List
再次强调List只能和包装类数组之间进行转换,因为集合只支持对包装类进行操作。
如果非要进行基本类型数字与List之间的转换(Java对包装和解包装都是自动进行的,包装类数据其实也可以直接用,区别并不太大),那么必须通过包装类数组这个媒介。
1 | Character[] chars = {'1','2','3','4','5','6','7','8','9'}; |
List转换为包装类数组
1 | public static void listToArray(){ |
关于源码的实现,就要具体看是那种List了,从List接口中,我们也能知道一些信息:<T> T[] toArray(T[] a); //参数是什么类型就返回什么类型的数组
String 与 List 互相转换
String转换为List
原理就是首先将String转换成String[]数组,再通过上面讲过的包装类数组转换为List。
注意这里的str.split(“”) 方法。
1 | public static void stringToList (String str){ |
所以有两个步骤是:
首先要将String转换为包装类型(如Character[])或String[]数组
再把包装类型数组转换成List。
注意:
要注意的是,通常所说的String转换成List,方式之一通常是通过split方法转换成String[]数组。
如果你想将str.toCharArray转换成char[](上面讲过了),再转换为List,这就比较麻烦了,因为你需要先得把char[]基本类型转换成Character[]。
List转换为String
1 | public static void listToString(){ |
List通过String的join方法直接转换为String,通过””作为分隔符,就相当于字符之间没有分隔符。
List和Set互相转换
List转换为Set
1 | public static void listToSet(){ |
Set转换为List
1 | public static void setToList(){ |
所以List集合和Set集合之间只要类型参数相同,既可以通过构造函数互相转换。
String 与 Set 互相转换
String转换为Set
1 | public static void stringToSet(){ |
方式一有三个步骤:
String转换为String[]数组 或包装类型数组(如Character[])
将数组转换为List,
再使用Arrays或Collections工具类将list转换为Set。
方式二有两个步骤
String转换为String[]数组 或包装类型数组(如Character[])
使用Collections工具类将数组转换为Set。
Set转换为String
1 | public static void setToString(){ |
只需要一个步骤,即:
使用String的join方法把集合转换为String。
包装类数组 与 Set 互相转换
Set 与 List 同理, 也只与包装类型打招呼。
包装类数组转换为Set
1 | public static void arrayToSet(){ |
两种方式,同样是受到不同工具类的影响。
第一种方式的两个步骤:
数组通过Arrays或Collections工具类(也是Collections.addAll,上面讲过)转换为List
再把list转换为set
第二种方式的一个步骤:
通过Collections直接将数组转换为Set
Set转换为包装类数组
1 | public static void setToArray(){ |
集合转为数组的方式也很简单,通常都是集合.toArray(T[] t)。
Java8中数组(引用类型)、String、List、Set之间的相互转换问题
Arrays.asList使用指南
List 是一种很有用的数据结构,如果需要将一个数组转换为 List 以便进行更丰富的操作的话,可以这么实现:
1 | String[] myArray = { "Apple", "Banana", "Orange" }; |
将需要转化的数组作为参数,或者直接把数组元素作为参数,都可以实现转换。
下面看一下极易出现的错误及相应的解决方案:
错误一 将原生数据类型数据的数组作为参数
来看一下asList 方法的签名:public static <T> List<T> asList(T... a)
注意:参数类型是 T ,根据官方文档的描述,T 是数组元素的 class。
如果你对反射技术比较了解的话,那么 class 的含义想必是不言自明。我们知道任何类型的对象都有一个 class 属性,这个属性代表了这个类型本身。原生数据类型,比如 int,short,long等,是没有这个属性的,具有 class 属性的是它们所对应的包装类 Integer,Short,Long。
因此,这个错误产生的原因可解释为:asList 方法的参数必须是对象或者对象数组,而原生数据类型不是对象——这也正是包装类出现的一个主要原因。当传入一个原生数据类型数组时,asList 的真正得到的参数就不是数组中的元素,而是数组对象本身!此时List 的唯一元素就是这个数组。
解决方案:使用包装类数组
如果需要将一个整型数组转换为 List,那么就将数组的类型声明为 Integer 而不是 int。
1 | public class Test { |
错误二 试图修改 List 的大小
我们知道 List 是可以动态扩容的,因此在创建一个 List 之后最常见的操作就是向其中添加新的元素或是从里面删除已有元素,但这样的操作都会出现异常:java.lang.UnsupportedOperationException。
仔细阅读官方文档,你会发现对 asList 方法的描述中有这样一句话:返回一个由指定数组生成的固定大小的 List。
按道理 List 本就支持动态扩容,那为什么偏偏 asList 方法产生的 List 就是固定大小的呢?如果要回答这一问题,就需要查看相关的源码。Java 8 中 asList 方法的源码如下:
1 | public static <T> List<T> asList(T... a) { |
这个内部类也叫 ArrayList ,这个内部类继承了 AbstractList 却没有重写add方法,所以会抛出异常:java.lang.UnsupportedOperationException(在AbstractList中对add方法天然就会抛出此异常,与源码中的final无关。对于一个final变量,如果是基本数据类型的变量,则其数值一旦在初始化之后便不能更改;如果是引用类型的变量,则在对其初始化之后便不能再让其指向另一个对象。这里是第二种情况)。
而我们平时常用的java.util.ArrayList里的ArrayList重写了add方法,所以是可以添加删除元素的。
因此:asList 方法返回的确实是一个 ArrayList ,但这个 ArrayList 并不是 java.util.ArrayList ,而是 java.util.Arrays 的一个内部类。
所以,List<String> myList = Arrays.asList(myArray)可不能写成ArrayList<String> myList = Arrays.asList(myArray)。
解决方案:创建一个真正的 ArrayList
既然我们已经知道之所以asList 方法产生的 ArrayList 不能修改大小,是因为这个 ArrayList 并不是“货真价实”的 ArrayList ,那我们就自行创建一个真正的 ArrayList :
1 | public class Test { |
在上面这段代码中,我们 new 了一个 java.util.ArrayList ,然后再把 asList 方法的返回值作为构造器的参数传入,最后得到的 myList 自然就是可以动态扩容的了。
用自己的方法实现数组到 List 的转换
有时,自己实现一个方法要比使用库中的方法好。鉴于 asList 方法有一些限制,那么我们可以用自己的方法来实现数组到 List 的转换:
1 | public class Test { |
这样做的话代码相对冗长,但是不管有什么特别的需求都可以自己来实现,
ArrayList 转 String
ArrayList 实现了 List 接口,自然也能使用List.toString()方法获得带中括号的字符串,如:
1 | ArrayList<Character> chars = new ArrayList<>(); |
想要获得不带括号的,方法有:
- 遍历列表并创建字符串将
1
2
3
4
5
6StringBuilder builder = new StringBuilder(arrayList.size());
for(Character ch: arrayList)
{
builder.append(ch);
}
System.out.println(builder.toString()); // 123StringBuilder的容量设置为列表大小是一个重要的优化。如果不这样做,一些append调用可能会触发Builder内部调整大小。
另外,toString()返回一个人类可读的ArrayList内容格式。不值得花时间从其中过滤掉不必要的字符。它的实现明天可能会改变,你将不得不重写你的过滤代码。
2. 用正则表达式直接替换’[]’,’,’为空字符
数组打印问题
System.out.println()
1 | System.out.println(var); |
原因如下:
方法 System.out.println() 通过调用 String.valueOf() 把入参对象转换为一个字符串。
这里注意到: char[] 转化为 String 可以通过String str = String.valueOf(char[] chars)语句,所以System.out.println()是可以成功打印字符数组char[]的,但是其他类型的数组都是不可以的。
如果我们查看 String.valueOf() 方法的实现,会看到如下的代码:
1 | public static String valueOf(Object obj) { |
如果入参是 null 会返回空, 其它情况会调用 obj.toString()。 最后 System.out.println() 调用 toString() 方法打印出了字符串。
如果对象的类没有重写 Object.toString() 方法并实现,那就会调用超类 Object 的 Object.toString() 方法。
Object.toString() 返回的是 getClass().getName()+****‘@’****+Integer.toHexString(hashCode())。 简化格式为:“class name @ object’s hash code”。
上文中输出的内容是 [I@74a14482, [ 表示数组, I 表示 int 数据类型(数组的数据类型)。 74a14482 是数组的无符号十六进制 hash 值。
当创建自定义类时,重写 Object.toString() 方法是最佳的实践。
for & for-each & Arrays.toString()
用传统for循环或者for each循环for(int a:array);
或利用Array类中的toString方法(静态static方法,通过类名Array调用)Array.toString(var),返回一个包含数组元素的字符串,需要注意这些元素被放置在中括号内,并用逗号分开。
1 | int[] intArray = {1,2,3,4,5}; |
System.out.println(intArray); 是不行的,这样打印是的是数组的首地址。
对于二维数组也对应这三种方法,定义一个二维数组:
1 | int[][]magicSquare = |
Java实际没有多维数组,只有一维数组,多维数组被解读为”数组的数组”,例如二维数组magicSquare是包含{magicSquare[0],magicSquare[1],magicSquare[2]}三个元素的一维数组,magicSqure[0]是包含{16,3,2,13}四个元素的一维数组,同理magicSquare[1],magicSquare[2]也一样。
1 | // 第三种方法(Arrays.toString) |
对于引用类型的数组,确保重写该引用类的 Object.toString() 方法。
1 | public class Test { |
此方法不适用于多维数组。在多维数组中, Object.toString() 会打印数组元素的内存地址而不是内容。
Arrays.deepToString() & Arrays.asList()
Arrays.deepToString() 返回数组“深层内容”的字符串形式。
基本类型多维数组示例:
1 | // creating multidimensional array |
对于引用类型数组,通过递归调用 Arrays.deepToString() 方法将其转换为字符串。
Arrays.asList() 方法返回固定大小(数组长度)的列表。
因为 List 是对象列表集合,与列表打交道的数组都要求是包装类型的数组。
1 | Integer[] intArray = {2,5,46,12,34}; |
Java 调用 Arrays.asList(intArray).toString() 。其内部实现是列表(list)元素调用了 toString() 方法(同样会带有括号),注意,ArrayList实现了List接口,自然也拥有 toString() 方法,同样会带有括号。
NOTE: 不能使用此方法打印多维数据。
Java Iterator interface & Java Stream API
Iterator 接口和 for-each 循环类似,可以使用 Iterator 接口遍历数组元素并打印。
Collection 调用 iterator() 方法创建 Iterator 对象。Iterator 对象可以遍历该集合的元素。
1 | Integer[] intArray = {2,5,46,12,34}; |
Stream API 用于处理对象集合。 流是一个对象序列。流不能改变原始数据结构,它仅根据请求的操作提供结果。
借助终端操作 forEach() 可以遍历流的每个元素。
1 | Integer[] intArray = {2,5,46,12,34}; |
参考资料
(Java 数组的打印方式)[https://www.freecodecamp.org/chinese/news/java-array-methods-how-to-print-an-array-in-java/]
Arrays算法类
Arrays.sort
1 | int[][] arr = new int[n][2]; |
将对arr按第0列降序排序,太抽象了,写个比较器对新手多友好。
可以这样理解,原本默认是Arrays.sort(arr, (a, b) -> (a[0] - b[0]) )将会升序排列,比较的根据是 (a[0] - b[0]) 返回 0、1、-1。改成(b[0] - a[0])之后就会按按第0列降序排列。
Arrays.sort(T[],Comparator<? super T>c)
自定义比较器 Comparator ,可以为对象实现降序排序,上面的二维数组中的每一个数组其实就可以当作是一个对象,也可以用来为自定义类对象实现排序。
Arrays.sort()对二维数组进行排序:
int [][]a = new int [5][2];
//定义一个二维数组,其中所包含的一维数组具有两个元素
对于一个已定义的二位数组a进行如下规则排序,首先按照每一个对应的一维数组第一个元素进行升序排序(即a[][0]),若第一个元素相等,则按照第二个元素进行升序排序(a[][1])。(特别注意,这里的a[][0]或者a[][1]在java中是不能这么定义的,这里只是想说明是对于某一个一维数组的第0或1个元素进行排序)
1 | Arrays.sort(a, new Comparator<int[]>() { |
其中o1[1]-o2[1]表示对于第二个元素进行升序排序如果为o2[1]-o1[1]则表示为降序。
Arrays.sort(arr, (a, b) -> b[0] - a[0]);这个应该是lambda表达式的写法,等效于Arrays.sort(arr, (int[] a, int[] b) -> b[0] - a[0]);
参考自 二维数组排序
Comparator<? super T>
Comparator<? super T>的实现涉及到泛型:
实现降序排序
1 | import java.util.Comparator; |
<? super T> 的意思是比较类型可以是T或者它的父类型。为什么准许父类型。答案是:
这种方法准许为所有的子类使用相同的比较器,也就是多态。
1 | import java.util.Arrays; |
第一列降序,第二列升序
1 | int[][] people |
Java 序列化
Java 序列化是一种将对象转换为字节流的过程,以便可以将对象保存到磁盘上,将其传输到网络上,或者将其存储在内存中,以后再进行反序列化,将字节流重新转换为对象。
序列化在 Java 中是通过 java.io.Serializable 接口来实现的,该接口没有任何方法,只是一个标记接口,用于标识类可以被序列化。
当你序列化对象时,你把它包装成一个特殊文件,可以保存、传输或存储。反序列化则是打开这个文件,读取序列化的数据,然后将其还原为对象,以便在程序中使用。
序列化是一种用于保存、传输和还原对象的方法,它使得对象可以在不同的计算机之间移动和共享,这对于分布式系统、数据存储和跨平台通信非常有用。
实现 Serializable 接口: 要使一个类可序列化,需要让该类实现 java.io.Serializable 接口,这告诉 Java 编译器这个类可以被序列化,例如:
1 | import java.io.Serializable; |
反射
反射是框架设计的灵魂
使用的前提条件:必须先得到代表字节码文件的Class类对象,其用于表示.class文件(字节码)
JAVA反射机制是在运行状态中,对于任意一个类,都能够知道这个类的所有属性和方法;对于任意一个对象,都能够调用它的任意一个方法和属性;这种动态获取类的信息以及动态调用对象的方法的功能称为java语言的反射机制。
要想解剖一个类,必须先要获取到该类的字节码文件对象。而解剖使用的就是Class类(就叫Class类,用于定义类的关键字 class 是小写的)中的方法,所以先要获取到每一个字节码文件对应的Class类对象。
以上的总结就是什么是反射
反射就是把java类中的各种成分映射成一个个的Java对象
利用反射技术可以对一个类进行解剖,把个个组成部分映射成一个个对象。
写的很好,学了很多反射基础,认真看完了。
注解
java注解是在JDK5时引入的新特性,鉴于目前大部分框架(如Spring)都使用了注解简化代码并提高编码的效率,因此掌握并深入理解注解对于一个Java工程师是来说是很有必要的事。
Java所有注解都继承了Annotation接口,也就是说 Java使用Annotation接口代表注解元素,该接口是所有Annotation类型的父接口。同时为了运行时能准确获取到注解的相关信息,Java在java.lang.reflect 反射包下新增了AnnotatedElement接口,它主要用于表示目前正在 VM 中运行的程序中已使用注解的元素,通过该接口提供的方法可以利用反射技术地读取注解的信息,如反射包的Constructor类、Field类、Method类、Package类和Class类都实现了AnnotatedElement接口。
深入理解Java注解类型(@Annotation)
讲的不错,认真看完了。
泛型
泛型与继承息息相关,特别是继承中的向上向下转型,具体的我在继承中已经认真学习过了。
以下来自博客一文读懂Java泛型中的通配符 ?
首先学习下泛型中常见的 ? 通配符。当然在学习它是什么之前,我们要知道它是为了解决什么问题而产生的。
(举个例子)当你要写一个通用的方法,它可以操作对含有某些特定类型元素的集合统一操作。
想象 A 是 B、C 父类, List<A>、 List<B>、 List<C> 是对应的集合,我想实现某些函数能统一对这些 集合 进行访问读写,而不是每个集合写一个相同功能的函数,也即之前提过的向上向下转型。
泛型通配符 ?
泛型通配符可以解决这个问题。泛型通配符主要针对以下两种需求:
- 从一个泛型集合里面读取元素
- 往一个泛型集合里面插入元素
这里有三种方式定义一个使用泛型通配符的集合
1 | List<?> listUknown = new ArrayList<A>(); |
无限定通配符 ?
1 | public void processElements(List<?> elements){ |
List<?> 可以指持有任意数据类型的集合,但只能指一个,比如就是List<A>,也可以是List<B>,或者List<C>,但我不知道是哪个,所以只能对这个集合读,并且只能把读取到的元素当成 Object 实例来对待(向上转型,因为 Object 是所有类的父类)
上界通配符(? extends)
List<? extends A> 代表的是一个可以持有 A及其子类(如B和C)的实例的List集合。
当集合所持有的实例是A或者A的子类的时候,此时从集合里读出元素并把它强制转换为A是安全的。
1 | public void processElements(List<? extends A> elements){ |
这个时候你可以把List<A>,List<B>或者List<C>类型的变量作为参数传入processElements()方法之中。
processElements()方法仍然是不能给传入的list插入元素的(比如进行list.add()操作),因为你不知道list集合里面的元素是什么类型(A、B还是C等等)。
下界通配符(? super)
List<? super A> 的意思是List集合 list,它可以持有 A 及其父类的实例。
当你知道集合里所持有的元素类型都是A及其父类的时候,此时往list集合里面插入A及其子类(B或C)是安全的。
1 | public static void insertElements(List<? super A> list){ |
你可以往insertElements传入List<A>或者一个持有A的父类的list(这也是 super 的含义)。
因为此时我们可以确定传入的list集合里的元素是A及其父类,所以我们往这个集合里插入A及其子类是兼容的(向上转型)。
同样的,这个集合也不能随便读,里面的元素可能是 A 类也可能是 A 的父类,读取方法很简单,找出集合里元素的共同父类并将集合元素转化为这个类型,之后才能用,或者直接转化为 Object类,上面的list<? extends A>可以转换为A的原因是他知道集合里的元素的类型要么是A要么是A的子类,他们都可以转换为A。
java 泛型详解-绝对是对泛型方法讲解最详细的,没有之一 认真看完了,基本都能理解,有讲到上面提到的通配符的应用,大差不差。
泛型有三种使用方式,分别为:泛型类、泛型接口、泛型方法。
编译之后程序会采取去泛型化的措施。也就是说Java中的泛型只在编译阶段有效。在编译过程中,正确检验泛型结果后,会将泛型的相关信息擦除,并且在对象进入和离开方法的边界处添加类型检查和类型转换的方法。也就是说,泛型信息不会进入到运行时阶段。
异常
java(3)-深入理解java异常处理机制
详解java异常的文章,需要的时候再来看吧。
Java 多线程与并发
Maven 引入外部依赖
pom.xml 的 dependencies 列表列出了我们的项目需要构建的所有外部依赖项。
要添加依赖项,我们一般是先在 src 文件夹下添加 lib 文件夹,然后将你工程需要的 jar 文件复制到 lib 文件夹下。具体做法为:
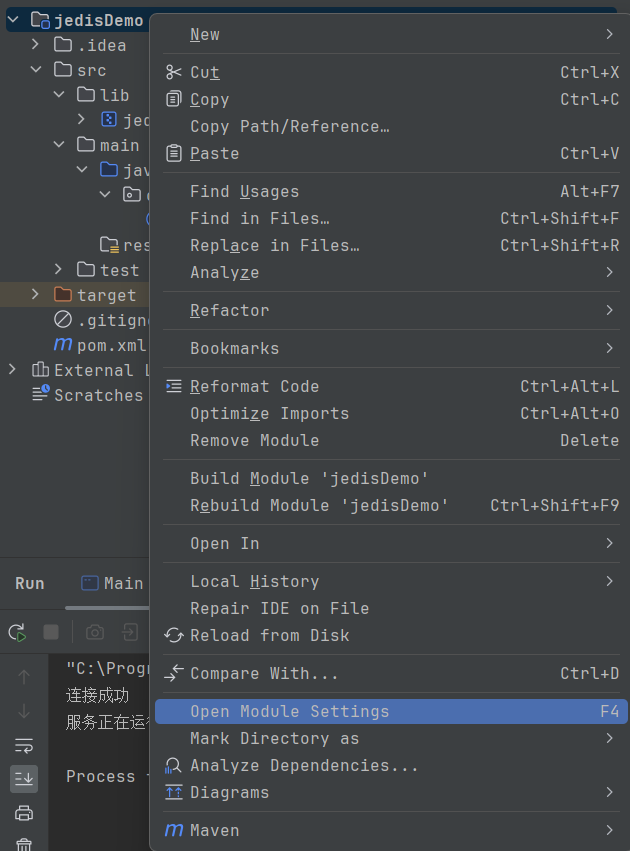
项目左边栏右键空白处之后选择: Open Module Settings,点击 + 号选择Jars or Directories选项并导入之前创建的 lib 文件夹即可完成配置。
第三方库一般都会给出配置的 pom 代码。
然后添加以下依赖到 pom.xml 文件中:
1 | <dependencies> |
如果用 systemPath 的话是配置本地依赖,这种情况应该不需要配置lib文件夹,第二种配置方法是需要的。