千磨万击还坚劲,任尔东西南北风
MySQL
探究并发插入 二级 uk 记录 导致的死锁问题
结合实践来理解理论,案例可复现。
1 | # 建表 |

1、我们尝试插入uk 冲突的数据 insert into t values(null, 50, 1);,肯定会执行失败,此时查看事务上锁状态 select ENGINE_TRANSACTION_ID, index_name, lock_type, lock_mode, LOCK_STATUS, lock_data from performance_schema.data_locks;:

可以看到上了两个锁,都很奇怪,一个个分析。
在 uk=50 上加的 S 型临键锁
有一些理论基础是,二级uk插入 record 的时候是分成了两个阶段:
- 判断当前的物理记录上是否有冲突的record(delete-marked 是不冲突,即允许走到第二步)
- 如果没有冲突, 那么可以执行插入操作
InnoDB 的“免锁”插入优化 (Lock-free Insert)
“判断 -> 插入”两个阶段之间需要锁,是完全正确的逻辑。但 InnoDB 实现这个“锁”的方式非常聪明,它不一定使用我们通常所说的、会持续到事务结束的重量级 Lock。
在REPEATABLE READ或READ COMMITTED隔离级别下,当向一个带有二级唯一索引的表插入一条新记录,并且没有发生唯一键冲突时,InnoDB会这样做:
快速检查,但不加间隙锁:
InnoDB 会首先检查这个即将插入的键值是否存在。在执行这个检查时,它并不会像 SELECT … FOR UPDATE 那样,预先加上一个会持续整个事务的间隙锁或 Next-Key Lock。
使用 Latch 保护内存:
在检查和插入的瞬间,它会使用一种比 Lock 更轻量级的并发控制机制——Latch (闩锁) 来保护 B+Tree 的索引页在内存中的数据结构。Latch 的作用时间极短,就是为了防止在内存中多个线程同时修改同一个索引页导致数据损坏。
执行插入并依赖新纪录的锁:
在 Latch 的保护下,InnoDB 确认没有重复键,然后将新记录插入到二级索引的 B+Tree 页面中。
一旦记录被插入,这条新记录本身就会带有一个排他记录锁 (Exclusive Record Lock, X-Lock)。这个锁是隐式的,会持续到事务提交。
操作完成后,Latch 会被立刻释放。
这个优化为什么是可行的?
在 阶段1 和 阶段2 之间,虽然没有长期的 Gap Lock,但有短期的 Latch 保护,足以防止并发的内存操作冲突。
一旦 阶段2 完成,新记录上的 X-Lock 就成了新的“守护者”。任何其他想插入完全相同键值的事务,在做冲突检查时,就会遇到这个 X-Lock 并被阻塞。
这种方式避免了为一个简单的 INSERT 操作锁定一大片间隙,极大地提高了并发插入的性能。如果两个事务要插入同一个间隙的不同位置(比如一个插 uk=20,另一个插 uk=30),它们将不会互相阻塞。
所以测试时看不到间隙锁,正是因为触发了这项优化。
那什么时候会看到锁呢?
这项优化虽好,但它只适用于“简单无冲突”的场景。一旦情况变得复杂,InnoDB 就会退回到更保守、更安全的加锁方式。
- 发生唯一键冲突时
这是最常见的情况。如果你的 INSERT 语句确实遇到了一个重复键(即使那个键是被另一个未提交的事务标记为删除的),InnoDB 就不能再使用上述的“免锁”优化了。
此时,InnoDB 会在它找到的那个冲突的二级索引记录上,加上一个共享型的 Next-Key Lock (S-Lock)。
这个 S-Lock 的目的是等待持有该记录(或标记删除该记录)的那个事务提交或回滚。
这个 Next-Key Lock 包含了间隙锁,因此在这种情况下,你就能观察到锁的存在了。它会阻止其他事务在你等待期间,在冲突记录附近插入新的数据。
总结
对于二级唯一索引的无冲突插入,InnoDB 出于性能考虑,通常不会设置长事务周期的间隙锁。它依赖于短期 Latch 和新纪录的 隐式 X-Lock 来保证唯一性。
这个优化有其适用边界。一旦发生唯一键冲突,InnoDB 就会毫不犹豫地使用共享的 Next-Key Lock (包含间隙锁) 这种更强的锁来保证事务的隔离性和数据一致性,防止幻读。
进一步的,上面发生唯一键冲突时还有细节:
为什么唯一键冲突 如果是因为遇到确实存在的记录,会在它上面加 S 临键锁,而如果是遇到 标记删除的记录,不仅在该记录上加,还会在该记录 uk 排序后面的一条记录上也加一个 S 临键锁?为什么有这个区别?
简单的说,这个区别的根源在于:
一个真实存在的记录是一个确定的状态,而一个被标记删除的记录是一个不确定的、模糊的状态,为了应对这种不确定性,数据库必须采用更强、范围更大的锁来保护数据的一致性。
场景一:冲突的记录是“真实存在”的 (Live Record)
在这种情况下,冲突的对象非常明确,就是 uk=50 这一个点。事务 B 的意图也很明确:“我需要等待 uk=50 这条记录本身的状态发生改变(比如被事务 A 删除并提交)”。
所以,InnoDB 只需要在 uk=50 这条二级索引记录上加上一个 S-Lock (共享锁)(通常是 S-Next-Key Lock,但主要作用点是记录本身)就足够了。这个锁的核心目的就是监视这个已存在的记录,等待持有该记录的 X-Lock 释放。这个锁的行为是确定的、聚焦的。
场景二:冲突的记录是“标记删除”的 (Delete-Marked Record)
因为这个“鬼魂”记录本身不是一个稳定的锁定目标,它随时可能被物理清除 (Purge)(如果清除了可能导致上的锁就不见了,所以在下一条记录也加锁)。InnoDB 需要锁住的是由于删除而产生的“真空地带”或者说“间隙”。
如何最可靠地锁住一个间隙?答案是:锁住这个间隙的边界。
所以 InnoDB 采取了以下策略:
在该记录上加锁:首先,在找到的那个被标记删除的 uk=50 记录上加上 S-Lock,这是为了等待事务 A 的结果。
在下一条记录上也加锁:这是关键一步。为了防止任何事务(包括事务 C)在这个新产生的、不稳定的间隙中插入数据(从而对事务 B 造成幻读),InnoDB 必须将这个间隙锁住。它通过在 uk=50 之后物理上存在的下一条记录(我们称之为 uk_next)上也加上一个 S-Next-Key Lock 来实现。
这个 Next-Key Lock 会锁住 uk_next 记录本身,以及它和 uk=50 之间的整个间隙。
通过锁住下一条记录,InnoDB 成功地将 uk=50 这个“可能为空”的坑以及它周围的空间全部封锁了,直到事务 A 提交或回滚,所有不确定性都消除之后,才会允许其他事务进入这片区域。
为什么用 S-Lock 来实现等待?
S-Lock(共享锁)准确地表达了事务B的意图:“我不想修改你(事务A)的这条记录,我只是想读它最终的、确定的状态。”
这允许多个像事务B这样的“等待者”(比如事务C、事务D都想插入同一个email),它们可以同时持有S-Lock来等待事务A的结果,就像大家一起在“等候室”里等。如果用 X-Lock,那么等待者之间还会互相排斥,没有必要。
所以,这个 S-Lock 本质上是一个“等待锁”或“观察锁”,它让并发的 INSERT 操作在遇到潜在冲突时,能够安全、正确地排队。

先删除 uk=50 的记录 delete from t where uk = 50;:

然后插入 uk=50 的记录 insert into t values(10, 50, 1);,区别于上面的插入语句,这条语句是能进入二阶段插入成功的,因为 uk=50 的记录已经被 delete marked 标记了,但这时上了很多意想不到的锁:

给被删的 uk=50 的记录上了 S GAP,刚插入的 uk=50 的记录上了 S GAP,被删的 uk=50 的记录的下一条记录 即 uk=70 处上了 S 临键锁。
先来看看 官方 对包含 唯一键 的 insert 语句的 pseudocode:
find the B-tree page in the secondary index you want to insert the value to
assert the B-tree page is latched
equal-range = the range of records in the secondary index which conflict with your value
if(equal-range is not empty){
release the latches on the B-tree and start a new mini-transaction
for each record in equal-range
lock gap before it, and the record itself (this is what LOCK_S does)
also lock the gap after the last(equal-range)
also (before Bug #32617942 was fixed) lock the record after last(equal-range)
once you are done with all of the above, find the B-tree page again and latch it again
}
insert the record into the page and release the latch on the B-tree page.翻译如下:
找到你想要插入值的二级索引所在的B树页。
确认该B树页已被闩锁 (latched)。
equal-range = 与待插入值冲突的二级索引记录范围。
if (equal-range 不为空) {
释放B树上的闩锁,并开启一个新的迷你事务 (mini-transaction)。
对于 equal-range 中的每一条记录:
锁定其之前的间隙 (gap) 和记录本身(这就是 LOCK_S 锁的作用)。
同时,锁定 equal-range 中最后一条记录之后的间隙。
同时(在修复 Bug #32617942 之前),还会锁定 equal-range 中最后一条记录之后的下一条记录。
完成以上所有操作后,重新定位到该B树页并再次对其进行闩锁。
}
将记录插入该页面,然后释放该B树页上的闩锁。
阶段1 和 阶段2 之间必须要有 latch(闩锁) 或者 lock 来保证原子性,否则随便就出现 uk 失效了,这里的伪代码描述的操作是通过一阶段 uk 检查后才进行的。
根据伪代码描述,当前的实现是,如果没有重复记录,也就是 equal-range 为空,那就借助 latch(Latch 是一种非常轻量级的锁,用来保护内存中的数据结构比如 B+ 树的一个页面在被多线程并发访问时不被破坏,它的持有时间通常非常短。)来实现两阶段的原子性,latch 我们是无法用 查询锁 操作看到的。
如果有重复记录(这里特指 delete-marked 的记录),开始上锁,发现上锁情况和我们执行结果基本符合,加了gap lock 以后就可以禁止其他事务在这个 gap 区间插入数据, 也就是通过 lock 来保证阶段1和阶段2的原子性。注意 uk=70 也被上了临键锁,那这样防的范围就太大了,也就是这个 issue 遇到的问题。
如果把这个next-key lock 去掉会有什么问题?
第一列是 uk,红的表示 delete-marked 的记录但是没有 purge 掉。
那么如果像官方一样把next-key lock 改成 record lock 以后, 如果这个时候插入两个record (13000, 99), (13000, 120).
第一个record 在unique check 的时候对 (13000, 100), (13000, 102), (13000, 108)..(13000, 112) 所有的二级索引加record S lock, insert 的时候对 (13000, 100) 加GAP | insert_intention lock.
第二个 record 在unique check 的时候对(13000, 100), (13000, 102), (13000, 108)..(13000, 112) 所有的二级索引加record S lock. insert 的时候对 (13000, 112)加 GAP | inser_intention lock.
那么这时候这两个record 都可以同时插入成功, 就造成了unique key 约束失效了.

假如 a 事务删除一条记录,b事务想插入这条记录,是会被阻塞的,因为 a 持有这条记录的 uk 上的 X 记录锁,而 b 事务想插入这条记录,b 会尝试获取一个 S 型临键锁,因为 a 事务还没 提交,此时上的 S 能保证不管 a 是否提交,b 都能执行对应的操作,比如 a 提交..
排查命令
查询 information_schema.INNODB_TRX 表来获取当前所有活跃的 InnoDB 事务
1 | SELECT |
trx_mysql_thread_id: 这是关联其他表的关键,它就是我们平时说的 connection id 或 process id。
1 |
|


可以看到 RR 级别的话在 IODKU 执行更新的情况下也会给 主键上的supremum pseudo-record 记录加上 X 型的临键锁,很可怕。
除了防止幻读,也为了 保证语句复制的安全性 (Statement-Based Replication Safety)
在基于语句的复制(SBR)模式下,主库只会把原始的IODKU语句发送到从库去执行。
如果主库上多个IODKU语句是并发执行的,它们的执行顺序可能会影响最终结果(比如,谁执行了INSERT,谁执行了UPDATE)。
为了保证从库重放时能得到和主库完全一致的结果,InnoDB必须对这类可能插入新记录(尤其是可能插入到末尾)的操作进行串行化处理。
锁住supremum记录就是一种简单有效的串行化手段。它相当于一个“队尾锁”,确保同一时间只有一个事务可以在表的末尾进行插入或更新操作,从而保证了在从库上以任何顺序重放,结果都是确定的。
这个强锁主要是为了满足REPEATABLE-READ的严格要求。在执行IODKU的事务开始前,将会话的隔离级别临时调整为 READ-COMMITTED。

读提交就没有这个问题。
事务1
insert into t values(null, 50, 50) on duplicate key update val=50;

事务2
insert into t values(null, 70, 70) on duplicate key update val=70;

事务1
insert into t values(null, 60, 60) on duplicate key update val=60;

进入等待锁的状态,等第四步之后发现死锁,事务2 回滚,插入语句执行成功。

事务2
insert into t values(null, 30, 30) on duplicate key update val=30;
死锁,事务2 回滚。
成功复现了 那篇博客 的场景,IODKU 遇到重复的 二级 uk 更新 非索引列 的值,并在重复的记录上加了 X 型临键锁,导致出现死锁。
这个应该对应我实际遇到的场景
来理一下发生的事情。
首先上面那种场景能理解了,稍微有点问题的是在记录存在的情况下(不是被delete marked 的记录),为什么上锁的时候还要上 S 锁(普通insert 是S,IODKU 是X 临键锁)。
实际上如果uk重复的记录是 被删除的,那上 临键锁是可以理解的,就像博客例子举的那样。
如果遇到被删除的重复记录,会在每个 uk 上给重复的记录加 临键锁,还会给 下一条 记录 也加一个 临键锁。
为什么 primary key 也是unique key index, 为什么primary key 没有这个问题?
本质原因是在secondary index 里面, 由于mvcc 的存在, 当删除了一个record 以后, 只是把对应的record delete marked, 在插入一个新的record 的时候, delete marked record 是保留的.
也就是说,主键索引树上记录和 二级索引树 记录都是 标记删除,此时插入一条 主键重复记录的话,会直接在原位置写这条记录,然后记一个 undolog,原来的二级索引是 标记删除,两种情况,一种是这条记录 uk 和原来的不一样,那就没什么考虑了,在二级索引树插入记录就好了,第二种是 uk 和原来的一样,这时:

可以发现,应该还是在索引树插入记录,然后会遇到重复键,因此给重复的记录和下一条记录都上了临键锁。
问题同样回到了 二级uk重复的时候上了很多锁,或者说,二级树为什么不能直接在 标记删除的记录上修改呢?正是因为允许存在多条uk相同的记录(包括标记删除的),所以才要上那么多锁。如同这个图所说的那样:

假如现在插入的新纪录 主键不同,但是uk相同,如果我们直接修改二级树上的记录,把二级索引的主键列改成新纪录的值,那就会出现,如果一个事务通过uk想找原来的记录就找不到了,因为现在的uk的主键列已经变了,所以这样就无法实现mvcc了。而如果保留原来记录的二级索引,那查找的时候就会找到这条记录,拿着主键去聚簇索引找,然后再通过mvcc看到“可见”的记录。我的理解是这样的,所以如果在 二级uk 重复的情况下,就会上锁,因为存在多条记录,光靠latch应该保护不了了。
在primary index 里面, 在delete 之后又insert 一个数据(主键相同), 会将该record delete marked 标记改成non-delete marked, 然后记录一个delete marked 的record 在undo log 里面, 这样如果有历史版本的查询, 会通过mvcc 从undo log 中恢复该数据. 因此不会出现多个相同主键的delete mark record 跨多个page 的情况, 也就不会出现上述case 里面(13000, 100) 在page1, (13000, 112) 在page3.
那么在insert 的时候, 和上面的二级索引插入2阶段类似, 需要有latch 或者lock 进行保护, 这里primary index 通过持有page X latch 就可以保证两个阶段的原子性, 从而两次的insert 不可能同时插入成功, 进而避免了这个问题.


第一种情况的先删后增就是很明显的在插入的时候uk遇到重复键,并且要重新插入一个二级索引,该索引的主键列是新的主键值。
第二种情况和第三种情况本质是一样的,其实和第一种也差别不大,因为都更新了主键,更新主键往往也是分成两步,先删除原纪录,然后插入新纪录,因为更新主键意味着在聚簇索引树的位置也要变了,所以是先删除后插入。
至于为什么 记录存在(非标记删除) 的情况也要上 S 锁,之前也查过了。
结论:
在delete + insert, insert … on duplicate key update, replace into 等场景中, 为了实现判断插入记录与现有物理记录是否冲突和插入记录这两个阶段的原子, unique check 的时候会给所有的相同的record 和下一个record 加上next-key lock. 导致后续insert record 虽然没有冲突, 但是还是会被Block 住, 进而有可能造成死锁的问题.
更新主键 (Clustered Index Key)
更新一条记录的主键值,在InnoDB存储引擎中,其底层操作等同于在聚簇索引中删除旧记录,然后插入一条新记录。
为什么是这样?
聚簇索引的本质: 在InnoDB中,表本身就是按主键顺序组织的一个B+树结构,这被称为聚簇索引。数据行的所有内容(所有列的值)都存储在B+树的叶子节点上。数据的物理存储顺序与主键的逻辑顺序是紧密相关的。
更新的后果: 当您更新一个主键的值(例如,UPDATE … SET id = 200 WHERE id = 100;),这条记录在B+树中的物理位置必须改变。原来id=100的记录存放在包含99、101等邻近键值的磁盘页(Page)上,而id=200的记录需要被移动到存放199、201等键值的磁盘页上。
实现方式: 对于B+树这种有序结构来说,最高效地“移动”一条记录的方式,就是将其视为两个独立操作:
删除 (DELETE): 在id=100的旧位置,将原记录标记为删除。
插入 (INSERT): 在id=200的正确新位置,插入一条包含所有新数据的记录。
这个“删除+插入”的操作会引发一系列连锁反应,代价非常高昂:
二级索引的连锁更新: 表上所有的二级索引都存储了对应的主键值作为“指针”来定位完整的数据行。当主键值发生变化时,这条记录在每一个二级索引中的条目也必须被更新。这同样是通过对每个二级索引进行“删除旧条目(包含旧主键值),插入新条目(包含新主键值)”来完成的。
磁盘I/O和日志: 这个过程会涉及对聚簇索引和所有二级索引的多次磁盘页面读写,并产生大量的redo log和undo log。
“直接修改主键列”不行,根本原因在于:
维护有序性: 直接修改会破坏二级索引按照 (二级索引键, 主键) 组合的严格排序规则。
物理结构: 索引值的改变意味着物理存储位置的改变,数据库引擎通过“逻辑删除+逻辑插入”来实现这种物理位置的移动。
算法统一性: “删除+插入”是一个统一且健壮的逻辑,它可以处理所有索引键值更新的情况,而“原地更新”只在极少数不影响排序的特殊情况下才可能实现,数据库引擎为了逻辑的简单和可靠,会统一采用前者。
技术上的解释:B+树的物理结构
有序存储: B+树的叶子节点是双向链表,所有索引条目在这些叶子节点上是严格有序存储的。这个顺序是物理上的,决定了数据存放在哪个磁盘页(Page)以及页内的哪个位置。
位置决定价值: 一个索引条目的值决定了它在B+树中的物理存放位置。
修改即移动: 当你修改一个索引条目中的任何一个排序列(无论是二级索引键本身,还是作为次要排序列的主键)时,这个条目的逻辑顺序就可能发生改变。只要逻辑顺序变了,它在B+树中的物理位置也必须改变。
“删除+插入”是“移动”的实现: 在B+树这种精密的结构中,最直接、最可靠的“移动”一个条目的算法,就是先在旧位置将其删除,再在新位置将其插入。这个过程可能只涉及在一个页内的移动,也可能涉及跨磁盘页的移动(如果新旧位置离得很远)。
Nginx & Openresty
非阻塞就是,事件没有准备好,马上返回EAGAIN,告诉你,事件还没准备好呢,你慌什么,过会再来吧。好吧,你过一会,再来检查一下事件,直到事件准备好了为止,在这期间,你就可以先去做其它事情,然后再来看看事件好了没。虽然不阻塞了,但你得不时地过来检查一下事件的状态,你可以做更多的事情了,但带来的开销也是不小的。所以,才会有了异步非阻塞的事件处理机制,具体到系统调用就是像select/poll/epoll/kqueue这样的系统调用。它们提供了一种机制,让你可以同时监控多个事件,调用他们(epoll_wait())是阻塞的,但可以设置超时时间,在超时时间之内,如果有事件准备好了,就返回。当事件没准备好时,放到epoll里面,事件准备好了,我们就去读写,当读写返回EAGAIN时,我们将它再次加入到epoll里面。这样,只要有事件准备好了,我们就去处理它,只有当所有事件都没准备好时,才在epoll里面等着。这样,我们就可以并发处理大量的并发了,当然,这里的并发请求,是指未处理完的请求,线程只有一个,所以同时能处理的请求当然只有一个了,只是在请求间进行不断地切换而已,切换也是因为异步事件未准备好,而主动让出的。这里的切换是没有任何代价,你可以理解为循环处理多个准备好的事件,事实上就是这样的。与多线程相比,这种事件处理方式是有很大的优势的,不需要创建线程,每个请求占用的内存也很少,没有上下文切换,事件处理非常的轻量级。并发数再多也不会导致无谓的资源浪费(上下文切换)。更多的并发数,只是会占用更多的内存而已。 我之前有对连接数进行过测试,在24G内存的机器上,处理的并发请求数达到过200万。现在的网络服务器基本都采用这种方式,这也是nginx性能高效的主要原因。
nginx为了更好的利用多核特性,提供了cpu亲缘性的绑定选项,我们可以将某一个进程绑定在某一个核上,这样就不会因为进程的切换带来cache的失效。
对于一个基本的web服务器来说,事件通常有三种类型,网络事件、信号、定时器。从上面的讲解中知道,网络事件通过异步非阻塞可以很好的解决掉。如何处理信号与定时器?
event模块的主要功能就是,监听accept后建立的连接,对读写事件进行添加删除。事件处理模型和Nginx的非阻塞IO模型结合在一起使用。当IO可读可写的时候,相应的读写事件就会被唤醒,此时就会去处理事件的回调函数。
特别对于Linux,Nginx大部分event采用epoll EPOLLET(边沿触发)的方法来触发事件,只有listen端口的读事件是EPOLLLT(水平触发)。对于边沿触发,如果出现了可读事件,必须及时处理,否则可能会出现读事件不再触发,连接饿死的情况。
在ngx_trylock_accept_mutex()函数里面,如果拿到了锁,Nginx会把listen的端口读事件加入event处理,该进程在有新连接进来时就可以进行accept了。注意accept操作是一个普通的读事件。下面的代码说明了这点:
1 | (void) ngx_process_events(cycle, timer, flags); |
Nginx多进程的锁在底层默认是通过CPU自旋锁来实现。如果操作系统不支持自旋锁,就采用文件锁。
ngx_process_events()函数是所有事件处理的入口,它会遍历所有的事件。抢到了accept锁的进程跟一般进程稍微不同的是,它被加上了NGX_POST_EVENTS标志,也就是说在ngx_process_events() 函数里面只接受而不处理事件,并加入post_events的队列里面。直到ngx_accept_mutex锁去掉以后才去处理具体的事件。为什么这样?因为ngx_accept_mutex是全局锁,这样做可以尽量减少该进程抢到锁以后,从accept开始到结束的时间,以便其他进程继续接收新的连接,提高吞吐量。
ngx_posted_accept_events和ngx_posted_events就分别是accept延迟事件队列和普通延迟事件队列。可以看到ngx_posted_accept_events还是放到ngx_accept_mutex锁里面处理的。该队列里面处理的都是accept事件,它会一口气把内核backlog里等待的连接都accept进来,注册到读写事件里。
而ngx_posted_events是普通的延迟事件队列。一般情况下,什么样的事件会放到这个普通延迟队列里面呢?我的理解是,那些CPU耗时比较多的都可以放进去。因为Nginx事件处理都是根据触发顺序在一个大循环里依次处理的,因为Nginx一个进程同时只能处理一个事件,所以有些耗时多的事件会把后面所有事件的处理都耽搁了。
为了更精细地控制对于客户端请求的处理过程,nginx把这个处理过程划分成了11个阶段。他们从前到后,依次列举如下:
NGX_HTTP_POST_READ_PHASE:
读取请求内容阶段
NGX_HTTP_SERVER_REWRITE_PHASE:
Server请求地址重写阶段
NGX_HTTP_FIND_CONFIG_PHASE:
配置查找阶段:
NGX_HTTP_REWRITE_PHASE:
Location请求地址重写阶段
NGX_HTTP_POST_REWRITE_PHASE:
请求地址重写提交阶段
NGX_HTTP_PREACCESS_PHASE:
访问权限检查准备阶段
NGX_HTTP_ACCESS_PHASE:
访问权限检查阶段
NGX_HTTP_POST_ACCESS_PHASE:
访问权限检查提交阶段
NGX_HTTP_TRY_FILES_PHASE:
配置项try_files处理阶段
NGX_HTTP_CONTENT_PHASE:
内容产生阶段
NGX_HTTP_LOG_PHASE:
日志模块处理阶段
四层和七层负载均衡的区别
层数越低,接触到的数据信息就越基础;层数越高,能理解的数据内容就越丰富。
四层负载均衡 (Layer 4 Load Balancing)
核心原理:它工作在 TCP/UDP 协议层。负载均衡器在接收到客户端请求后,会通过修改数据包的目标地址和端口(以及源地址,实现NAT),然后直接转发给后端某一台服务器。在这个过程中,它不会去读取数据包的具体内容。
决策依据:它做转发决策的唯一依据是 网络层传输层 层的信息,主要是源/目标 IP 地址和源/目标端口号。
工作模式:可以看作一个“包转发器 (Packet Forwarder)”。客户端和后端服务器之间建立的是一条完整的 TCP 连接,负载均衡器只是这条连接上的一个中转节点。
性能极高:因为它不关心包里面的具体内容,不需要解析应用层协议,所以处理速度非常快,开销极低,能应对巨大的流量。
通用性强:只要是基于 IP 和端口的协议,理论上都可以进行负载均衡,不限于 HTTP。
缺点:
功能单一:它无法感知应用层的状态。比如,它无法根据请求的 URL、浏览器类型、Cookie 等信息来做更智能的转发。
典型代表:LVS (Linux Virtual Server)、云服务商的网络负载均衡器 (NLB)。
七层负载均衡 (Layer 7 Load Balancing)
工作层面:应用层 (Application Layer)。
核心原理:它工作在 HTTP/HTTPS, FTP, SMTP 等具体的应用协议层。它会与客户端建立一次完整的 TCP 连接,接收并完整地读取应用层的数据(比如一个完整的 HTTP 请求),然后根据请求中的具体内容,再作为一个新的客户端与后端服务器建立另一条 TCP 连接,将请求转发过去。
决策依据:除了 L4 的所有信息外,它还能解析出应用层的各种信息,如 URL 路径、HTTP Headers (请求头)、Cookie、请求方法 (GET/POST) 等。
优点:
极其智能和灵活:可以实现复杂的路由规则。例如:
将 yourdomain.com/images/* 的请求转发到图片服务器集群。
将 yourdomain.com/api/* 的请求转发到 API 服务器集群。
根据用户的 Cookie 实现“会话保持 (Sticky Session)”,确保同一用户的请求总是发到同一台后端服务器。
可以修改 HTTP 报文,比如添加/删除 Headers。
可以卸载 SSL/TLS 加密,后端服务器只需处理 HTTP 即可。
缺点:
性能开销更大:因为它需要解析应用层协议,维持与客户端和服务器的两条连接,缓冲数据,所以 CPU 和内存消耗都比四层负载均衡大,性能也相对较低。
典型代表:Nginx、云服务商的应用负载均衡器 (ALB)。
OpenResty® 是一个功能完备的Web平台,它集成了增强版的Nginx核心、增强版的LuaJIT、大量精心编写的Lua库以及众多高质量的第三方Nginx模块及其外部依赖 。将Nginx服务器有效地转变为一个强大的Web应用服务器 。在这个服务器中,Web开发者可以使用Lua编程语言来编写脚本,驱动现有的Nginx C模块,从而处理复杂的业务逻辑。
这种架构的核心优势在于其将动态语言(Lua)的灵活性与底层C语言服务器(Nginx)的原始性能相结合。OpenResty® 旨在利用Nginx的事件模型,在Nginx服务器内部完整地运行服务器端Web应用,不仅能与HTTP客户端进行非阻塞I/O,还能与MySQL、PostgreSQL、Memcached和Redis等远程后端进行非阻塞I/O 。
应当总是使用 set_keepalive,同时连接池的大小应当设置得足够大。否则短连接很容易将你系统的临时端口用尽。
另外,在进行压力测试时,应当禁掉 DDEBUG 和 –with-debug,同时使用 warn 以上的 error_log
日志过滤级别。否则你的 nginx
都忙着刷不带缓冲的错误日志了。另外,你也应设置访问日志的缓冲区或者完全禁掉访问日志(如果你不需要的话),见
如果你的 nginx 进程的 CPU 占用比较高,可以使用“火焰图”(flamegraph)对内部的执行热点进行分析:
分析工具
基于Openresty开发的应用路由性能调优思路
Lua火焰图显示,CPU时间主要消耗在ngx_http_lua_var_set/get这两个函数上,而不是他自己编写的业务逻辑代码。这几乎是找到了“冒烟的枪”。它清晰地指明,性能瓶颈在于通过ngx.var这个API在Lua和Nginx之间传递数据所带来的巨大开销。ngx.var是用于读写Nginx变量的接口,频繁调用它意味着频繁地在Lua VM和Nginx C核心之间进行数据交换和上下文切换,而这个过程的成本远高于纯粹在Lua VM内部执行的计算。
ua代码大部分时间是在解释模式下运行,而不是被LuaJIT的即时编译器(JIT)所编译和优化。他在火焰图中观察到的lj_BC_xxx栈帧是这一判断的直接证据,这些栈帧代表LuaJIT正在执行字节码(ByteCode),这是其解释器的典型特征。
对于一个像LuaJIT这样以高性能著称的VM,JIT编译是其速度的关键来源。当JIT编译器成功运行时,它会将频繁执行的Lua代码(“热代码”)编译成本地的机器码,其执行效率可以逼近原生C代码。反之,如果代码路径由于某些原因无法被JIT编译,VM就会退回到逐条解释执行字节码的慢速模式。这两种模式之间的性能差异可以是数量级的。
需要理解为什么JIT会失效。LuaJIT的JIT编译器并非万能,它不支持Lua语言的所有特性和内建函数。那些不被支持的部分被称为“NYI”(Not Yet Implemented,尚未实现)原语。当JIT编译器在分析一个热代码路径时,如果遇到了一个NYI原语,它会放弃对该路径的编译,这个过程称为“JIT中止”(JIT abort)。
为了解决这个问题,OpenResty生态系统提供了一个关键的库:lua-resty-core 。这个库的核心作用是为那些在标准Lua中是NYI的常用函数(尤其是与ngx_lua模块API交互的核心部分)提供了JIT兼容的替代实现。通过在代码的init_by_lua阶段简单地执行require “resty.core”,开发者实际上是在“猴子补丁”(monkey-patching)当前的Lua环境,用JIT友好的版本覆盖了那些有问题的标准函数。
在OpenResty中,决定应用性能的最关键因素,是确保热点代码路径能够被LuaJIT的JIT编译器成功编译。章亦春的所有建议——使用lua-resty-core、避免NYI、预分配表——最终都服务于这一个目标。开发者必须建立一种“像JIT一样思考”的心智模型,在编写代码时,优先选择JIT友好的模式和API,而不是仅仅遵循常规的编码习惯。这意味着,对性能有极致要求的团队,不能将LuaJIT仅仅看作一个黑盒,而应主动去了解其工作原理、优势和限制。
因此,在设计应用架构时,应有意识地减少这种“跨界聊天”(必须警惕Nginx的C环境和Lua VM之间边界穿越的成本。每一次这样的穿越都涉及到数据结构的转换和上下文的切换,其开销远大于在单一环境(无论是纯C还是纯Lua)中的操作。)。例如,Guanglin Lv后来确认他主要使用ngx.ctx在不同的Lua处理阶段之间传递数据。ngx.ctx是一个请求级别的Lua table,其数据完全保留在Lua VM内部,因此在access_by_lua中存入、在balancer_by_lua中取出的操作,几乎没有额外的边界穿越开销。与之相比,如果使用ngx.var来传递大量或复杂的数据,则每次读写都会触发一次昂贵的C/Lua交互。选择正确的API来在不同阶段间共享状态,是降低这部分固定开销的关键。
将性能剖析融入开发生命周期:火焰图的生成和分析不应仅仅是解决线上问题时的最后手段,而应成为性能测试和回归分析的标准流程。在开发和测试阶段就主动进行剖析,可以在问题暴露于生产环境之前,识别并修复潜在的性能瓶颈。
epoll的工作模式:
epoll的一个实例(你可以想象成一块监控面板)可以同时监控一个监听fd和成千上万个连接fd。
当epoll_wait()返回时,它会告诉你:“监听fd响了,快去accept!” 或者 “连接fd 123有数据了,快去read!” 或者 “连接fd 456可以发送数据了,快去write!”
你的程序(Nginx的worker进程)在一个循环里调用epoll_wait(),然后根据返回的fd类型和事件类型,去执行相应的accept, read, write操作。
什么是惊群?
多个worker进程以fork()方式创建,它们继承了父进程(Master进程)打开的所有fd,其中就包括那个唯一的监听fd。于是,所有worker进程都持有同一个监听fd。在老的Linux内核中,当一个新连接到来时,内核会唤醒所有正在epoll_wait()并等待这个监听fd的进程。假设有8个worker进程,8个进程同时被唤醒,然后冲过去调用accept()。但连接只有一个,所以最终只有一个worker能accept()成功,剩下7个都失败返回(得到EAGAIN错误)。这7个进程白白被唤醒了一次,做了无用功,并引发了不必要的CPU上下文切换,浪费了系统资源。这就是“惊群”。
Linux 2.6 之前的解决方案 (Nginx的accept_mutex)(用户态锁):
Nginx引入了一个accept_mutex(接受互斥锁)。
在每个worker进程的事件循环中,它会尝试去非阻塞地获取这个锁 (trylock)。
获取锁成功:
这个worker进程成为“天选之子”,它负责去监听新连接。
它会把监听fd通过epoll_ctl()添加到自己的epoll监控集合中。
现在,只有它自己会因为新连接事件而被唤醒。
获取锁失败:
说明已经有其他worker在监听了。
它会把监听fd从自己的epoll监控集合中移除。
这样,它就只处理自己手上的已有连接的读写事件,完全不关心新连接的到来。
这样,通过这把锁,Nginx在同一时刻,确保了只有一个worker进程在处理新连接,从而在应用层完美地解决了惊群问题。
SO_REUSEPORT选项 (Linux 3.9+): 这是一个更现代、更高效的解决方案。
Nginx的现代实践:
Nginx会检测内核版本。在支持SO_REUSEPORT的现代Linux系统上,你可以在nginx.conf的listen指令后添加reuseport选项。
listen 80 reuseport;
启用后,Nginx将使用SO_REUSEPORT机制,并自动禁用旧的accept_mutex,从而获得更好的性能和连接分发均衡性。
无论是哪个版本的Nginx,也无论是否使用SO_REUSEPORT,初始化的流程都是一致的:
Master进程启动: 读取配置文件(如nginx.conf),根据listen指令得知需要监听哪些端口(如80, 443)。
创建和绑定:** Master进程调用socket()创建套接字,设置SO_REUSEADDR等选项,并调用bind()将其绑定到指定的IP和端口,最后调用listen()开始监听。这一步只由Master进程完成。
Fork子进程: Master进程随后fork()出指定数量的Worker子进程。
继承文件描述符: 根据Unix/Linux的特性,子进程会继承父进程所有已打开的文件描述符。这意味着,每一个Worker进程都拥有了那个由Master进程创建好的监听套接字的“副本”**。
关键区别在于SO_REUSEPORT如何影响这个继承来的套接字:
不使用reuseport(经典模式): 所有Worker进程共享同一个底层的内核监听队列。这就是产生“惊群”问题的根源,需要accept_mutex等机制来协调。
使用reuseport(现代模式): 当Master进程为一个套接字设置了SO_REUSEPORT选项并fork出多个Worker进程后,虽然每个Worker继承的fd数值上是同一个,但在内核层面,情况发生了根本性的变化:
独立的内核队列: 内核会为每一个使用了这个SO_REUSEPORT套接字的进程(也就是每个Worker进程)创建一个专属的、独立的监听队列。它不再是所有进程共享一个总队列。
内核级负载均衡:当一个新的TCP连接请求(SYN包)到达时,内核不会去唤醒任何人。相反,内核会根据这个连接的四元组(源IP、源端口、目的IP、目的端口)进行一次哈希计算。
精准投递: 根据哈希计算的结果,内核会精确地选择一个Worker进程,并将这个新连接放入它专属的那个监听队列中。
唯一唤醒:因为连接只被放入了一个队列,所以最终只有那一个被选中的Worker进程的epoll_wait()会被唤醒,因为它监控的专属队列(全连接队列)变“满”了。其他所有Worker进程的队列都没有变化,它们会继续安然休眠。
SO_REUSEPORT的出现,让内核改变了游戏规则。它在唤醒进程之前,就通过哈希算法做了一次“分流”,将连接请求“精准投递”到某个特定的Worker进程。因此,即使所有Worker都在等待,也只有一个会被“精准命中”并唤醒。这就在内核层面彻底、高效地解决了惊群问题。
在通常情况(没有 SO_REUSEPORT)下是完全正确的。一个内核中的socket对象,确实对应着一套自己的SYN队列和Accept队列。在Nginx的经典模式下,所有Worker进程继承并共享的是同一个内核socket对象,因此它们也就在争抢同一套队列资源。
但是,SO_REUSEPORT的出现就是为了打破这个规则。
当Master进程在socket上设置SO_REUSEPORT选项后,这个socket的性质就变了。它告诉内核:“我准备创建一个可以被多个进程共同绑定的服务端口,请为它们建立一个群组(group)”。
之后,当Master进程fork出Worker进程时:
虽然每个Worker进程继承的fd数值上是同一个,但在内核看来,由于SO_REUSEPORT的存在,内核会为每一个持有这个fd的Worker进程,都维护一套独立的、专属的SYN队列和Accept队列。
正是因为SO_REUSEPORT,内核才为每个Worker进程分配了专属的监听队列,即使它们最初源自同一个socket调用。
问:在reuseport场景下,各个工作进程在epoll里面注册的是什么?
答:每个Worker进程在自己的epoll实例中,注册的依然是那个从Master进程继承来的、数值相同的监听fd。
例如,Master创建的监听fd是5,那么所有Worker进程都会执行 epoll_ctl(worker_epoll_fd, EPOLL_CTL_ADD, 5, …)。它们看起来都在监控同一个东西。
问:在什么情况下会触发回调然后accept新连接?
答:神奇之处在于内核的“精准投递”,下面是完整的分解步骤:
启动阶段:
Master进程创建listening_fd(假设为5),并为其设置SO_REUSEPORT选项。
Master进程fork出3个Worker进程(W1, W2, W3)。
W1, W2, W3都继承了listening_fd=5。
W1将fd=5加入自己的epoll_1;W2将fd=5加入自己的epoll_2;W3将fd=5加入自己的epoll_3。
所有Worker都调用epoll_wait()进入休眠。
新连接到达 (SYN包):
一个客户端的SYN包到达服务器。
内核协议栈识别出该包的目标端口(如80)启用了SO_REUSEPORT。
内核哈希与分发:
内核提取该连接的四元组(例如 src_ip:12345, dst_ip:80)。
内核对这个四元组进行哈希计算,得出一个结果。根据这个结果,内核决定将这个连接分配给W2。
专属队列处理:
内核将这个半连接信息放入W2专属的SYN队列,并从W2的端口回复SYN-ACK。
客户端回复最终的ACK。
内核在W2专属的SYN队列中找到对应条目,完成握手,并将这个完整的连接放入W2专属的Accept队列。
关键点:从始至终,W1和W3的SYN队列与Accept队列都是空的,完全没有感知到这个新连接的存在。
精准Epoll通知与回调:
因为只有W2的Accept队列中有了新内容,所以只有W2的监听fd(fd=5)的内核状态变为了“可读”。
内核检查所有正在监控fd=5的epoll实例。但是,由于SO_REUSEPORT的队列隔离机制,内核知道这个“可读”事件只与W2有关。
因此,内核只唤醒正在epoll_2上等待的W2进程。
W2的epoll_wait()返回,事件循环发现是fd=5就绪了。
它调用注册在fd=5上的回调函数,即ngx_event_accept。
成功Accept:
ngx_event_accept函数调用accept(5, …)。
因为W2的专属Accept队列中确实有一个等待处理的连接,所以accept()调用立即成功,返回一个新的连接fd。
后续流程就和我们之前讨论的一样了,W2开始在这个新的连接fd上处理HTTP请求。
总结: 在reuseport场景下,所有Worker进程看似在epoll中监控同一个监听fd,但SO_REUSEPORT选项已经授权内核进行了一次预处理和分流。内核通过哈希,将不同的连接请求放入了绑定到同一个端口的不同socket的私有队列中,从而实现了只唤醒一个“天选”进程的效果,完美地解决了惊群问题。
为了精确,我们需要将“监听队列”拆分为两个在内核中真实存在的、不同的队列:
半连接队列 (SYN Queue): 当服务器收到客户端的SYN包后,会回复SYN-ACK,然后将这个“半成品”连接放入SYN队列,等待客户端最终的ACK。
全连接队列 (Accept Queue): 当服务器收到最终的ACK后,三次握手完成。内核会将这个连接从SYN队列中取出,放入Accept队列,等待应用程序调用accept()来取走。
通常我们口语中的“监听队列已满”,指的就是这个Accept Queue满了。
现在,我们结合这两个队列,重说一遍SO_REUSEPORT的流程:
初始化: Nginx的Master进程创建监听套接字时设置了SO_REUSEPORT。随后fork出的多个Worker进程虽然继承了fd,但内核因为这个选项,为每一个Worker进程都创建了一套独立的SYN队列和Accept队列。
新连接到达 (SYN包):
客户端的SYN包到达服务器网卡。
内核TCP/IP协议栈发现这个包的目标端口启用了SO_REUSEPORT。
内核对该连接的四元组(源IP/端口,目的IP/端口)进行哈希计算。
精准投递 (SYN Queue):
根据哈希结果,内核选择一个唯一的Worker进程。
内核将这个半连接状态放入该Worker进程专属的SYN队列中,并从此队列回复SYN-ACK。
关键: 其他Worker进程的SYN队列完全没有变化,它们对此一无所知。
握手完成 (ACK包):
客户端回复最终的ACK包。
内核根据TCP状态找到之前存放的半连接条目(就在那个被选中的Worker的SYN队列里),完成握手。
随后,内核将这个完全建立好的连接放入该Worker进程专属的Accept队列中。
唤醒:
由于只有这一个Worker进程的Accept队列从“空”变成了“非空”,因此只有它的监听套接字(listening fd)的“可读”状态被触发了。
因此,只有这个Worker进程的epoll_wait()会从阻塞中返回,并得到“监听套接字可读”的通知。
总结: SO_REUSEPORT的本质,就是在内核层面为每个Worker进程创建了专属的、私有的连接接收流水线(SYN队列 + Accept队列),并通过哈希算法在新连接进入的第一步就决定了它该走哪条流水线。这样就从根源上避免了所有Worker去争抢同一个公共资源。
epoll注册、等待队列与事件处理器
Q: 内核的唤醒机制是否通过socket的等待队列实现的?
您的直觉完全正确!这正是通过Socket自己的“等待队列”(Wait Queue)实现的。
epoll并非一个孤立的系统,它深度整合在Linux的I/O和进程调度机制中。
等待队列 (Wait Queue): 在内核中,几乎所有可能导致进程等待的资源(比如一个socket的接收缓冲区、一个锁)都有一个与之关联的“等待队列”。这个队列里记录了所有正在睡眠、等待该资源变为可用状态的进程。
epoll_ctl的作用: 当你调用epoll_ctl(epoll_fd, EPOLL_CTL_ADD, sock_fd, …)时,你不仅仅是在epoll实例中注册了一个fd。内核还会悄悄地做一件事:将当前进程(的一个引用)加入到sock_fd所对应的内核socket对象的等待队列中,并做一个标记:“这个进程是在等epoll事件”。
epoll_wait与休眠: 当进程调用epoll_wait()时,如果没有就绪事件,内核会让这个进程进入休眠状态。
状态改变与唤醒: 当一个数据包到达,内核协议栈将数据放入sock_fd的接收缓冲区。在完成这个动作后,内核会执行一个wake_up()操作,去唤醒所有在这个socket的等待队列中休眠的进程。
epoll响应: 被唤醒的进程中,epoll系统知道是它注册的等待事件发生了。于是,epoll会将这个就绪的fd信息放入自己的“就绪列表”中,最终epoll_wait()得以返回,将就绪列表交给用户程序。
所以,您的理解非常到位。epoll是高层管理者,它利用了底层每个socket自带的等待队列机制来实现高效的事件通知。
Q: &event 同时包含了读写事件的处理函数吗? 读、写要分开注册吗?
这两个问题也切中了epoll在应用层的使用精髓。
&event里有什么?:
在Nginx中,一个连接ngx_connection_t通常包含两个独立的ngx_event_t结构体:一个用于读(rev),一个用于写(wev)。rev->handler指向读回调,wev->handler指向写回调。
epoll_ctl中传递的epoll_data联合体非常小,它只能保存一个指针(或者一个整数)。
因此,当Nginx注册读事件时,它传递的是读事件结构体 rev 的指针。当注册写事件时,传递的是写事件结构体 wev 的指针。
所以,epoll每次返回的“回传凭证”要么是读事件的指针,要么是写事件的指针,不可能同时是两者。Nginx拿到这个指针后,就知道是哪个具体事件就绪了,然后执行其对应的handler。
读、写要分开注册吗?:
是的,读写事件的“兴趣”是独立管理的,可以分开注册,也可以合并注册。
epoll的事件掩码events是一个位掩码,你可以灵活地组合:
events = EPOLLIN; // 只对读事件感兴趣
events = EPOLLOUT; // 只对写事件感兴趣
events = EPOLLIN | EPOLLOUT; // 同时对读和写都感兴趣
epoll_ctl有三种操作:ADD(添加)、MOD(修改)、DEL(删除)。Nginx正是通过MOD来动态地改变对一个fd的兴趣。
一个典型的Nginx工作流:
连接建立后: Nginx只对读事件感兴趣。它会调用epoll_ctl(…, EPOLL_CTL_ADD, fd, {EPOLLIN, &read_event})。
请求处理完,准备响应: Nginx开始write()响应数据。如果数据没写完(发送缓冲区满了),说明现在需要关注“可写”状态了。
修改兴趣: 它会调用epoll_ctl(…, EPOLL_CTL_MOD, fd, {EPOLLIN | EPOLLOUT, &write_event})。
注意: 这里不仅添加了EPOLLOUT,也保留了EPOLLIN,因为在发送响应的同时,可能需要处理客户端发来的下一个请求(HTTP Keep-Alive)或连接关闭事件。同时,因为epoll_wait返回时会区分是读还是写事件触发的,Nginx会把写事件的指针作为回传凭证。
响应发送完毕: Nginx会再次调用epoll_ctl(…, EPOLL_CTL_MOD, fd, {EPOLLIN, &read_event}),移除对EPOLLOUT的兴趣,因为它暂时不需要写数据了,只关心客户端的下一次读取请求。
important
epoll的本质:监控“就绪状态”,而非“事件对象”
epoll里面直接存放的不是一个抽象的“事件”,而是对文件描述符(fd)的“就绪状态”的兴趣。
让我们走一遍全流程,看看数据包是如何唤醒进程的。
A. “注册”的到底是什么?
当Nginx调用 epoll_ctl(epoll_fd, EPOLL_CTL_ADD, sock_fd, &event) 时,它实际上是在对内核说:
“你好内核,我(这个进程)对 sock_fd 这个文件描述符的可读(EPOLLIN)和可写(EPOLLOUT)状态非常感兴趣。请把它加入我的epoll_fd这个监控列表里。哦对了,如果它真的就绪了,你在通知我的时候,请把这个 &event 的地址原封不动地还给我,这样我就知道是我当初注册的哪个具体任务了。”
epoll 并不理解 event 这个结构体(即Nginx的ngx_event_t)的内容。它只是把它当作一个回传凭证(在epoll_event结构中是epoll_data联合体)保存起来。
所以,epoll内部维护的是一个 <fd, 关注的状态, 回传凭证> 这样的兴趣列表。
B. 从数据包到进程唤醒的全流程
数据到达: 一个网络数据包通过网卡进入系统。
内核协议栈处理: 内核的TCP/IP协议栈处理这个数据包,识别出它属于哪个TCP连接。每个TCP连接在内核中都有一个struct sock对象,这个对象里包含了接收缓冲区和发送缓冲区。内核将包中的数据放入对应连接的接收缓冲区。
“就绪状态”改变: 当接收缓冲区从“空”变为“非空”时,这个socket在内核中的状态就从“未就绪”变成了“可读就绪”。
epoll的回调机制 (Kernel-Level): **内核在改变socket状态的同时,会检查这个socket是否被任何epoll实例所监控(等待队列)**。它发现你的Worker进程的epoll实例对这个socket的“可读”状态感兴趣。
加入就绪队列: 内核会将这个socket的fd和当初注册的那个“回传凭证”(也就是&event的地址) 一起,添加到一个专属于你的epoll实例的就绪队列(Ready List)中。
唤醒进程: 同时,内核会唤醒正在epoll_wait()调用上睡眠的你的Worker进程。
epoll_wait()返回: Worker进程被唤醒后,epoll_wait()函数从内核态返回到用户态。它的返回值就是就绪队列中项目的数量,并且它会把你注册的那些“回传凭证”(epoll_event结构体数组)从内核空间拷贝到你传入的用户空间缓冲区(有一个拷贝)。
Nginx的处理: Nginx的事件循环拿到这个epoll_event数组,遍历它。对于每一项,它取出“回传凭证”——那个ngx_event_t对象的指针,然后直接执行 event->handler(event),调用之前注册好的回调函数,开始进行read()数据、解析HTTP等操作。
C. 这是通用的机制吗?
是的,这是所有使用epoll的程序(不仅仅是Nginx)的标准工作模式。
无论是Redis、Netty(在Linux上)、Envoy还是任何其他使用epoll的高性能程序,其基本原理都是一样的:
用户态: 定义自己的事件/连接管理结构。
注册: 通过epoll_ctl向内核注册对某个fd的就绪状态的兴趣,并附上一个指向自己事件管理结构的指针/凭证。
等待: 调用epoll_wait()等待内核通知。
处理: 被唤醒后,从内核返回的凭证中找到自己的管理结构,执行相应的业务逻辑(回调)。
epoll本身是内核提供的一个高效的、通用的“就绪状态”通知机制,而Nginx则是在这个机制之上构建了自己精巧的事件处理框架。
Nginx的Master-Worker之间通信和管理机制非常轻巧和可靠。
通信机制:socketpair
Master进程在fork出每个Worker进程之前,会通过socketpair()系统调用创建一对Unix域套接字(Unix Domain Socket)。这对套接字就像一条私密的、双向的管道。
fork之后,Master进程关闭其中一端,保留另一端。
Worker进程也关闭其中一端,保留与Master相对应的一端。
这样,Master和每个Worker之间都建立了一条专属的、全双工的通信渠道
状态管理:信号 (Signal)
Master进程作为父进程,通过Unix信号机制来监控所有Worker子进程的状态。
注册信号处理器: Master进程在启动时会为关键信号(如SIGCHLD, SIGINT, SIGHUP等)注册好处理器函数。
SIGCHLD信号: 这是最重要的信号。当任何一个Worker子进程终止(无论是正常退出还是异常崩溃)时,操作系统内核都会向其父进程(也就是Master进程)发送一个SIGCHLD信号。
状态回收与重启: Master进程的SIGCHLD处理器被触发后,会调用waitpid()等函数来“回收”这个已终止的子进程,并获取其退出状态码。通过分析状态码,Master就知道子进程是正常退出还是异常崩溃。如果发现是异常崩溃,并且配置了需要保持Worker数量,Master就会重新fork一个新的Worker进程,以维持服务的稳定性。
总结:Nginx的父子进程管理,是经典的Unix“信号驱动”模式,稳定、高效且可靠。
epoll事件处理全流程详解 (含回调)
这是Nginx的心脏。我将为您描述一个HTTP请求从连接建立到响应完成的全过程。
A. 核心构件:事件与处理器(回调)
在Nginx中,核心数据结构是:
ngx_connection_t: 代表一个连接,包含了socket fd、读写缓冲区、SSL上下文等所有与连接相关的信息。
ngx_event_t: 代表一个事件,是我们很重要的事件管理结构。每个连接(ngx_connection_t)都关联着一个读事件和一个写事件。事件结构体中最重要的成员是:
handler: 这是一个函数指针,它指向一个处理该事件的函数。这就是Nginx的回调函数。
active: 一个标志,表示这个事件是否已经被添加到了epoll中。
B. 事件循环:永不停歇的心脏
每个Worker进程都在一个while(1)循环中工作,这个循环的核心是ngx_process_events_and_timers()函数。
调用epoll_wait(),并设置一个超时时间。Worker进程在此阻塞,等待内核通知事件的发生。
epoll_wait()返回,携带了一批“就绪”的事件。
Worker进程遍历这些就绪的事件(需要先拷贝到内核)。
对于每一个就绪的事件 event,直接执行:event->handler(event)。这就是回调函数的调用。
处理完所有I/O事件后,处理定时器队列中的超时事件(如连接超时)。
回到第1步,继续循环。
C. 流程1:处理新连接 (Accept Event)
注册: Nginx启动时,监听套接字的读事件的handler被设置为ngx_event_accept函数。这个读事件被加入到epoll中。
事件发生: 一个客户端发起TCP连接请求,三次握手完成。内核将这个新连接放入Accept队列,监听套接字变为“可读”。(通过等待队列将事件加入到就绪队列……)
处理:
epoll_wait()被唤醒,返回监听套接字的读事件。
事件循环调用其handler,也就是ngx_event_accept。
ngx_event_accept函数内部:
a. 调用accept()接收新连接,得到一个新的连接socket fd。
b. 从连接池中获取一个ngx_connection_t结构体来管理这个新连接。
c. 【关键:注册新回调】 为这个新连接设置初始的事件处理器。通常,会将新连接的读事件的handler设置为ngx_http_init_request,写事件的handler设置为一个空闲处理器(因为现在还不需要写)。
d. 将这个新连接的读事件添加到epoll中,开始等待客户端发送数据。
D. 流程2:处理请求数据 (Read Event)
事件发生: 客户端沿着新建立的连接发送HTTP请求(如GET /index.html …)。连接socket变为“可读”。
处理:
epoll_wait()被唤醒,返回这个连接的读事件。
事件循环调用其handler,也就是我们上一步设置的ngx_http_init_request。
ngx_http_init_request和后续的HTTP处理函数内部:
a. 调用read()或recv()从socket缓冲区读取数据到Nginx的内存缓冲区。
b. 开始解析HTTP请求(请求行、请求头等)。
c. 【状态机与回调变更】** Nginx的请求处理是一个状态机。例如,读完请求行后,读事件的handler可能会被修改为ngx_http_process_request_headers。整个请求处理过程,事件的handler会根据当前状态不断地被修改,指向下一个阶段该执行的函数**。
d. 如果一次read()没有读完整个请求,函数就直接返回。因为读事件还在epoll里,下次数据到来时,epoll会再次通知,并从上次的状态继续执行。
e. 请求完全接收并解析完毕后,Nginx根据配置找到对应的资源(文件或上游服务器),准备响应。
E. 流程3:发送响应数据 (Write Event)
事件发生与注册:
Nginx准备好了响应数据(比如读取了index.html文件内容),调用write()或send()发送。
由于TCP滑动窗口和内核发送缓冲区的限制,一次write()可能无法发送完所有数据。
当write()返回一个小于预期发送的字节数,或者返回EAGAIN错误时,Nginx知道现在不能再写了。
【关键:注册写回调】 此时,Nginx会将这个连接的写事件添加到epoll中,并将其handler设置为一个专门的发送函数,如ngx_http_writer。
处理:
当客户端接收了数据,内核的发送缓冲区有了空闲空间,连接socket变为“可写”。
epoll_wait()被唤醒,返回这个连接的写事件。
事件循环调用其handler,也就是ngx_http_writer。
ngx_http_writer函数内部:
a. 继续发送缓冲区中剩余的数据。
b. 如果数据全部发送完毕,就将这个连接的写事件从epoll中移除,因为暂时不再需要关注“可写”状态了。
c. 如果数据依然没有发完,就什么也不做,等待下一次epoll的“可写”通知。
这个“注册-等待-回调”的循环,就是Nginx用单线程高效处理海量并发I/O的全部奥秘。
uWSGI & Gevent
WSGI (Web Server Gateway Interface) - “协议与规范”
WSGI 本身不是一个服务器,也不是一个库,它是一个规范(一种标准接口)。你可以把它理解成是 Python 世界里的 “API 规范”,专门用来定义 Web 服务器 (比如 uWSGI) 如何与 Python Web 应用程序/框架 (比如 Django, Flask) 进行通信。
这个规范解决了什么问题?在 WSGI 出现之前,如果你写了一个 Python Web 框架,你可能需要为各种不同的 Web 服务器(Apache, Nginx 等)编写专用的适配器。这非常混乱。
WSGI 的出现统一了江湖。它规定:
服务器端 (uWSGI) 必须实现一个方式,能够调用应用程序。
应用程序端 (你的代码) 必须提供一个可调用对象(通常是一个函数),我们称之为 application。
这个 application 函数必须接受两个参数:
environ: 一个包含了所有 HTTP 请求信息的 dict 对象(比如请求头,路径,方法等)。
start_response: 一个由服务器 uWSGI 提供的回调函数。应用程序在准备好响应头(比如 200 OK, Content-Type: application/json)后,必须先调用这个函数,然后再返回响应体。
底层细节:
WSGI 的核心就是一个简单的函数签名 application(environ, start_response)。uWSGI 服务器负责把原始的 HTTP 请求解析成 environ 字典,并提供 start_response 函数,然后调用你的 Python 代码即 application。你的代码里面负责处理业务逻辑,调用 start_response,并返回响应体数据。它是一个纯粹的、解耦的“契约”。
uWSGI - “应用程序服务器”
uWSGI 是一个功能强大的应用程序服务器。它的核心职责是“承上启下”:
对上 (对 Nginx): 它能与专业的 Web 服务器(如 Nginx)高效通信。它们之间通常使用一种性能极高的二进制协议,叫做 uwsgi 协议(注意小写,以区别于软件本身)。这种通信可以通过 TCP 端口,也可以通过你提到的、性能更高的 Unix 域套接字(Unix Socket)进行。
对下 (对 Python 应用): 它负责加载并运行你的 Python WSGI 应用程序。它会管理一个或多个工作进程(Worker Processes),并将来自 Nginx 的请求分发给这些进程来处理。
核心功能和底层细节:
进程管理: uWSGI 通常会有一个 Master 进程和多个 Worker 进程。Master 进程负责监控和管理 Worker 进程,如果某个 Worker 挂了,Master 会重新拉起一个新的。
协议翻译: 它的核心工作之一就是将 Nginx 通过 uwsgi 协议发来的请求,翻译成符合 WSGI 规范的 environ 和 start_response,然后调用你的 Python application。反过来,它再把 Python 应用返回的响应,打包成 uwsgi 协议格式,发回给 Nginx。
性能: uWSGI 是用 C 语言编写的,性能极高。它能处理高并发请求,并有效地利用多核 CPU 资源。
Gevent - “并发魔法师”
Gevent 是一个基于协程的 Python 网络库。它解决的核心问题是高并发 I/O。
在传统的同步模型里,一个进程/线程在处理一个请求时,如果遇到 I/O 操作(比如查询数据库、请求外部 API),它就会阻塞,CPU 就在那里空等,直到 I/O 操作完成。这极大地浪费了 CPU 资源。
Gevent 引入了协程(也叫微线程或 Greenlet)。协程是一种非常轻量级的“线程”,它的切换开销极小,并且是由程序代码自己来控制切换时机(称为“协作式调度”)。
底层细节 (Gevent 的魔法:Monkey Patching):
Gevent 最神奇的地方在于它的“猴子补丁” (monkey.patch_all())。当你调用这个函数时,Gevent 会在运行时动态地替换掉 Python 标准库中所有会产生阻塞的 I/O 函数(比如 socket.connect, socket.recv, time.sleep 等),换成它自己实现的非阻塞版本。
工作原理: 当你的代码(已经打了猴子补丁)执行到一个 I/O 操作时,比如 requests.get(‘http://…’),底层的 socket.recv() 实际上是 Gevent 的版本。它不会真的阻塞整个进程,而是会:
向操作系统注册一个事件,告诉内核:“当这个 socket 有数据可读时,请通知我。”
让出 (yield) 当前协程的执行权。
Gevent 的事件循环 (Event Loop) 会接管控制权,去看有没有其他已经准备好(比如 CPU 计算任务,或者其他已完成的 I/O)的协程可以运行。
当最初的那个数据库查询/API 请求返回数据后,操作系统通知 Gevent 的事件循环,事件循环再把执行权交还给之前被挂起的那个协程,让它从刚才停下的地方继续执行。
这一切对于你的业务代码来说是完全透明的。你依然可以像写同步代码一样书写逻辑,但底层却实现了异步非阻塞的高并发效果。这使得单个 uWSGI Worker 进程可以同时处理成百上千个并发连接。
第二部分:一个请求的完整生命周期 (底层细节)
假设你的配置是:Nginx <–> Unix Socket <–> uWSGI (with Gevent workers) <–> Your WSGI App
第1步: 客户端 -> Nginx
用户浏览器发起一个 HTTP 请求,例如 GET /api/users/123。
经过 DNS 解析、TCP 三次握手、TLS 握手(如果是 HTTPS),请求数据包到达你的服务器的 80/443 端口。
Linux 内核协议栈处理数据包,将其递交给正在监听该端口的 Nginx Master 进程。Nginx Master 进程再将这个连接交给一个空闲的 Nginx Worker 进程处理。
第2步: Nginx 内部处理
Nginx Worker 进程解析 HTTP 请求报文,得到请求方法 (GET)、路径 (/api/users/123)、HTTP 版本、请求头等信息。
Nginx 查看自己的配置文件 (nginx.conf)。它根据 server_name 和 location 块匹配请求。它发现 /api/ 路径的请求应该被代理到后端。
配置中写的是 uwsgi_pass unix:///path/to/your/app.sock;。Nginx 知道它需要和 uWSGI 通信。
第3步: Nginx -> uWSGI (通过 Unix Socket)
这是关键的一步。Nginx 不会把原始的 HTTP 报文直接发过去。
它会按照 uwsgi 协议的格式,将解析好的请求信息(如 REQUEST_METHOD, PATH_INFO 等)打包成一个二进制的数据块。
Nginx 通过系统调用 write(),将这个二进制数据块写入到 /path/to/your/app.sock 这个 Unix 域套接字文件中。因为是文件系统 IPC,它绕过了整个网络协议栈,没有 TCP 的封包/解包、校验和、拥塞控制等开销,速度极快。
第4步: uWSGI 接收并分发
uWSGI Master 进程早已创建好了这个 app.sock 文件并监听它。当有数据写入时,操作系统会唤醒正在 accept() 上等待的 uWSGI Master 或 Worker。
uWSGI Master 进程将这个新连接交给一个空闲的 uWSGI Worker 进程来处理。
这个 Worker 进程从 Unix Socket 中通过 read() 读取 Nginx 发来的 uwsgi 协议数据。
第5步: uWSGI Worker 内部处理 & 调用 Python 应用
Worker 进程解析 uwsgi 二进制数据,将其翻译成 WSGI 规范所要求的 environ 字典。
Worker 进程创建一个 start_response 回调函数。
现在,它拥有了调用 Python 应用所需的一切。它调用你的 **WSGI 入口函数:application(environ, start_response)**。
第6步: Python 应用 & Gevent 的表演时刻
你的 Python 代码开始执行。假设处理 /api/users/123 需要查询数据库。
代码执行到 db_cursor.execute(“SELECT * FROM users WHERE id=123”)。
由于 monkey.patch_all() 的作用,这个数据库驱动底层的 socket 操作已经被换成了 Gevent 的非阻塞版本。
当前协程(Greenlet)被挂起,它会让出 CPU,同时告诉 Gevent 的事件循环:“当数据库连接上有数据返回时,请叫醒我。”
关键点:这个 uWSGI Worker 进程并没有被阻塞!Gevent 的事件循环会立刻检查是否有其他协程可以运行。如果此时 Nginx 又发来了第二个请求,这个 Worker 进程可以立即开始处理第二个请求,启动一个新的协程,而第一个请求的协程则在静静地等待数据库返回结果。这就是用 Gevent 实现高并发的核心。
第7步: 应用返回响应
数据库返回了查询结果。操作系统通知 Gevent 的事件循环,事件循环唤醒了第一个请求对应的协程(通过执行回调函数实现的,回调知道是哪个协程,并且将读到的socket上的数据库数据作为结果返回回去)。
协程从之前挂起的地方继续执行,处理数据库结果,生成 JSON 响应。
代码调用 start_response(‘200 OK’, [(‘Content-Type’, ‘application/json’)])。
函数 return [b’{“id”: 123, “name”: “Alice”}’],返回响应体。
第8步: uWSGI -> Nginx (返回路径)
uWSGI Worker 进程拿到了 Python 应用返回的响应头和响应体。
它将这些信息再次打包成 uwsgi 协议的二进制格式。
通过 write() 系统调用,将响应数据写回给来时的那个 Unix Socket 连接。
第9步: Nginx -> 客户端
Nginx Worker 进程正在 epoll 上监听着这个 Socket。当 uWSGI 写回数据时,Nginx 被唤醒。
Nginx 从 Socket 读取 uwsgi 协议的响应数据,将其解析并翻译成标准的 HTTP 响应报文(添加 HTTP/1.1 200 OK 状态行,组装响应头等)。
最后,Nginx 将这个完整的 HTTP 响应报文通过服务器的网卡发送回用户的浏览器。
第10步: 浏览器渲染
浏览器接收到 HTTP 响应,解析内容并将其渲染成用户看到的页面。
至此,一个请求的完整旅程结束。这个架构的精髓在于:
Nginx 负责处理一切与网络相关的脏活累活(连接管理、静态文件、安全、负载均衡)。
uWSGI 作为坚固的桥梁,高效地管理和运行 Python 进程。
Gevent 在应用层内部,用魔法般的方式让同步风格的代码实现了异步 I/O,极大地提升了单个进程的并发处理能力。
OpenResty Cosocket 是什么?
Cosocket (Coroutine Socket) 并不是一种新的 socket 类型,而是 ngx_lua 模块提供的一套 Lua API。这套 API 的目的是让用户可以在 Lua 代码中,以一种同步的、看起来是阻塞的方式,来执行底层的、异步的、非阻塞的网络 I/O 操作。
当你调用一个 cosocket API (例如 tcpsock:connect, tcpsock:receive) 时,它并不会阻塞整个 Nginx 的 Worker 进程。相反,它巧妙地利用了 Lua 协程和 Nginx 事件循环,实现了高效的并发。
Cosocket 如何与 Nginx 事件循环协作?可以分解为以下几个步骤:
发起 I/O 调用: 你的 Lua 代码在一个由 ngx_lua 模块创建和管理的 Lua 协程中运行。当代码执行到 local ok, err = tcpsock:connect(“google.com”, 80) 时,connect 函数被调用。
启动底层操作 & 注册事件:
connect 函数(内部是 C 实现)会调用 Nginx 底层的非阻塞 socket API 来真正发起一个 TCP 连接。因为是非阻塞的,这个调用会立即返回,通常会返回一个 EAGAIN 或 EINPROGRESS 的错误码,表示“操作正在进行中”。
同时,它将这个 socket 的文件描述符 (fd) 以及我们感兴趣的事件(对于 connect 来说是 “可写” 事件)当然还有回调函数注册到 Nginx 的主事件循环中。Nginx 的事件循环通常是基于 epoll (在 Linux 上) 的。
这个注册动作相当于告诉 Nginx:“请帮我盯着这个 socket,当它可以写入数据时(意味着连接已成功建立),请通知我。”协程让出 (Yield):
在注册完事件后,C 函数会**调用 coroutine.yield()**。这是最关键的一步。
yield 会暂停当前 Lua 协程的执行,并将控制权交还给 ngx_lua 模块的 C 代码。
此时,这个处理请求的 Nginx Worker 进程完全没有被阻塞。它可以去处理其他请求、处理其他已经就绪的 I/O 事件,CPU 资源被充分利用。你的那个 Lua 协程则进入“休眠”状态,等待被唤醒。事件就绪 & Nginx 唤醒:
一段时间后,TCP 连接成功建立。操作系统会通知 Nginx 的事件循环(epoll_wait 返回),告知之前注册的那个 socket fd 现在“可写”了。
(这一步之前有一些底层知识待补充)Nginx 的事件循环会调用与该事件关联的回调函数。这个回调函数是由 ngx_lua 模块在第 2 步设置好的。协程恢复 (Resume):
这个回调函数知道是哪个 Lua 协程在等待这个事件。它会调用 coroutine.resume(),唤醒之前休眠的那个协程,并将 I/O 操作的结果(成功还是失败,错误信息等)作为 resume 的参数传递回去。
Lua 协程从之前 yield 的地方继续执行,tcpsock:connect 函数现在才真正“返回”,并将结果赋值给 ok 和 err 变量。
总结一下:对于写 Lua 代码的你来说,tcpsock:connect 看起来就像一个普通的阻塞函数。但实际上,在它“阻塞”的期间,整个 Nginx 服务依然在全速运转,处理着成千上万的其他任务。Cosocket API 就像一个语法糖,让你能用同步的思维写出异步性能的代码。
与 Gevent 的比较:异同之处
Cosocket 的思想和 Gevent 非常相似。它们都致力于解决同一个问题:如何用同步的编码风格实现异步 I/O 并发。
相同点:
核心机制: 两者都依赖于“协程/微线程”(Lua Coroutine vs Gevent Greenlet)作为并发调度的基本单位。
用户体验: 两者都提供了看似阻塞的 API,让开发者无需手动管理复杂的回调函数(避免了“回调地狱”)。
底层思想: 都是通过“发起 I/O -> 注册事件 -> 让出执行权 -> 事件就绪 -> 恢复执行权”的模式来工作。
底层区别 (非常关键):

它们依靠什么来完成事件循环?这是对底层机制的终极追问。
OpenResty: 它完全依赖 Nginx 的事件循环。Nginx 的事件循环是其高性能的核心,它在底层会使用操作系统提供的最高效的 I/O 多路复用技术。
在 Linux 上是 epoll。
在 FreeBSD/macOS 上是 kqueue。
在 Windows 上是 IOCP (I/O Completion Ports)。
Nginx 会自动选择当前 OS 支持的最佳模型。所以,Cosocket 的事件驱动能力,实际上是由 Nginx 和操作系统内核共同提供的。
Gevent: 它依赖于独立的事件循环 C 库,最常见的是 libev 或 libevent。这些 C 库做的事情和 Nginx 的事件循环非常类似,它们也封装了底层的 epoll, kqueue 等系统调用,提供了一套统一的、跨平台的事件处理接口。所以,追根溯源,Gevent 最终也是依赖操作系统内核提供的 I/O 多路复用机制。
核心结论:
OpenResty 的做法是一种深度整合、天人合一的模式。Lua 代码和协程成为了 Nginx 事件驱动世界的一等公民,共享同一个强大的心脏(事件循环)。
Gevent 的做法是一种通用嵌入、自给自足的模式。它在 Python 进程这个独立的王国里,建立了一套属于自己的、完整的事件驱动系统。
如果把 ngx_lua 模块比作一块性能炸裂的顶级 CPU,那么 OpenResty 就是设计和制造了这块 CPU,并围绕它构建了一台功能完备、性能均衡的超级计算机。
简单来说,ngx_lua 模块以及基于它构建的整个 lua-resty- 非阻塞库生态系统*,就是 OpenResty 项目的核心产出和最大贡献。
第一部分:谁做了什么?OpenResty 快的根源归属
OpenResty 的快,是 Nginx、LuaJIT 和 OpenResty 自身贡献三者完美结合的成果,缺一不可。
- Nginx:提供 “骨骼与心脏”
高性能事件循环 (The Heart): Nginx 的核心是一个基于操作系统事件通知机制(如 epoll, kqueue)的、非阻塞的事件循环。这是整个架构得以运转的“心脏”。它能以极低的开销管理数以万计的并发连接。
成熟的 HTTP 服务器 (The Skeleton): Nginx 提供了稳定、高效的 HTTP 协议解析、请求/响应管理、连接管理等所有 Web 服务器的基础功能。
模块化架构: Nginx 允许第三方模块(比如 ngx_lua)深度嵌入到它的请求处理流程中,在不同的阶段挂载自己的处理逻辑。
Nginx 贡献了“快”的底层 I/O 模型。 - LuaJIT:提供 “超速大脑与轻功”
JIT (Just-In-Time) 编译器: LuaJIT 是 Lua 语言的一个超高性能实现。它的 JIT 编译器能将热点 Lua 代码编译成高效的本地机器码,使得 Lua 代码的执行速度可以接近甚至媲美 C 语言。这对于需要复杂计算和业务逻辑的场景至关重要。
原生的协程支持 (The Agility): Lua 语言原生就支持协程 (coroutine)。这是 yield 和 resume 的语言基础。没有这个,cosocket 的实现会困难得多。
FFI (Foreign Function Interface): LuaJIT 的 FFI 机制允许 Lua 代码以极高的性能直接调用 C 函数和使用 C 的数据结构,几乎没有性能损耗。ngx_lua 模块正是利用 FFI 实现了 Lua 与 Nginx (C代码) 之间的高效通信。
LuaJIT 贡献了“快”的计算能力和并发调度的语言基础。 - OpenResty:作为 “总设计师与神经系统”
OpenResty 是将 Nginx 的“心脏”和 LuaJIT 的“大脑”完美缝合在一起的“总设计师”,并为这具强大的身体打造了完整的“神经系统”。
ngx_lua_module (The Bridge): 这是 OpenResty 项目的核心创造。这个 C 模块是连接 Nginx 事件循环和 Lua 协程的桥梁。我们上一轮讨论的 cosocket API 就是由这个模块提供的。它实现了将 I/O 操作注册到 Nginx 事件循环并适时 yield/resume Lua 协程的全部魔法。
非阻塞库生态 (lua-resty-X) (The Nervous System): 只有 cosocket 这个底层 API 是不够的。开发者需要方便的工具来和 Redis, MySQL, Memcached 等后端服务通信。OpenResty 项目开发并维护了一整套 lua-resty-X 库。这些库全部基于 cosocket API 构建,确保了所有外部通信都是 100% 非阻塞的。lua-resty-mysql, lua-resty-redis 等都是 OpenResty 的官方作品。
OpenResty 贡献了将两者能力融合的关键技术(ngx_lua),并在此基础上构建了完整的、实用的、高性能的非阻塞业务开发平台(lua-resty-X 库)。
第二部分:实战拆解:lua-resty-mysql 的一次 query 操作
让我们看看 local result, err = db:query(“SELECT * FROM users WHERE id = 123”) 这行代码背后发生了什么,来体会上面讲的协作过程。
前提: 假设已经通过 resty.mysql:new() 创建了 db 对象,并通过 db:connect() 建立了连接(connect 本身也是一个非阻塞的 cosocket 操作)。
获取连接 (OpenResty 的贡献):
db:query 首先会从内部的连接池中获取一个可用的 MySQL 连接。连接池 (set_keepalive) 是 lua-resty-mysql 库提供的重要性能优化,它避免了为每个查询都重新建立 TCP 连接的巨大开销。
构建并发送请求包 (LuaJIT + OpenResty):
lua-resty-mysql 库(纯 Lua 代码)会将 SELECT 语句按照 MySQL 的通信协议格式化成一个二进制数据包。
然后它调用底层的 cosocket API:ok, err = tcpsock:send(packet)。
ngx_lua 模块接管,将这个数据包通过非阻塞的 send() 系统调用写入 socket。如果内核的发送缓冲区满了,当前协程就会 yield,并将 socket 的“可写”事件注册到 Nginx 事件循环中,等待缓冲区可用。
等待响应包 (Nginx + OpenResty):
发送成功后,代码需要等待 MySQL 服务器返回数据。lua-resty-mysql 会调用 data, err = tcpsock:receive(…)。
这是最关键的非阻塞等待点。receive 函数通过 ngx_lua 模块,将这个 socket 的“可读”事件注册到 Nginx 的事件循环中。(都是通过 ngx_lua 模块注册 IO 事件和对应的回调函数(该函数负责读写数据和resume 协程))
然后,当前 Lua 协程立刻 yield (让出),执行权返回给 Nginx。
Nginx Worker 进程此时完全空闲,可以去处理其他成百上千个并发请求。
数据到达并唤醒 (Nginx + OpenResty):
MySQL 服务器处理完查询,将结果通过网络发回。
数据到达服务器网卡,Nginx 的事件循环(epoll_wait)被唤醒,发现之前注册的那个 socket 变得“可读”。
Nginx 触发 ngx_lua 模块预设的回调,该回调 resume 之前休眠的那个 Lua 协程,并将从 socket 读到的数据块作为返回值。
解析并返回结果 (LuaJIT + OpenResty):
Lua 协程被唤醒,tcpsock:receive 函数“返回”了原始的二进制数据。
lua-resty-mysql 库(纯 Lua 代码)开始解析这个二进制数据包,将其转换成用户友好的 Lua table 格式。
最后,db:query 函数将这个 table 返回给调用它的业务代码。同时,将这个 MySQL 连接放回连接池,以备下次使用。
总结:
在这个过程中,Nginx 负责监听 socket 事件,LuaJIT 负责高效地执行协议解析和业务逻辑,而 OpenResty(通过 ngx_lua 和 lua-resty-mysql)则扮演了指挥官的角色,完美地编排了整个异步流程,让开发者感觉不到底层的复杂性,同时获得了极致的性能。
limit rate & limit conn
加入了nodelay参数之后的限速算法,到底算是哪一个“桶”,是漏桶算法还是令牌桶算法?当然还算是漏桶算法。考虑一种情况,令牌桶算法的token为耗尽时会怎么做呢?由于它有一个请求队列,所以会把接下来的请求缓存下来,缓存多少受限于队列大小。但此时缓存这些请求还有意义吗?如果server已经过载,缓存队列越来越长,RT越来越高,即使过了很久请求被处理了,对用户来说也没什么价值了。所以当token不够用时,最明智的做法就是直接拒绝用户的请求,这就成了漏桶算法,哈哈~
burst队列在哪里
只要excess < limit->burst限速模块就会返回NGX_OK,并没有把多余请求放入队列的操作,这是因为Nginx是基于timer来管理请求的,当限速模块返回NGX_OK时,调度函数会计算一个延迟处理的时间,同时把这个请求放入到共享的timer队列中(一棵按等待时间从小到大排序的红黑树)。
Nginx主要有两种限速方式:按连接数限速(ngx_http_limit_conn_module)、按请求速率限速(ngx_http_limit_req_module)。
并非所有连接都会被计数。只有当服务器正在处理请求并且已读取整个请求标头时,该连接才会被计数。
该 Lua 模块除了支持在超过并发级别阈值时立即拒绝连接之外,还支持延迟连接。
default_conn_delay是典型连接(或请求)的默认处理延迟。
该延迟作为因并发请求(或连接)过多而引入的额外延迟的基本单位
与上一种情况类似,此方法还返回第二个返回值,指示此时(包括当前请求)的并发请求数(或连接数)。第二个返回值可用于监控未调整的传入并发级别。
监控并发等级怎么做?
此类的每个实例不包含任何状态信息,但包含conn和burst 阈值。基于键的实际限制状态存储在新lua_shared_dict方法 中指定的共享内存区域中,所以限速器实例在工作进程级别之间的共享是安全的只要限速值和burst的组合不变。
即便变了也没关系,只要去更新实例的那两个关键成员变量即可。
幽灵计数器
在极端情况下,例如 nginx 工作进程在处理请求过程中崩溃,存储在共享内存区域中的计数器可能会不同步。这可能会导致灾难性的后果,例如永久地盲目拒绝所有传入连接。(请注意,标准ngx_limit_conn模块也存在此问题。)我们可能会在不久的将来为该 Lua 模块添加针对此类情况的自动保护功能。
此外,确保调用leaving首先出现在 log_by_lua处理程序代码中非常重要,以尽量减少其他log_by_luaLua 代码抛出异常并阻止leaving调用运行的机会。
两种主要的失败场景:
Worker 进程崩溃(最严重的情况)
一个请求进入,incoming() 执行成功,计数器 +1。
在处理这个请求的过程中(比如执行 proxy_pass 或者一段复杂的 Lua 代码时),这个 Nginx Worker 进程因为某种原因(比如 C 模块的 bug、内存溢出等)突然崩溃退出了。
由于进程都没了,这个请求的 log_by_lua* 阶段自然也永远不会被执行。
后果:计数器被成功地 +1,但对应的 -1 操作 (leaving()) 却人间蒸发了。这个计数器在共享内存里就产生了一个无法减少的“幽灵计数”。
1、使用外部存储(架构级解决方案)
共享内存的根本问题在于它的状态会随着 Nginx 的生命周期而持续,且缺乏 TTL (Time-To-Live) 这种自动过期机制。代价是引入了网络开销和对外部 Redis 服务的依赖。
2、实现“清道夫”后台任务(修复)
这个方案用于解决最棘手的 Worker 进程崩溃问题。resty.limit.conn 本身没有提供自动修复机制,我们需要自己实现一个“巡检员”。
思路:利用 ngx.timer.at 创建一个只在某个 Worker 进程中运行的后台定时任务,定期检查共享内存中的数据,清理那些明显“死亡”的连接计数。
但这有个难题:我们怎么知道哪个计数是“幽灵”?一个长时间保持高位的计数器可能是真实的高并发,也可能是幽灵。
改进思路:引入“租约”或“心跳”机制。 我们不能只存一个数字,需要存更丰富的信息。
改造数据结构:在共享内存中,不直接存一个 count,而是存一个 table,里面记录了每个连接的唯一 ID 和进入时间。
1 | -- shm_dict:set("some_ip", { |
incoming() 的作用是向这个 table 里插入一个新的请求记录。leaving() 则是删除对应的记录。连接数就是 table 的大小。
1 | -- 在 init_worker_by_lua* 阶段 |
不再需要一个独立的 count 变量。count 的值是动态地从这个 table 中派生出来的。count 就是这个 table 中键值对的数量。
我们为每个被监控的 key(比如一个 IP 地址)在共享内存中存储一个序列化后的 Lua table。这个 table 的键是唯一的请求 ID (ngx.var.request_id),值是请求开始的时间戳。
为了线程安全必须使用 lua-resty-lock 锁
通过序列化 + 外部锁的组合,我们既可以在共享内存中存储和操作任意复杂的表结构,又能完美地保证并发环境下的线程安全。而 count 则是通过实时计算 table 的大小得来,确保了数据的一致性。
稍微有点重
只读检查。不会真的去修改共享内存。这是一种“预检”或“试探”模式,允许你在不消耗配额的情况下,提前知道请求是否会被允许。
组合限速器
此模块可以考虑所有相关的限制器,而不会给当前请求带来任何额外的延迟。
ngx.ctx 是什么?是否是请求维度的上下文?支持多个限速器上下文吗?
1 | if lim3:is_committed() then |
这个方案虽然复杂,但非常稳健,可以有效地自动修复因崩溃导致的计数器不一致问题。
Nginx 的共享内存字典 (ngx.shared.DICT) 是一个基于红黑树实现的、高性能的 key-value 存储,不能存储嵌套表,所以要用 cjson。
resty.limit.req类的实例返回当前每秒的超额请求数(如果超过速率阈值),而resty.limit.conn类的实例返回当前并发级别。
所有具体的限制器对象必须遵循相同的粒度(通常是 NGINX 服务器实例级别,涵盖其所有工作进程)。
多限速器系统采用了类2PC的原子性实现机制,通过预执行+提交的两阶段操作,配合回滚机制,确保多个限速器的状态更新具有原子性。这种设计在保证数据一致性的同时,避免了TCC模式的复杂业务逻辑,适合限速这种相对简单的场景。
TCC的Try特征:
✅ 资源检查:检查是否超过burst限制
✅ 不实际提交:commit=false时不写入共享内存
✅ 快速失败:任一限速器检查失败立即返回
TCC的Confirm特征:
✅ 实际提交:commit=true写入共享内存
✅ 逐个确认:依次对每个限速器确认
TCC的Cancel特征:
✅ 补偿操作:uncommit减少excess值
✅ 业务回滚:恢复限速器状态
现有TCC实现的不足:
Try阶段不够纯粹:最后一个限速器在Try阶段就提交了(i == n时commit=true)
没有真正的资源预留:Try阶段只是计算,没有预留资源
Cancel操作有限:只能简单减少excess,无法完全撤销复杂状态
为什么说是TCC而不是2PC?
2PC特征(现有代码不符合):
❌ 没有全局事务协调者的Prepare/Commit投票机制
❌ 没有参与者的”准备好提交”确认过程
❌ 不是基于数据库事务的ACID特性
TCC特征(现有代码符合):
✅ 业务层面的三阶段操作
✅ Try阶段的业务检查和资源预留概念
✅ Confirm阶段的业务确认
✅ Cancel阶段的业务补偿
1.1 跟踪JIT模型入门
要掌握LuaJIT的性能,首先必须理解其核心机制:跟踪即时编译器(Tracing JIT Compiler)。与Java HotSpot虚拟机或.NET CLR中常见的基于方法的JIT不同,LuaJIT不会一次性编译整个函数。相反,它会识别出所谓的“热路径”——通常是频繁执行的循环或函数调用序列。一旦识别出热路径,JIT便开始记录该路径上实际执行的字节码指令序列 。
这个被记录下来的序列被称为“踪迹”(Trace)。随后,踪迹被转换成一种基于静态单赋值(SSA)的中间表示(IR)。IR会经过大量优化,最终被编译成针对宿主架构的高效机器码 。理解这一基本概念至关重要,因为LuaJIT性能调优的主要目标,就是让JIT编译器能够为应用程序中最关键的部分创建长而不中断的踪迹。任何导致踪迹中断的因素都会迫使执行流回退到解释器模式。尽管LuaJIT的解释器本身也很快,但其性能与JIT编译后的代码相比,仍有数量级的差距 。
1.2 理解“未实现” (NYI)
“未实现”(Not Yet Implemented, NYI)原语是指LuaJIT的跟踪JIT编译器尚不知道如何翻译成其内部IR的特定Lua函数、字节码或语言特性 。当踪迹记录器在热路径上遇到一个NYI原语时,它无法继续记录,必须在该点放弃并中止(abort)当前踪迹的生成 。
NYI处理方式的演进:从“踪迹中止”到“踪迹拼接”
对于NYI的性能影响,一个普遍存在但已过时的理解是它们会使JIT完全失效。然而,其处理机制的演进对于现代OpenResty开发至关重要。
在旧版本的LuaJIT(如2.0)中,热循环中遇到NYI是灾难性的。它会导致“踪迹中止”(Trace Abort),迫使整个热循环及其周边逻辑全部在慢得多的解释器中运行 。
然而,现代OpenResty基于LuaJIT 2.1+的分支构建 ,该版本引入了一项名为“踪迹拼接”(Trace Stitching)的关键技术。该机制允许JIT在遇到NYI时,优雅地退出到解释器,仅执行这一个NYI函数,然后在该函数返回后,立即开始为后续代码记录一条新的踪迹。虽然这种切换本身“并非特别高效”,但它成功“避免了踪迹中止” 。
这一变化意味着性能惩罚的模式发生了根本性转变:从对整个热路径的完全去优化,转变为对单个NYI函数调用的高昂的、按次计算的开销。因此,开发者的优化策略也必须随之演进。它不再是二元对立的“不惜一切代价避免NYI”,而是更精细化的“在最热的代码路径中,最小化踪迹拼接调用的频率”。
下表整理了在OpenResty应用中常见的一些NYI原语。此列表主要参考了Tarantool项目维护的LuaJIT文档,这是一个非常宝贵的资源 。
诊断技术:定位NYI引发的性能瓶颈
本节提供一套定位NYI相关性能问题的分步指南。
一级诊断:使用 luajit -jv
这是定位NYI的首要工具。通过执行 luajit -jv your_script.lua,可以获得JIT编译过程的详细日志。需要重点关注输出中的 `` 消息,这是JIT因NYI而失败的确凿证据 。
二级诊断:使用 luajit -jdump
当 -jv 的信息不足时,-jdump 提供了最终的真相。它会输出每个踪迹详细的IR、优化过程和最终生成的汇编代码 。这是一个专家级工具,用于理解JIT为什么做出某些决策,而不仅仅是知道它中止了。
生产环境诊断:使用 jit.v 和 jit.dump
在无法直接使用命令行工具的生产环境中(如OpenResty),可以通过编程方式启用详细日志。在代码中 require(“jit.v”).start(“dump.txt”) 或 require(“jit.dump”).start(…) 可以将JIT的详细输出重定向到文件,以便进行离线分析
a. resty.core 默认导入的前提与新的优化推测
您提出了一个非常好的观点,确实,在较新的OpenResty版本中(自1.15.8.1起),resty.core 模块已经被默认加载 。
但这并不意味着 JIT 编译问题就不存在了,反而让问题变得更隐蔽、更高级。 resty.core 主要优化的是 ngx.* API 相关的函数,它通过FFI(外部函数接口)重新实现了这些API,使其对JIT友好 。然而,开发者自己编写的业务逻辑中,仍然可能大量使用标准Lua库中存在的、会导致 JIT 中止的 NYI (Not Yet Implemented) 原语。
所以,我们的优化前提依然成立。面试时,你可以这样表述,以体现你的技术深度:
“虽然现代OpenResty默认加载了resty.core,解决了ngx.* API的JIT问题,但在我们的限速组件核心逻辑中,我们发现性能依然不理想。通过火焰图分析,我们定位到瓶颈在于我们自己编写的业务代码中,使用了标准Lua库里的一些NYI原语,导致了JIT编译频繁中止。因此,优化的焦点从‘平台配置’转向了‘代码实现’的深层优化。”
重新推测的优化指标:基于这个前提,优化指标依然非常可观。修复业务逻辑中的NYI问题,通常能带来 20% - 50% 的性能提升,因为它直接影响了最核心、最热的代码路径的执行效率。
b. 我可能用到的、次数较多的LuaJIT不支持的原语
LuaJIT的JIT编译器为了保持速度和简单性,选择性地不支持某些动态或复杂的操作。以下是一些在网关、限速器这类逻辑中非常容易遇到的NYI原语:
string.gsub:特别是当它的第三个参数是函数或表时,这是最常见的“性能杀手”之一。如果你的限速规则需要复杂的动态替换,这个函数几乎一定会让你的JIT跟踪(trace)中止。
pcall 和 xpcall:错误处理是必要的,但它们本身是NYI。JIT编译器遇到它们就会停止。这意味着你的错误处理路径和它之后的代码路径都不会被JIT编译。优化策略:将 pcall 尽可能地放在热路径之外,或者只包裹最小范围的、真正可能出错的代码。
table.insert / table.remove:在循环中对一个非序列的表(即key不连续或为字符串)进行操作,可能会非常慢并中止JIT。
pairs / ipairs 遍历带有元方法(metamethods)的表:如果你的限速规则配置是一个复杂的Lua对象,使用了__index或__pairs等元方法,那么遍历它就会是NYI。
select 函数:处理可变参数时常用,但如果索引不是常量,JIT无法优化。
c. 如何排查出是 NYI 导致的性能问题?
这正是火焰图大显身手的地方,排查过程本身就是技术能力的体现:
宏观现象:压力测试时,服务的QPS上不去,CPU占用率却很高(比如一个worker核心被打满)。
火焰图分析:生成火焰图后,你会看到你的业务逻辑函数(例如 limiter.check())的“火焰”很宽,说明它消耗了大量CPU。
定位“元凶”:最关键的证据是,在你的业务函数(limiter.check())的上方,出现了大量以 lj_BC_ 开头的栈帧 。BC 代表 ByteCode(字节码)。这表明LuaJIT的JIT编译器放弃了对你代码的编译,退回到了逐条解释执行字节码的慢速模式。这就是JIT中止的直接、确凿的证据。
代码审查:有了火焰图的明确指向,你就可以回到代码中,仔细审查 limiter.check() 函数和它调用的函数,对照上面列出的NYI原语列表,找到那个“罪魁祸首”。
案例
优化点1:JIT编译失效导致的核心逻辑缓慢
这是从我们分析的案例中得出的最核心、也最能体现技术水平的优化点 。
潜在问题:你的限速组件核心逻辑(例如,读取配置、组合限速key、检查多个限速规则)运行在每个请求上,是绝对的“热路径”。如果这部分代码因为使用了LuaJIT不支持的函数(NYI原语)而无法被JIT编译,那么它就会退化到低效的解释执行模式,造成巨大的CPU浪费。
火焰图特征:在火焰图上,你会看到代表你业务逻辑的Lua函数(比如rate_limiter.execute)占据了很宽的CPU时间比例,并且它的顶端有大量lj_BC_xxx的栈帧。这明确表示LuaJIT正在解释执行字节码,而不是运行高效的本地机器码。
优化策略:
在init_by_lua_file阶段引入require “resty.core”,它可以自动地用JIT友好的版本替换掉许多标准Lua函数 。
审查代码,将类似string.gsub的复杂模式匹配、在循环中调用table.insert等常见的NYI操作,替换为JIT友好的替代方案(例如,使用string.find、预分配table等)。
量化指标与面试话术:
“在对我们的限速组件进行压力测试时,我们发现其引入了大约3毫秒的额外延迟,QPS上限卡在了10,000。通过火焰图分析,我们惊讶地发现,限速逻辑本身(一个名为check_limits的函数)竟然占据了CPU时间的30%,并且其火焰图顶端充满了lj_BC_xxx的栈帧,这是典型的JIT编译失败的特征。
经过排查,我们定位到两个问题:一是没有全局启用resty.core;二是在一个循环里使用了string.match来解析规则。我们采取了两个措施:首先在init阶段引入resty.core,然后将string.match重构为更简单的string.find和string.sub。
优化后的效果非常显著:check_limits函数在火焰图上几乎缩成了一条线,CPU占比从30%下降到不足5%。组件引入的延迟从3毫秒降低到0.5毫秒以下,服务的整体QPS提升了40%,达到了14,000。这个案例让我深刻理解到,在OpenResty中,编写JIT友好的代码是性能优化的第一杠杆。”
优化点2:内存分配与GC压力过大
对于一个多限速器组件,每个请求可能都需要处理多个规则,这很容易导致不必要的内存分配。
潜在问题:对于每个请求,你的代码可能会创建多个临时table来存储限速规则、当前状态、要返回的头部信息等。当QPS很高时,这会产生海量的小对象,给LuaJIT的垃圾回收器(GC)带来巨大压力,导致CPU周期被GC占用,并可能引发延迟抖动。
火焰图特征:火焰图上出现明显的lj_gc_step、lj_tab_resize或rehashtab函数调用,它们占据了不可忽视的CPU时间(例如5-10%)。这表明程序正在花费大量时间进行垃圾回收和table的动态扩容。
优化策略:
预分配:在创建table时,如果能预估其大小,就使用table.new(n, m)进行预分配,避免运行时的rehash开销 。
对象复用:这是更高级的技巧。不要为每个请求创建新table,而是实现一个table池。在请求开始时从池中获取一个“干净”的table,在请求结束时“清空”它并放回池中,供下一个请求使用。这可以近乎完全地消除这部分GC压力。
量化指标与面试话术:
“随着业务增长,我们发现网关的p99延迟偶尔会出现尖刺。火焰图显示,lj_gc_step函数的CPU占比在高峰期会达到10%以上。分析代码后我们发现,我们的多限速器组件在处理每个请求时,都会动态创建一个table来聚合所有限速器的结果。
我的优化方案是实现了一个基于ngx.ctx的请求级table池。在access_by_lua阶段开始时,我们尝试从ngx.ctx.table_pool获取一个table,如果不存在就新建一个。在逻辑的最后,我们不清空table,而是将其存回ngx.ctx,这样同一个Nginx请求处理流程中的其他Lua阶段(如header_filter)也可以复用它。
这个改动几乎完全消除了因我们组件产生的GC压力,火焰图中的lj_gc_step占比降至1%以下。服务的p99延迟毛刺消失了,整体吞吐量也稳定提升了10-15%。这体现了在高性能场景下,主动进行内存管理的重要性。”
优化点3:低效的字符串操作与Key构建
限速器的核心是key,如何构建这个key,对性能影响巨大。
潜在问题:限速key通常由多个部分拼接而成(例如,ratelimit:
火焰图特征:火焰图上能看到string.concat(由..操作符触发)、string.gsub、ngx.re.match等函数占用了较高CPU。
优化策略:
拼接优化:对于多个字符串的拼接,使用table.concat通常比多次使用..操作符更高效,因为它能一次性分配最终所需的内存。
避免正则:如果只是简单的子串查找或分割,用string.find、string.sub等非正则函数代替重量级的正则引擎。
结果缓存:如果限速key的某个组成部分(比如从JWT中解析出的UserID)计算成本较高,计算一次后就将其存入ngx.ctx,避免在同一个请求的后续处理中重复计算。
量化指标与面试话术:
“在一次例行性能剖析中,我们注意到一个奇怪的现象:火焰图中string.concat函数的CPU占比不低。我们的限速组件需要根据5个不同的变量来动态构建一个复杂的限速key。代码实现是key = v1.. v2.. v3.. v4.. v5。
我做了一个微优化,将其改为key = table.concat({v1, v2, v3, v4, v5})。虽然听起来改动很小,但在我们的压测环境下,这个小改动使得key构建的耗时减少了20%,并为整个服务带来了**3-5%**的QPS提升。
这件事给我的启发是,在网关这种每秒处理数万请求的场景下,任何在热路径上的微小开销都会被放大。一个优秀的工程师需要具备这种从火焰图中发现并优化代码细节的能力。”
Lua Table的内部构造:数组部分与哈希部分
Lua table的内部实现具有双重性,它同时是一个C风格的数组和一个哈希表 。
数组部分 (Array Part): 用于存储以从1开始的、连续的正整数为键的值。这种结构允许通过直接计算内存偏移量进行极速访问。
哈希部分 (Hash Part): 用于存储所有其他键值对,包括字符串键、整数键0、负整数键以及非连续的正整数键。访问哈希部分需要计算键的哈希值,并可能需要处理哈希冲突,因此速度较慢 。
Table池化的性能权衡:
池化并非没有成本。不使用池化的成本是高频的内存分配开销和随之增加的GC压力。而使用池化的成本,则是 fetch/release 函数的调用开销,以及 table.clear 函数本身带来的开销。table.clear 必须遍历table中的所有元素并将它们设为 nil,这是一个时间复杂度为 O(N) 的操作。
这就揭示了一个性能的“盈亏平衡点”。对于小尺寸、高频使用的临时table(例如,一个用于存放5个请求头的table),每分钟创建数百万个这样的对象所带来的GC压力,远大于清理它们的微小成本。在这种场景下,池化是净收益。相反,对于一个非常大的table(例如单个表包含数百甚至数千个元素的 Lua 表),table.clear 所花费的时间可能相当可观,甚至可能比让GC处理一次大的内存分配还要慢。
因此,专业的建议不是教条地“永远使用池”,而是一种数据驱动的策略:“对小尺寸、高频、临时的table使用池化。对于大尺寸的table,通过火焰图分析应用,寻找lj_tab_clear C函数的耗时,以确定池化对你的特定用例是否是净收益。” 。
It is recommended to always watch for the lj_tab_clear function frames in the C-land on-CPU flame graphs of your busy nginx worker processes.
致命危险:非阻塞世界中的竞态条件
尽管性能损失显著,但在OpenResty中避免使用全局变量的最根本原因,是为了防止引入微妙且不确定的竞态条件(Race Conditions),这关乎程序的正确性。
OpenResty的模型是基于协程的协作式多任务处理。当一个请求的协程调用了一个“让出”(yield)的API时(例如 ngx.sleep),Nginx的事件循环会挂起当前协程,转而去执行另一个并发请求的代码。如果这第二个请求也访问并修改了同一个全局变量,那么共享状态就被破坏了。当第一个请求被唤醒并继续执行时,它看到的全局变量值已经出乎意料地被改变,从而导致逻辑错误和难以追踪的bug 。
这个风险并不仅限于 ngx.sleep。任何执行网络或磁盘I/O的 ngx. API调用(如 cosocket:connect, ngx.location.capture, ngx.shared.dict:get 等)都是一个潜在的“让出点”*。因此,在OpenResty中使用可变的全局变量(或模块级变量)是根本不安全的。它破坏了请求之间的隔离性,引入了不可预测的行为。避免使用全局变量的首要动机是保证程序的正确性和确定性,性能提升只是一个附带的好处。
第四部分:精确测量:微优化的性能剖析
本节将提供一套精确的方法论,用于观察微小代码改动带来的影响,并以用户提到的 table.concat 优化为例进行具体分析。
4.1 使用CPU火焰图实现性能可视化
CPU火焰图是分析性能瓶颈的强大工具。在解读Lua火焰图时,需掌握以下几点 :
Y轴:代表调用栈的深度。栈底(根函数)在最下方,向上延伸。
X轴:代表CPU采样时间的百分比。每个矩形框代表一个函数栈帧,框的宽度与函数(包括其调用的所有子函数)在CPU采样中出现的频率成正比。一个更宽的框意味着该函数是性能热点。
trace#… 栈帧:这是LuaJIT火焰图特有的。它不代表一个Lua函数,而是一段已被JIT编译的机器码块。通过观察 trace#… 栈帧,可以了解哪些代码路径被成功JIT编译了 。
4.2 案例研究:测量table.concat优化的效果
本节直接回答用户的问题:“key构建耗时的减少是怎么观测的?火焰图能看到这么详细的信息吗?”
答案是:是的,但需要观察其二阶效应(second-order effects)。(通过二阶效应衡量微优化:火焰图是观察微优化效果的有力工具。即使优化本身很快,它带来的二阶效应(如GC压力的降低)也会在火焰图上清晰地体现出来,从而量化优化的成果。)
优化前 (.. 字符串连接):
代码 key = v1.. “:”.. v2….. 在循环中效率极低。每一步连接都会创建一个新的中间字符串对象(例如,v1.. “:” 创建一个,其结果再与 v2 连接又创建一个)。这些中间字符串立即成为垃圾,给垃圾回收器(GC)带来巨大压力。
优化后 (table.concat):
代码 key = table.concat({v1, v2,…}, “:”) 的效率要高得多。它只创建了一个小table,然后调用一个高度优化的C函数。该函数会先计算出最终字符串所需的总长度,一次性分配好内存,然后将所有部分拷贝进去,避免了中间对象的产生 。
在火焰图上观察效果:
一个微小、快速的操作本身可能因为采样间隔而不会在火焰图上清晰地显示出来。然而,其带来的影响是显著的。优化前的代码产生了大量临时字符串垃圾,这会迫使LuaJIT的GC频繁运行。GC活动会消耗CPU时间,这在火焰图上是可见的,通常表现为名为 lj_gc_step 或类似的C函数栈帧 。
优化后的代码几乎不产生垃圾,因此GC的运行频率会大幅降低。在“优化前”与“优化后”的火焰图对比中,会清晰地观察到与GC相关的栈帧宽度显著减小。用户观察到的“key构建耗时减少20%”,实际上是 (a) 字符串构建本身略微变快,以及 (b) GC窃取的CPU时间大幅减少的综合结果。而整体服务QPS提升3-5%,正是这些被节省下来的CPU周期现在可以用于处理更多请求的直接体现。
wrk 的多线程、事件驱动架构使其能从单台客户端机器上产生巨大的负载,足以将一台高性能服务器的CPU跑满 。相比之下,单线程的 ab 往往在服务器达到瓶颈之前,自身先成为了性能瓶颈。此外,wrk 强大的Lua脚本能力允许模拟真实的生产流量模式(如动态变化的请求头、POST数据等),这是 ab 无法做到的 。
5.2 一套实用的wrk测试规程
一个专业的基准测试是一个多层次的、科学严谨的过程。简单地运行工具是远远不够的。
第一层:环境加固
物理隔离:测试客户端和服务器必须是两台独立的物理机,以避免资源竞争 。
内核调优:在客户端和服务器上,都应调高内核参数。使用 ulimit -n 1024000 提高文件句柄数限制,同时增大 fs.file-max 和调整TCP相关参数 。
第二层:服务器配置
在 nginx.conf 中,将 worker_connections 设置为一个较高的值,例如 10240,以确保Nginx能处理足够的并发连接 。
第三层:测试设计
基线测试:首先使用简单的 wrk 命令找到服务器的饱和点:wrk -t<线程数> -c<连接数> -d<时长> URL。
场景模拟:编写 wrk 的Lua脚本,模拟生产环境的流量特征,例如添加认证头、动态URL路径、POST请求体等 。
第四层:执行与测量
预热:在正式计时前,先运行一个短时间的测试(例如100次调用或一个短循环),以确保LuaJIT已经完成了对热点代码的JIT编译 。
正式测试:运行足够长的时间(例如60-300秒),以观察系统的稳态行为。记录 wrk 的完整输出。
同步剖析:在运行 wrk 的同时,在服务器端使用剖析工具(如火焰图生成工具)来理解服务器在负载下的内部行为。
第五层:分析与迭代
将 wrk 的输出(RPS、延迟分布)与服务器端的剖析数据(如火焰图)进行关联分析。例如,RPS的下降应该对应于火焰图中出现的某个瓶颈。用浏览器打开.svg文件,分析火焰图,找到瓶颈 。
单一变量原则:每次只做一个改动,然后重复整个测试流程,以可验证的方式测量该改动带来的影响。
重新认识NYI:在现代OpenResty中,NYI的代价已从“踪迹中止”转变为“踪迹拼接”的开销。优化的重点应放在减少热路径中NYI函数的调用频率上,而非完全避免。使用 luajit -jv 是定位这些问题的首选工具。
使用高级压测工具(如 wrk2)
为什么是 wrk2:标准的 wrk 擅长用最大努力发出请求,但 wrk2 增加了一个关键功能:它可以按照固定的速率(例如,每秒10000个请求)发送请求。在这个前提下,它能非常精确地记录和报告延迟分布,包括 p50, p90, p99, p99.9 等。
具体方法:
运行一个持续时间较长(例如5分钟)的 wrk2 测试,设置一个接近你服务处理能力上限的固定速率。
命令示例:wrk2 -t8 -c200 -d5m -R10000 http://… ( -R 指定速率)
观测:在测试结果的延迟分布表中,你会看到 p99 的值。如果存在 GC 等问题导致的尖峰,p99 的值会远高于 p90 和 p50,并且 Max 值会异常地大。你可以多次运行测试,如果 p99 的值在不同测试中波动很大,或者在单次测试的后期报告中变大,这就证明了不规律尖峰的存在。
wrk2 是 wrk 的一个分支,它在性能测试中非常有用,因为它能维持恒定的请求速率。让我们来分解这个命令:
wrk2 -t8 -c200 -d5m -R10000 http://…
wrk2: 压测工具的名称。
-t8: 使用 8 个线程(threads)来发起请求。这利用了多核 CPU 的能力,避免压测工具自身成为瓶颈。
-c200: 维持 200 个并发连接(connections)。这 200 个连接会均匀分布在这 8 个线程上,每个线程负责 25 个连接。
-d5m: 测试的持续时间(duration)为 5 分钟(minutes)。
-R10000: 这是 wrk2 的核心特性。尽力维持一个恒定的请求速率(Rate)在每秒 10000 个请求。如果服务器处理不过来,wrk2 会记录下延迟的增加,而不是像 wrk 那样无限制地提高速率。这对于观测固定负载下的延迟抖动至关重要。
将**被测的Nginx worker数量设置为1 (worker_processes 1;)**,并将其绑定到单个CPU核心 (worker_cpu_affinity 0001;)。这可以排除多核调度带来的干扰,让火焰图的结果更纯粹、更易于分析。
什么是协作式调度 (Cooperative Scheduling)?
与操作系统的抢占式调度(Preemptive Scheduling,即操作系统可以随时中断一个线程,把 CPU 时间给另一个线程)不同,OpenResty 的协程调度是非抢占式的。这意味着,一个协程一旦开始在 CPU 上运行,它就会一直运行下去,直到它自己主动放弃 CPU 控制权为止。
协程何时会“主动放弃”(Yield)?
协程只会在执行特定的、会导致阻塞的 I/O 操作时才会放弃 CPU。这些操作在 OpenResty 中被封装成了非阻塞 API,例如:
所有 ngx.socket.* 的网络操作(connect, receive, send 等)
ngx.sleep
ngx.req.read_body
ngx.timer.at 创建的定时器
其他所有基于 cosocket 的库(如 lua-resty-redis, lua-resty-mysql)的 I/O 相关方法。
fetch 和 release 函数的原子性
现在,我们来仔细审视 fetch 和 release 这两个函数的代码。它们内部执行的操作全都是纯粹的、在 CPU 上瞬间完成的计算,没有任何一个是会导致协程 yield 的 I/O 操作。所以从 从调度器的角度看 table 池 fetch 和 release 函数的执行是“原子”的
当协程A开始执行 _M.fetch 函数时,由于函数内部没有任何 yield 点,OpenResty 的调度器绝不会在函数执行到一半时暂停它,然后切换到协程B。协程A会完整地、不间断地执行完整个 _M.fetch 函数的所有代码行,然后才会轮到其他可能在等待的协程。
Table 的扩容(Rehash)机制
所以哈希满了或者数组满了都会触发扩容对吗?
完全正确。 当你试图向一个已经没有可用空间的数组部分或哈希部分插入新元素时,就会触发一次 rehash。
数组满了会把哈希的大小一块扩容吗?
可能会,但不一定。 rehash 是一个全局性的整理过程。当它被触发时(无论是因为数组部分满了还是哈希部分满了),Lua 会重新审视 table 中的所有元素,并根据当前元素的分布情况,计算出一个新的、最优的数组部分大小和哈希部分大小。
场景1:如果你的 table 只有数组元素,当数组满了,rehash 后只会扩大数组部分。
场景2:如果你的 table 既有数组元素又有哈希元素,当数组部分满了触发 rehash 时,Lua 可能会发现一些原本在哈希部分的整数键现在可以移到新的、更大的数组部分中,从而可能缩小哈希部分的大小。
核心思想:rehash 的目标是重新平衡两个部分,以达到最高效的内存使用和访问速度。
它们各自的扩容策略是什么?
Lua 的扩容策略通常是加倍增长。
当一个部分(例如数组部分)需要从大小 N 扩容时,Lua 会分配一个大小为 2 * N(或下一个最接近的2的幂次方)的新空间。
这么做的目的是为了摊销成本。虽然单次扩容是昂贵的,但由于每次都将容量加倍,所以需要扩容的频率会随着 table 的增长而指数级下降。平均下来,每次插入操作的摊销成本仍然是 O(1) 的。
Lua 还会努力保持数组部分的填充率高于50%,以避免浪费过多内存。如果填充率过低,rehash 时可能会缩小数组部分,将元素移到哈希部分。
a. 分配新空间之后会将数组和哈希部分的数据全都拷贝过去吗?还是原地扩容?
是“全部拷贝”,而不是“原地扩容”。
当 rehash 被触发时,Lua 会执行一个相当昂贵的操作:
分配新内存:在内存中申请一块全新的、更大的空间,用来存放新的 table 结构。
遍历旧数据:迭代遍历旧 table 中的每一个键值对。
重新插入:将每一个键值对重新计算哈希值,并插入到新的内存空间中。
释放旧内存:当所有数据都拷贝完毕后,释放旧 table 占用的内存。
table.new(2, 2) 分配的不是最终存储值的内存,而是管理这些值的“骨架结构”的内存。
具体来说,table.new(2, 2) 做了以下事情:
它创建了一个 table 结构,并为其数组部分预留了 2 个槽位 (slot)。
同时为哈希部分预留了 2 个节点 (node) 的空间。
每个“槽位”或“节点”的大小是固定的,它只需要存放一个键和一个指向值的指针(或者直接存放像数字这样的简单值)。
关键点:
值的内存是分开的:当你执行 t.name = “a_very_long_string” 时,字符串 “a_very_long_string” 本身占用的内存是在别处分配的。table 的哈希节点里只存放了键 “name” 和一个指向这个字符串的指针。
避免的是结构扩容:table.new 的目的是防止 table 的“骨架”(即存放槽位和节点的内部数组)因为不断添加元素而需要被销毁和重建。它并不知道你将要存入的值有多大,但它确保了有足够的“格子”来存放这些值的引用。
如何向面试官描述这个优化
你应该用 STAR 法则(Situation, Task, Action, Result)来构建一个有说服力的故事:
(Situation) “在对我们的限速组件进行压力测试时,我们通过火焰图分析发现,尽管核心逻辑很简单,但服务的 p99 延迟会出现不规律的尖峰,并且 CPU 时间有相当一部分(比如10-15%)消耗在了 LuaJIT 的垃圾回收函数 lj_gc_step 上。”
(Task) “我的任务是解决这个问题,消除延迟抖动,并降低 GC 带来的 CPU 开销,从而提升服务的整体性能和稳定性。”
(Action) “我定位到问题根源在于,每个请求都会创建多个临时的 Lua table 用于处理逻辑,在高并发下产生了海量的待回收对象。为了解决这个问题,我设计并实现了一个 worker 级别的 table 对象池。这个池化模块有几个关键设计:
分类管理:通过 tag 支持多种不同用途的 table 池,提高了复用率。
高效获取与归还:内部使用 LIFO 栈(后进先出)的数据结构,通过手动维护长度计数器(存在索引0的位置)来替代低效的 # 操作符,使得 fetch 和 release 操作都是 O(1) 复杂度。
避免内存抖动:归还 table 时,使用 LuaJIT 的 table.clear 函数。这个函数能高效清空 table 内容但保留其已分配的内存容量,这样下次取出使用时就不会因为添加元素而触发昂贵的 rehash 操作。
健壮性设计:设置了池子容量上限,防止内存无限增长;同时加入了一个自动重置机制,在操作数达到一定阈值后重建池子,防止潜在的长期内存泄漏。”
(Result) “这个优化上线后效果非常显著:火焰图中的 lj_gc_step 占比从15%下降到几乎不可见(低于2%),服务的 p99 延迟毛刺完全消失。在相同的硬件资源下,服务的极限 QPS 提升了约 15%,并且在高负载下表现得更加稳定。”
效率比新建临时 table 好吗?
在 OpenResty 这种高并发场景下,好得多,而且是质的提升。
新建临时表 (local t = {}):这个操作涉及 内存分配 + 后续可能的多次 rehash + 最终的垃圾回收 (GC)。当每秒有数万个请求时,就会产生数万个需要被 GC 清理的临时对象。GC 的运行会暂停正常的逻辑执行,消耗 CPU,并导致服务延迟出现“毛刺”(spikes)。
复用 Table:这个模式将成本平摊了。在 worker 启动时,池中可能会创建几十个 table。在请求处理中,你只是从池中借用和归还,几乎没有内存分配和 GC 的开销。代价仅仅是 table.clear 的一次遍历操作,这个开销远小于“分配+GC”的组合拳。
Lua Table 的默认大小与扩容机制
默认大小:当你创建一个空表 local t = {} 时,它的数组部分(array part)和哈希部分(hash part)的初始分配大小都是 0。它不预占任何空间。
扩容机制:Lua 的 table 在内部被实现为数组和哈希表的混合体。
触发:当你向表中插入一个新元素,而此时表的数组部分或哈希部分已经没有可用空间时,就会触发一次“rehash”(重新哈希)过程。
过程:这个过程非常昂贵。Lua 会计算出一个新的、更大的尺寸,然后分配一块全新的内存空间。接着,它会遍历旧表中的所有键值对,重新计算它们的哈希值,并将它们插入到新的内存空间中。最后,释放旧的内存。
数组部分的策略:Lua 会尝试将整数键(尤其是从1开始的连续整数)放入数组部分。扩容时,它会寻找一个最优的2的幂次方作为新的数组大小,以保证至少50%的空间利用率。
性能影响:在循环中不断向一个未预分配的 table 中插入元素,会导致多次、连续的 rehash,产生巨大的 CPU 开销。这在火焰图上会体现为 lj_tab_resize 或 rehashtab 函数占用很高的 CPU 比例 。
支柱一:执行服务契约
此支柱关注的是公平性、安全性及商业协议的执行。它旨在回答诸如“该用户是否遵守了其订阅套餐的规定?”或“此IP地址是否在尝试进行暴力破解攻击?”等问题。这本质上是关于管理客户端行为与策略执行的领域,其核心工具是基于速率的限制 。
支柱二:维护系统稳定性
此支柱关注的是后端基础设施的物理和逻辑限制。它旨在回答一个核心问题:“我们的系统(包括CPU、内存、数据库连接等)当前是否有足够资源来处理下一个请求,而不会降低对所有用户的服务质量?”这本质上是关于保护内部系统状态和防止过载的领域,其核心工具是基于并发连接的限制 。
resty.limit.req 是实现第一支柱的工具,它通过控制请求的到达速率来执行服务契约 。
resty.limit.conn 则是实现第二支柱的工具,它通过控制正在处理中的活跃请求数量来保护系统容量 。
因此,选择哪种限流方式,并非一个简单的技术选型问题,而是一个战略性的架构决策。这个决策反映了当前最主要的保护目标:是优先执行面向客户端的策略,还是优先保障内部系统的健康状态。许多技术讨论之所以陷入僵局,往往是因为在比较算法优劣之前,未能清晰地定义其保护目标。limit.req 的关注点向外,审视客户端行为是否符合既定策略;而 limit.conn 的关注点向内,审视系统当前的负载和处理能力。这一根本性的区别为整个决策过程提供了清晰的框架。
将请求想象成水流,它们以不确定的速率注入一个桶中,而桶的底部有一个固定大小的孔,水(处理后的请求)以恒定的速率从中漏出。桶的容量则代表了系统能缓冲的突发请求量。
rate 参数定义了“漏水”的速率,即系统期望处理请求的平均速率(例如,每秒200个请求)。
burst 参数定义了“桶”的容量。当请求到达速率超过 rate 但桶内尚有空间时,这些超出的请求会被“存”在桶里,并通过延迟处理的方式(ngx.sleep)来平滑流量,使其最终符合 rate 定义的速率 。
当请求速率超过 rate + burst 的总和时,意味着桶已经溢出,后续的请求将被立即拒绝,通常返回503状态码 。
该模块依赖 lua_shared_dict 在Nginx的所有worker进程之间共享状态数据(如每个key的最后请求时间、桶中的请求数量),从而实现全局一致的限制 。
2.2 核心应用场景
基于速率的限制在以下场景中表现出色:
执行API配额和服务等级:这是其最主要的应用场景。例如,为“黄金”等级用户设置500 RPS的速率限制,而为“免费”等级用户设置10 RPS的限制。这直接将业务规则转化为技术实现 。
防止恶意行为:通过对特定IP地址施加严格的速率限制(如每分钟5次登录尝试),可以有效阻止密码爆破、内容抓取或简单的DoS攻击 。
保障公平的资源分配:在多租户系统中,通过租户ID进行速率限制,可以确保某个过度活跃的租户不会因其巨大的请求量而耗尽所有处理能力,从而影响其他租户的服务质量 。
阿喀琉斯之踵:“固定契约”问题
速率限制最根本的局限在于它对后端服务的健康状况“一无所知”。一个100 RPS的限制,无论后端服务的响应时间是10毫秒还是1000毫秒,都会被同样地执行。
【好用的 利特尔法则】
设想一个场景:一个API设置了100 RPS的速率限制。正常情况下,其后端响应延迟为50毫秒。根据利特尔法则(Little’s Law),即 系统并发数 = 到达速率 × 平均响应时间,系统在稳态下的并发数大约为 100×0.05=5 个活动请求。然而,如果后端数据库出现问题,导致响应延迟飙升至800毫秒,速率限制器仍然会允许100 RPS的请求进入系统。此时,新的并发数将变为 100×0.8=80 个活动请求。并发负载的16倍增长极有可能压垮后端服务,引发雪崩效应,尽管从客户端的角度看,它们完全遵守了服务契约 。
此外,burst 参数的设置本身就是一个在延迟和可用性之间的权衡。较大的 burst 值可以吸收更多的流量尖峰,减少请求被拒绝的概率,但这是以增加延迟为代价的。在OpenResty的非阻塞模型中,ngx.sleep 虽然不会阻塞操作系统线程,但会持有Lua协程和相关的请求状态,这实际上占用了Nginx worker的一个处理“槽位” 。因此,在流量高峰期,一个大的 burst 值可能导致大量协程处于休眠状态,消耗内存并可能在延迟显著时耗尽worker资源。相反,一个小的 burst 值虽然对突发流量的容忍度较低,但能更快地拒绝超额请求,从而保护网关自身的资源。
基于并发的限制与 resty.limit.conn
本节将并发限制定位为保障系统稳定性和韧性的首要工具,并将其直接与后端资源管理联系起来。
并发模型:系统负载的直接代理
与速率限制不同,并发限制不关心请求在单位时间内的到达频率,它只关心在任何一个精确时刻,有多少个请求正在被系统处理。这个数量是衡量系统有限资源(如工作线程、数据库连接池、内存缓冲区)负载的直接代理 。
resty.limit.conn 的工作机制如下:
它同样使用 lua_shared_dict 为指定的key维护一个共享计数器。
当请求到达时,调用 lim:incoming(key) 会使计数器加一,并检查是否超过了设定的限制 。
至关重要的一点是,它要求在请求处理完成后的某个阶段(如 log_by_lua)必须调用 lim:leaving(key) 来将计数器减一 。这是与 limit.req 的一个关键区别,后者在 access 阶段是一次性的“即检即忘”操作。
与 limit.req 类似,它也可以对超过并发数和突发限制的请求进行延迟或拒绝处理。
核心应用场景
并发限制在以下场景中至关重要:
保护资源受限的后端服务:这是最典型的例子。如果一个数据库实例最多只能处理50个并发连接,那么在访问该数据库的API端点上设置一个40的并发限制,就可以从根本上防止数据库因连接过多而过载,无论请求速率或延迟如何变化 。
实现系统级的反压(Back-Pressure):当某个下游微服务响应变慢时,处理这些请求的时间会相应延长。由于 leaving 的调用被推迟,并发计数会自然地保持在高位,这会自动减缓新请求通过 incoming 的速率。这种机制形成了一个自适应、自调节的系统,有效防止了故障的连锁反应(即雪崩效应)。
隔离重负载端点:一个用于生成复杂报表的端点可能会被限制为仅有2个并发,而同一服务器上用于获取简单数据的端点可以拥有100个并发。这种策略可以防止重负载端点耗尽系统资源,从而导致轻量级请求被“饿死”。
并发限制的盲点
并发限制也并非万能。它的主要盲点在于“快客户端问题”。单独的并发限制无法阻止单个客户端独占整个请求流。假设并发限制为50,如果一个客户端发出的请求能在1毫秒内完成,理论上该客户端可以通过极快地占用和释放并发“槽位”来达到非常高的请求速率,这可能会导致其他处理较慢的正常客户端请求被排挤。它保护了服务器,但不能保证客户端之间的公平性。
并发限制的真正威力在于它隐含地实施了一个由系统实际性能决定的速率限制。这同样可以用利特尔法则来解释:平均并发数(L)= 平均到达速率(λ)× 平均响应时间(W)。当使用 resty.limit.conn 时,我们实际上是固定了 L(并发数上限)。系统的实时性能决定了 W(延迟)。因此,公式可以重排为 λ = L / W。这个重排后的公式揭示了一个深刻的机制:如果后端服务变慢,W 会增加;由于 L 是固定的,系统所能承受的有效速率 λ 将自动下降。这正是反压机制的数学基础,也说明了并发限制为何具有天然的自适应性,使其成为构建韧性系统的关键。形成一个自适应、自调节的系统,有效防止故障的连锁反应
1 | “快客户端问题”的深度理解 |
4.1 核心问题:保护的是“契约”还是“系统”?
决策的核心启发点非常明确:
如果目标是执行业务规则、API配额、或防止客户端滥用,那么首选是基于速率的限制。
如果目标是确保服务器稳定性、防止资源耗尽、或构建一个能适应负载变化的韧性系统,那么首选是基于并发的限制。

设计多维度限流组件
混合方法:分层部署速率与并发控制
最稳健的系统通常不会在两者之间做非此即彼的选择,而是策略性地将它们分层部署。一个请求的生命周期中可能会经过多重检查。resty.limit.traffic 模块正是为此而生,它可以作为一个聚合器,组合多个限流器的实例 。
一个推荐的架构蓝图如下:
全局/边缘层:基于IP地址 ($binary_remote_addr) 设置一个非常宽松的全局速率限制。这是抵御大规模DDoS攻击的第一道防线,是一个粗粒度的安全网。
认证/策略层:基于用户或API密钥进行速率限制 (resty.limit.req),以执行业务逻辑和保障公平性 。这一层保护的是“服务契约”。
应用/端点层:针对每个端点所消耗的特定资源,设置相应的并发限制 (resty.limit.conn)。这一层保护的是“后端系统”。
对于大数据量/长响应时间的请求(如报表生成、文件上传):
主要策略:严格的并发限制。这类请求的危险之处在于它们会长时间占用系统资源。因此,它们对系统的主要影响是并发压力,而非请求频率。
实现:使用 resty.limit.conn,并为该端点设置一个特定的key(例如,key = “report_generation”)。根据后端服务的承载能力,设置一个非常低的并发上限(例如,5-10)。
理由:这种方式可以防止少数几个慢请求耗尽所有worker进程或数据库连接,从而导致对所有其他用户的拒绝服务。速率限制对此类请求几乎无效,因为危险的不是它们的到达频率,而是它们同时运行的数量。
对于普通的、快速响应的请求(如API读取、状态检查):
主要策略:基于客户端的速率限制。这类请求的危险在于其巨大的聚合数量。它们的主要威胁是来自单一客户端的流量洪水。
实现:使用 resty.limit.req,并以用户ID或API令牌作为key。设置一个合理的RPS限制(例如,100 req/sec),以确保公平使用。
理由:并发限制在此处效果不佳,因为请求处理时间很短,很快就会释放并发槽位。而速率限制直接解决了来自行为异常或恶意客户端的高频访问威胁。
API密钥/用户ID 作为限速键 和 执行用户特定配额和保障公平性 有很强的关系。
演讲
“在OpenResty中选择速率限制还是并发限制时,核心的架构决策点在于您试图保护的对象。速率限制,通过resty.limit.req和漏桶算法实现,其目标是保护‘服务契约’——即执行API配额和保障客户端之间的公平性。而并发限制,通过resty.limit.conn实现,其目标是保护‘系统容量’——即防止后端服务因资源耗尽而崩溃。它们解决的是两个不同的问题,最稳健的系统设计通常会将两者分层结合使用。”
核心论证:一个叙事性示例
“我们可以设想一个API包含两个端点:一个快速的/status状态检查接口,和一个缓慢的/generate_report报表生成接口。对于/status,其主要威胁是单个客户端发起的海量请求,因此我会选择基于用户ID的速率限制来保障公平使用。而对于资源密集型的/generate_report,其威胁是少数几个并发请求就可能耗尽数据库连接。因此,这里的明确选择是严格的并发限制,可能低至5个并发,以保护后端资源。对报表接口使用速率限制是无效的,因为危险的不是请求的频率,而是并发的负载。”
为了给面试官留下深刻印象,可以补充以下“加分项”:
提及自适应与动态限制:“静态限制虽然强大,但更高阶的方案是动态限制。例如,OpenResty的商业产品提供了lua-resty-limit-traffic-dynamic模块,它可以根据Nginx worker的CPU使用率动态调整速率限制,从而使限流策略从固定的契约演变为能适应网关自身健康状况的动态策略 。”
提及自适应并发:“类似地,我们也可以实现由Netflix首创的自适应并发控制。系统不再使用固定的并发上限,而是持续测量请求延迟,并在延迟超过预设阈值时自动降低并发限制。这创造了一个真正具备韧性的、自愈的系统,能在下游服务性能下降时自动施加反压 。”
并发连接模块中的反馈设计
这行代码 self.unit_delay = (req_latency + unit_delay) / 2 的理论基础是控制理论中的反馈控制系统(Feedback Control System),其具体算法是一种简化的指数移动平均(Exponential Moving Average, EMA)。
让我们分解一下:
req_latency (输入信号/观测值):这是实际测量到的后端服务处理一个请求所花费的时间。它是来自真实世界(后端系统)的反馈信号。
unit_delay (内部状态/控制量):这是限速器当前认为的、应该对请求施加的“单位延迟”基准。它是限速器试图控制系统节奏的输出信号。
(a + b) / 2 (控制器算法):这是一个平滑算法。它没有直接用新的 req_latency 覆盖旧的 unit_delay,因为那样会导致系统因单次的延迟抖动而产生剧烈震荡。相反,它取了新观测值和旧状态值的平均数,这使得 unit_delay 的变化更加平滑、更能抵抗噪声。这本质上是一个 alpha 值为 0.5 的指数移动平均。
核心思想:这个限速器不是一个静态的、一成不变的“门卫”,而是一个动态的、自适应的“交通警察”。它通过持续观察后端服务的“路况”(req_latency),来动态调整下一个“红绿灯”的时长(unit_delay)。
这个设计的深刻含义(为什么这么做?)
这个设计的目的是让限速器具备弹性和韧性(Resilience),实现一种反向压力(Backpressure)机制。
当后端服务健康时 (低 req_latency):
如果后端响应很快,req_latency 的值会很小。
self.unit_delay = (一个很小的值 + unit_delay) / 2 的结果会不断拉低 unit_delay。
效果:限速器会自动变得“宽容”,缩短对新请求施加的延迟,从而自动提升系统的吞吐量,充分利用健康的后端资源。
当后端服务过载或出现问题时 (高 req_latency):
如果后端开始变慢,req_latency 的值会增大。
self.unit_delay = (一个很大的值 + unit_delay) / 2 的结果会推高 unit_delay。
效果:限速器会自动变得“严格”,延长对新请求的延迟,主动减慢请求进入的速度。这就像在高速公路入口处进行交通管制,防止更多车辆涌入已经拥堵的路段。这是一种非常重要的自我保护机制,可以:
给后端服务一个“喘息”的机会,使其有可能从高负载中恢复。避免整个系统的雪崩效应和级联故障。防止因后端响应缓慢导致网关层持有大量连接,耗尽自身资源。(网关层资源)
如何向面试官描述?
(引出亮点)
“我们这个限速组件最核心的设计之一,是它不仅仅是一个静态的速率限制器,更是一个自适应的负载调节器。它能够根据后端服务的实时健康状况,动态地调整限流策略。”
(解释机制)
“具体来说,在每个请求处理完成并离开(leaving)限速器时,我们会测量并传入它在后端真实消耗的时间,也就是 req_latency。然后,我们利用一个指数移动平均算法来更新限速器的核心参数‘单位延迟’,代码就是 self.unit_delay = (req_latency + self.unit_delay) / 2。”
(阐述理论与价值 - 这是关键)
“这行代码的背后,其实是一个反馈控制的设计思想。它建立了一个从‘后端延迟’到‘入口速率’的 反向压力(Backpressure) 闭环。
当后端服务健康、响应快时,这个平均值会自动拉低我们的‘单位延迟’,从而提升整个链路的吞吐量上限。
而一旦后端出现性能瓶颈、响应变慢,req_latency 的增大会自动推高‘单位延迟’,使我们的限速器主动减速,扮演‘减震器’的角色,保护后端服务不被突发流量冲垮,避免了级联故障的风险。
这种设计,让我们的网关从一个被动的执行者,变成了一个具备初步智能、能够动态适应系统变化的调节者,极大地提升了整个系统的韧性(Resilience)和稳定性。”
独立设计并交付了基于 OpenResty 的高性能限速组件,以解决核心云负载均衡(CLB)在流量突增场景下的服务稳定性问题。通过实现分层限速算法、优化 LuaJIT 运行时性能(对象池化、JIT 热路径修复),最终将系统吞吐能力提升超 30%,并将核心处理延迟稳定在 2ms 以内,有效保障了多租户环境下 CLB 服务的SLA。
项目:高可用网关限速组件
• 为解决核心云负载均衡(CLB)API网关在流量洪峰下的高负载与成功率下降问题,主导研发了一套动态、多维度的限速系统。该系统通过保障平台整体稳定性,有效防止了级联雪崩故障。
• 性能优化与延迟控制:通过设计并实现 Lua table 对象池,将高频对象的创建转化为复用,显著降低 GC 压力,成功消除 p99 延迟毛刺(从 >50ms 降至 <5ms),并使单实例 QPS 提升 15%。
• 吞吐能力突破:利用火焰图对 CPU 热点进行剖析,定位并解决因使用 NYI(Not Yet Implemented)原语导致的 JIT 编译中断问题,通过替换为 FFI 实现,使核心模块的 CPU 效率提升 15%,进一步将系统总吞吐量提升至新水平。
这两种重构方案都遵循了一个核心逻辑:从业务问题出发(服务不稳定),到技术方案落地(构建限速组件),再到极致的性能优化(GC和JIT调优),最终回归到可量化的业务成果(稳定性保障、吞吐量提升、延迟降低)。
问题根源:GC 引发的 P99 延迟毛刺
在高吞吐量的 OpenResty 服务中,如果每个请求都频繁创建和销毁 Lua table(例如,用于存储请求上下文),会给 LuaJIT 的垃圾回收器(Garbage Collector, GC)带来巨大压力 。尽管 LuaJIT 的 GC 是增量式的,但在高负载下,其回收周期仍可能导致毫秒级的、非确定性的停顿。对于一个追求低延迟的网关服务而言,哪怕是 20-50ms 的停顿也会在监控图上表现为一次剧烈的 P99 延迟毛刺(Tail Latency Spike),严重影响服务的可预测性 。
解决方案:自定义轻量级对象池
通过实现一个工作在 Nginx Worker 级别的 Lua table 对象池,可以将高频的“创建-销毁”模式转变为“获取-归还”的复用模式。其生命周期如下:
获取对象 (pool.get):当请求开始时,从池中(如一个简单的 table 或链表实现的 freelist)获取一个预先分配好的、干净的 table。如果池为空,则创建一个新 table。
释放对象 (pool.release):当请求结束时,清理该 table 的内容,并将其归还到池中,而不是等待 GC 回收。
这种以空间换时间的设计,是解决 GC 抖动、平滑服务延迟的经典手段 。
优化前现象:“在单实例 20k QPS 的持续压测下,我们观察到系统的 p50 延迟维持在 3ms 左右,但 p99 延迟每隔数秒就会飙升至 50ms 以上。通过 stapxx 生成的火焰图或 OpenResty XRay 等工具进行分析,发现延迟毛刺与 GC 活动高度相关,CPU 时间在这些尖峰时刻显著消耗在 GC 相关的状态上 。”
优化后成果:“实施对象池后,请求处理路径上新 table 的创建率下降了超过 99%。压测结果显示,p99 延迟毛刺被完全消除,稳定在 5ms 以下。由于 GC 开销大幅降低,CPU 的有效利用率提升,使得单实例在相同的 CPU 负载下,可承载的最大 QPS 提升了 15%。”
问题根源:NYI 导致的性能“断崖”
LuaJIT 的核心优势在于其基于追踪(Trace-based)的 JIT 编译器,它能将频繁执行的代码路径(“热路径”)编译成高度优化的本地机器码 。然而,某些 Lua 内置函数或特性在 JIT 编译器中尚未实现(Not Yet Implemented, NYI)。当 JIT 追踪器在热路径上遇到 NYI 原语时,会放弃对该路径的编译,导致这部分关键代码回退到性能低几个数量级的解释模式执行,形成隐蔽的性能瓶颈 。
诊断工具:火焰图分析
火焰图(Flame Graph)是由 Brendan Gregg 推广的一种性能可视化工具,非常适合用于定位 CPU 性能热点 。
具体诊断实例:“在进行压力测试时,我们发现组件的 CPU 使用率超出预期。通过 stapxx 生成的 CPU 火焰图显示,图顶端出现了宽而平的‘平台’,堆栈信息指向 lj_BC_FUNCC 等解释器相关的函数。这表明,尽管相关代码位于一个紧凑的循环中,但大部分 CPU 时间都消耗在了解释执行字节码上,这是 JIT 编译失败的典型特征。”
修复方案:具体的 NYI 替换实例
场景设定:“在我们的核心限速逻辑中,需要从一个复杂的请求头中解析并替换特定模式的字符串。最初的实现使用了 string.gsub(header, pattern, repl_func),即 string.gsub 的第三个参数为一个函数。这是一个已知的 NYI 特性 。”
解决方案 1 (Idiomatic OpenResty):“我们将 NYI 调用替换为 OpenResty 提供的、对 JIT 友好的 ngx.re.gsub API。关键在于,我们传递了 ‘jo’ 选项,这不仅开启了 PCRE 库自身的 JIT 编译,也确保了该调用能够被 LuaJIT 的追踪器顺利地进行编译 。”
解决方案 2 (极致性能):“为了追求极致性能,我们利用了 LuaJIT 强大的 FFI(Foreign Function Interface)库 。我们编写了一个小型的、高度优化的 C 函数来完成特定的字符串处理,并通过 FFI 从 Lua 中调用。JIT 编译器能够内联 FFI 调用,使得 Lua 与 C 之间的交互开销极小,整个热路径得以完全编译成机器码。”
优化效果的量化阐述
优化前现象:火焰图显示 CPU 主要消耗在解释器上。
优化后成果:“优化后的火焰图显示,原先宽阔的解释器平台消失了,取而代之的是与 JIT 编译追踪相关的函数栈(如 lj_trace_exit)。这一处修改使得该组件处理单个请求的 CPU 周期减少了约 15%,直接转化为在同等硬件资源下 15% 的吞吐量提升。” 这一优化过程与 Cloudflare 等公司分享的真实性能调优案例高度一致 。
GC 压力高,频繁触发变为 压力极低,对象复用率大于 99,降低 cpu 开销,为提升吞吐量奠定基础,
值得注意的是,这两项优化之间存在着内在的逻辑联系。修复 NYI 问题提升了 CPU 效率,从而推高了系统的吞-吐能力。而更高的吞吐量反过来又会加剧 GC 的压力,这使得对象池化的优化变得更为关键和必要。将此作为两步走的优化策略进行阐述(“首先,我们通过修复JIT编译问题释放了CPU潜力,但这暴露了GC成为新的瓶颈;随后,我们通过对象池化解决了GC压力,最终实现了整体性能的大幅提升”),能够展现出你系统化、全局性的性能调优思路。

保障原子性:“预检查-提交-回滚”模式的价值
核心问题:多限速器场景下的一致性挑战
当一个请求需要同时满足多个维度的限速规则时(例如,按接口、按AppId、按租户),一个简单的串行检查并扣减计数器的方案是不可靠的。试想,如果请求通过了限速器A并扣减了其计数,但随后被限速器B拒绝,那么限速器A的状态就变得不一致,导致资源被错误地“预占”,影响了后续请求的公平性。
解决方案:一种事实上的两阶段提交(2PC)模式
你可以将你的“预检查-提交-回滚”模式,用分布式系统中的“两阶段提交”(Two-Phase Commit, 2PC)思想来进行类比和阐述,这能立刻提升你设计方案的理论高度 。尽管它发生在一个进程内,但其保证数据一致性的逻辑是相通的。
第一阶段:准备阶段 (Prepare / 预检查)
协调逻辑遍历所有需要应用的限速器。
对每个限速器,原子地检查其当前计数值是否足以满足本次请求(即“投票”)。在这一步,只检查,不修改真实计数值。
如果所有限速器都“投票同意”(即都有余量),则进入第二阶段。
第二阶段:提交/中止阶段 (Commit / 回滚)
提交 (Commit):如果所有限速器都准备就绪,协调逻辑会向所有限速器发出“提交”指令,此时每个限速器才真正地原子地执行扣减操作。
中止 (Abort / 回滚):如果在准备阶段有任何一个限速器“投了反对票”,协调逻辑则会发出“中止”指令。由于在第一阶段没有修改任何真实状态,系统自然地回滚到了初始状态,无需额外的补偿操作。
“这个模式的核心优势在于原子性(Atomicity) 。它确保了对于任何一个请求,要么所有相关的限速规则都被成功应用,要么一个都不应用。这彻底避免了因部分规则失败而导致的系统状态不一致问题,保证了限速策略的正确性和公平性。在一个复杂的多租户平台上,这种事务性的保障是至关重要的,它能防止因放行的请求数量与限速值出现大的偏差。”
超越速率限制:并发控制的必要性
你需要向面试官阐明速率限制(Rate Limiting)和并发限制(Concurrency Limiting)的本质区别:
速率限制:控制单位时间内的请求数量(RPS),主要用于防止客户端的请求洪峰。
并发限制:控制系统中“正在处理”的请求总数(in-flight requests),主要用于保护系统自身及下游服务,防止因处理缓慢导致的请求堆积和资源耗尽 。
即使请求速率不高,如果后端服务响应变慢,并发数也会持续累积,最终压垮系统。因此,一个鲁棒的网关必须同时具备这两种保护机制。
你的并发限制器设计中最亮眼的部分是其“反馈控制”思想,这是一个高级的系统设计理念,深受 Netflix、Uber 等业界领导者的实践启发 。
反馈闭环 (Feedback Loop) 的构建:可以作为未来扩展点
测量 (Measure):持续测量能够反映系统健康状况的代理指标。最佳指标是请求的往返延迟(RTT)或处理时延。延迟的持续上升是系统过载和请求开始排队的最早、最灵敏的信号 。
比较 (Compare):将当前的平滑后延迟(如 p90 延迟)与一个基线延迟(如系统在低负载下的 minRTT)进行比较。两者之间的比率或梯度(gradient)可以量化当前的排队压力。
行动 (Act):基于比较结果,通过类似 TCP 拥塞控制的算法(如 AIMD:加性增,乘性减)来动态调整并发限制的阈值。
如果当前延迟接近基线,说明系统健康,可以缓慢地增加并发限制(加性增),以探索更高的系统容量。
如果当前延迟显著超过基线,说明系统过载,必须果断地、大幅地降低并发限制(乘性减),主动拒绝新请求(load shedding),给系统恢复的时间。
“我们的并发限制器并非一个静态配置的数值,而是一个自适应的、闭环的反馈控制系统。它通过实时监控下游服务的响应延迟,来动态判断系统的健康状况。一旦检测到延迟上升——这是系统过载的关键前兆——它会自动收紧并发窗口,减少允许进入系统的请求数量。这种机制使网关具备了自我调节和快速恢复的能力,能有效保护自身及下游服务免受因慢查询、下游故障或流量突增导致的级联雪崩。这使得我们的系统更加坚韧(Resilient),是现代可靠性工程的核心实践。”
这种分层防御的架构思想,即用漏桶算法平滑入口流量(防“快”),再用自适应并发控制保护系统内部(防“慢”),共同构成了一个纵深防御体系。清晰地阐述这一整套逻辑,将充分展示你对高可用系统设计的深刻理解和前瞻性思考。
GC 性能调优: 自主设计并实现了 Lua table 对象池,将高频临时对象的 GC 压力降低了约 70%,成功消除了压测场景下的 P99 延迟毛刺(由 50ms+ 降至 5ms 内),最终为整体服务带来了 7% 的 QPS 提升。
最初的 15% 是我们在早期压测中得到的数字,后来经过更严谨和多场景的回归测试,我们发现 7% 的 QPS 提升 是一个更稳定和可复现的指标。但比 QPS 提升更重要的,是它解决了我们最头疼的 ‘P99 延迟毛刺’ 问题。”
现象描述(优化前):
“在优化前,我们通过压测发现,服务的平均延迟很低,大概在 5ms 左右,但 P99 延迟(即 99% 的请求延迟)会周期性地出现高达 50ms 甚至 100ms 的尖峰。这意味着每 100 个请求里,就有 1 个请求的响应时间会突然变得非常慢。这种不稳定的延迟对于上游服务是不可接受的。我们通过 OpenResty XRay 和 SystemTap 等工具分析发现,这些延迟尖峰与 LuaJIT 的 GC(垃圾回收)活动高度相关 。”问题根源:
“我们的限速逻辑在每次请求时,都需要创建一些临时的 table 来存储请求的上下文信息或解析后的规则。在高 QPS 场景下,这意味着每秒会产生数万甚至数十万个需要被回收的 table 对象 。当这些临时对象累积到一定程度,就会触发 LuaJIT 的 GC 扫描和清理。尽管 LuaJIT 的 GC 是增量式的,但在高压力下,密集的 GC 操作仍然会短暂地暂停 Lua VM 的执行,从而导致了我们观测到的延迟毛刺。”解决方案与成果(优化后):
“为了解决这个问题,我设计并实现了一个基于 lua-tablepool 思想的 table 对象池 。核心思想是:在请求开始时,从一个 worker 级别的池中 fetch 一个‘干净’的 table;在请求结束的 log 阶段,清空这个 table 并 release 回池中,而不是让 GC 回收它。这样,table 对象在 worker 的生命周期内被高度复用。”
“这个优化带来了两个关键成果:
第一,P99 延迟毛刺被彻底‘削平’了。优化后,P99 延迟稳定在 5ms 以内,服务的可预测性大大增强。
第二,CPU 效率提升。由于 GC 活动大幅减少,原本用于垃圾回收的 CPU 周期被释放出来,可以用于处理更多的业务请求。这直接转化为了 7% 的 QPS 净提升。所以,这个优化的核心价值在于提升服务的稳定性,QPS 提升则是其带来的一个额外收益。”
JIT 编译优化: 运用火焰图对性能热点进行深度剖析,定位并消除了因 table.insert 等 NYI (Not Yet Implemented) 原语导致的 JIT 编译中断问题。优化后,核心代码路径的 CPU 消耗降低了 35%,组件吞吐量提升了 12%,在高并发压测下,组件自身延迟稳定在 2ms 以内。
一个更准确的数字是吞吐量提升了 12%。这个问题是在对限速计数逻辑进行性能剖析时发现的。”
具体 NYI 实例:
“我们遇到的典型 NYI 原语是 table.insert 。在限速逻辑的一个核心热点函数中,我们需要记录最近几次请求的时间戳,当时的代码实现是这样的:table.insert(timestamps, ngx.now())。这个函数被每个请求高频调用。”火焰图上的表现(优化前):
“在优化前的火焰图 上,我们观察到两个非常典型的现象:
热点路径中断:本应被 JIT 编译的核心函数 check_and_record(),其栈帧上方出现了一个非常宽的 lj_vm_interpret 栈帧,这表明执行流从 JIT 编译的代码回退到了解释器模式。这几乎占用了这个函数 40% 的 CPU 时间。
Trace Abort 证据:与此同时,通过 luajit -jv 工具分析,我们明确看到了针对 check_and_record() 函数的 TRACE 2 abort… NYI: bytecode 51 (FNEW) 或类似的踪迹中止日志 。这证实了 table.insert 的调用(或其他相关操作)破坏了 JIT 的跟踪编译 。”
- 解决方案与火焰图变化(优化后):
“我的优化方案是,放弃使用 table.insert,改为预分配 table 并通过索引赋值。具体做法是:
使用 table.new(N, 0) 预先创建一个固定大小的 table,其中 N 是我们需要记录的时间戳数量 。
使用一个循环指针(current_index = (current_index % N) + 1)来更新时间戳数组,代码从 table.insert(t, val) 改为 t[current_index] = val。”
“这个改动虽小,但在火焰图上的变化是颠覆性的:
解释器栈帧消失:优化后,之前那个宽大的 lj_vm_interpret 栈帧完全消失了。
出现 JIT Trace:取而代之的是,check_and_record() 函数的调用栈顶端出现了一个 trace#N 伪栈帧 。这明确表示整个热点函数现在已经被 LuaJIT 完全跟踪并编译成了高效的机器码。
CPU 占用率下降:最直观的结果是,在同等请求压力下,执行 check_and_record() 函数的那个 Nginx worker 进程的 CPU 占用率整体下降了约 35%。这些节省下来的 CPU 资源使得我们能够处理更多的请求,最终带来了 12% 的吞吐量提升。”
速率限制 (Rate Limiting):其目标是控制单位时间内的请求数量,例如每秒请求数 (RPS)。速率限制对于约束客户端行为、防止滥用非常有效。然而,它对服务的真实健康状况是“盲目”的。一个处于降级状态的服务,即使在很低的 RPS 下也可能过载。OpenResty 的 lua-resty-limit-traffic 库提供了此类功能 。
并发限制 (Concurrency Limiting):其目标是控制同时在处理的、在途的 (in-flight) 请求总数。这个指标与服务消耗的资源(如 CPU、内存、线程)直接相关。利特尔法则 (Little’s Law) 揭示了这一内在联系 。因此,并发限制是保护服务免于因工作积压而崩溃的正确模型。Netflix 等公司的实践明确指出,应关注并发数而非 RPS,因为并发数能更准确地反映系统的负载压力 。
自适应并发限制器的核心是一个经典的反馈控制循环 (Feedback Loop)。它持续地测量系统状态,将其与期望状态比较,并根据偏差采取纠正措施。其根本原则在于,将延迟视为系统健康状况最灵敏的“金丝雀”。
在系统因过载而开始大量返回错误或超时之前,其内部的工作队列会率先开始积压。这种排队现象最直接、最灵敏的外部表现就是请求处理延迟的上升 。因此,延迟是系统饱和的领先指标 (leading indicator)
利特尔法则,即 L=λW(平均并发数 = 平均到达率 × 平均延迟),为这一观察提供了数学依据。该定律表明,在给定的请求到达率下,延迟的增加必然意味着系统内并发请求数的增加,反之亦然 。这从理论上验证了通过监控延迟来控制并发的有效性。
测试
GC 调优: 设计并实现Lua table 对象池,将高频临时对象的GC 压力降低了约70%,成功消除了压测场景
下的P99 延迟毛刺(由50ms+ 降至5ms),最终为整体服务带来了7% 的QPS 提升。
JIT 优化: 运用火焰图定位并优化了因NYI 原语导致的JIT 热代码编译中断问题,核心代码CPU 消耗降低了35%,吞吐量提升了12%,压测组件自身延迟2ms 以内;
假设你想测试你的服务在 20,000 QPS 的负载下,响应延迟是多少。
4个线程, 200个连接, 压测30秒
wrk -t4 -c200 -d30s http://your-service/api
wrk 会拼尽全力去发请求。如果服务处理能力强,它可能会达到 30,000 QPS;如果服务在 15,000 QPS 时就开始变慢,wrk 发送请求的速度也会跟着变慢。它测出的平均延迟可能看起来还不错,但它忽略了那些因为系统繁忙而“本应发送但没能及时发送”的请求所产生的延迟。
额外增加 -R20000 参数,代表 Rate = 20000 req/s
wrk2 -t4 -c200 -d30s -R20000 http://your-service/api
wrk2 会像节拍器一样,严格维持每秒发送 20,000 个请求。如果服务处理不过来,请求就会在客户端排队,wrk2 会把这个排队时间也算进延迟里。因此,它给出的延迟分布报告(特别是 p99, p99.99)能极其真实地反映用户在 稳定高并发 场景下感受到的最坏情况。
即使后端响应时长可忽略,access 阶段的 ngx.exit 依然比走完整个流程要快。
原因在于:请求处理阶段的提前中断 (Short-circuiting the Request Processing Phases)。
Nginx 处理一个 HTTP 请求,会像流水线一样经过一系列预设的阶段 (Phases)。我们只列出关键的几个:
post-read
server-rewrite
find-config
rewrite
post-rewrite
preaccess
access (你的 access_by_lua 在这里运行)
post-access
content (这是最关键的一步,由 proxy_pass 或 content_by_lua 等模块处理)
log
现在我们来对比“拒绝”和“放行”两条路径的差异:
路径一:拒绝请求 (The Fast Path)
请求进入流水线,走到 access 阶段。
你的 access.lua 脚本开始执行限速逻辑。
逻辑判断需要拒绝,执行 ngx.say(…) 和 return ngx.exit(code)。
关键点: ngx.exit() 是一个特殊的指令,它会立即中断当前阶段的执行,并直接跳到最终的 log 阶段,然后结束请求。
这意味着,post-access 阶段和整个 content 阶段都被完全跳过了。
路径二:放行请求 (The “Slower” Path)
请求进入流水线,走到 access 阶段。
你的 access.lua 脚本执行完毕,没有调用 ngx.exit()。
Nginx 继续往下走到 post-access 阶段。
关键点: 请求进入 content 阶段。在这个阶段,Nginx 会调用一个“内容处理程序 (Content Handler)”。
即使你的后端服务非常快,proxy_pass 指令本身也需要做很多工作:建立与上游的连接(或从连接池获取)、构造上游请求、发送请求、接收上游响应、解析响应头等等。这些操作,即使数据量很小,在 Nginx 内部也涉及到一系列的函数调用、内存分配和状态机转换,这些都是有 CPU 开销的。
如果是 content_by_lua,也需要一次 Lua VM 的上下文切换和脚本执行。
content 阶段结束后,再进入 log 阶段。
结论: 拒绝请求之所以更快,是因为 ngx.exit() 走了捷径,让请求这条流水线提前下线了,避免了进入整个 content 阶段所带来的固定性能开销。即便后端为空响应,Nginx 为了“准备”去请求后端以及“处理”空响应所做的内部工作,其耗时依然比 ngx.exit() 直接中断要高。
对于你“根据状态码分别统计延时和数量”的需求,使用 response() 是完全正确且专业的做法。
它带来的微小性能开销,与它能提供的精确、分离的统计数据所带来的价值相比,是微不足道的。如果不这样做,你得到的将是一个“混合”的、具有误导性的性能报告。
在性能测试中,数据的准确性永远是第一位的。 牺牲一点点压测工具的极限性能(比如从 100k QPS 降到 99.5k QPS)来换取测试结果的正确解读,是完全值得的。
额外知识点
wrk2 确实会一直尝试按速率发请求,但如果服务器延迟过高,会导致所有可用连接都被“套牢”,后续的请求因为无法建立连接而失败。报告中的高延迟,正是那些“幸运地”拿到购物车(建立连接)的请求所花费的漫长排队和等待时间。
在 Lua 中,当你用 local file = io.open(…) 创建一个文件句柄时,你得到的是一个特殊的对象(userdata)。这个对象内部有一个 __gc 元方法(可以理解为一个“析构函数”)。当没有任何变量再引用这个文件对象,Lua 的垃圾回收器 (Garbage Collector, GC) 认为它是个“垃圾”时,就会在彻底销毁它之前,调用它的 __gc 方法。对于文件句柄,这个方法就是去执行关闭文件的操作。
这个句柄 log_file_handle 变量是在模块的顶层声明的。只要这个模块存在,这个变量就一直存在,它永远不会变成“垃圾”。因此,GC 也永远不会回收它。这个文件句柄是在 worker 进程启动时创建的,并且会一直存活到这个 worker 进程退出。所以,它不需要重新生成。
log 阶段是否会影响下一个请求?
会!绝对会,而且影响巨大! 这是 Nginx/OpenResty 性能的一个核心要点。
Nginx 的一个 worker 进程是单线程的事件驱动模型。这意味着,在任何一个时间点,一个 worker 只能做一件事。
log 阶段不影响当前请求:客户端的请求时延,通常指从发送请求到收到完整的响应体为止。log 阶段是在这之后才执行的,所以客户端已经“感觉”请求结束了。
log 阶段会阻塞 worker,从而影响下一个请求:
- worker 处理完请求 A,将响应数据发送给客户端。
worker 进入请求 A 的 log 阶段。
在 log_by_lua 中,你调用了 file:write()。这是一个同步阻塞操作。假设磁盘繁忙,这个写入操作花了 50 毫秒。
在这 50 毫秒内,这个 worker 进程被完全冻结了。它不能去处理排队中的请求 B,不能响应任何网络事件,什么都干不了。
- 50 毫秒后,写入完成,worker 才“解冻”,然后才能去处理请求 B。
结论:请求 A 在 log 阶段的阻塞,直接导致了请求 B 的处理被延后了 50 毫秒。在高并发下,这种阻塞会迅速累积,导致 worker 的处理能力急剧下降,是性能杀手。
Nginx 原生的 access_log 指令,是高度优化、非阻塞的(通过内存缓冲)。
而 OpenResty 暴露给你的标准 Lua io 库 (io.open, file:write),是同步阻塞的。
OpenResty 实现非阻塞 I/O 的核心是 Cosocket API (ngx.socket.tcp 等),它只针对网络套接字。目前没有内建的、基于 Cosocket 的非阻塞文件 I/O 库。因此,在 *_by_lua 阶段直接进行文件写入,需要非常小心。
可以把特定内容写到 access_log 并享用优化吗?
可以!这不仅可以,而且是记录自定义日志的“最佳实践”!
这样做可以让你既能记录丰富的业务信息,又能完全利用 Nginx 原生日志系统的高性能和非阻塞优势。
在 nginx.conf 中定义一个新的日志格式 (log_format)
在这个格式中,你可以引用 Nginx 的内置变量,也可以引用自定义的变量(比如 $my_custom_log_var)。
1 | http { |
在你的 Lua 代码中,给这个自定义变量赋值
你可以在任何请求处理阶段(access, content, log 等)通过 ngx.var 来设置这个变量的值。
1 | -- 比如在 access_by_lua_file |
通过这种方式,你的 Lua 代码只需要做一个轻量级的变量赋值操作(非常快),而繁重、可能阻塞的文件写入工作,则完全交给了 Nginx 高效的、带缓冲的、非阻塞的 C 语言核心去处理。这是性能和灵活性兼得的最佳方案。
- “content_by_lua 的 Lua VM 上下文切换”该怎么理解?
这个“上下文切换”指的是执行控制权在 Nginx 的 C 环境 和 LuaJIT 的 VM 环境 之间的转移。
你可以把它想象成一个公司的 CEO (Nginx C 代码) 和一个技术专家顾问 (LuaJIT VM) 之间的协作:
CEO 在工作 (Nginx in C): Nginx 的事件循环(用 C 编写)正在处理请求。它按照自己的 C 语言逻辑,一步步执行 rewrite、access 等阶段。
遇到专业问题,呼叫专家 (The Switch to Lua): 当 Nginx 执行到 content_by_lua 指令时,它知道这个核心内容需要由 Lua 脚本来生成。这时,CEO 不能亲自干,他必须把工作的控制权交给技术专家。这个交接过程就是一次上下文切换:
Nginx 通过 ngx_http_lua_module 模块的 C 函数,准备好 Lua 的执行环境(比如把 ngx 这个 API table 准备好)。
然后它调用 LuaJIT 的 C API,启动 LuaJIT VM 来执行你的 Lua 脚本。
专家在工作 (LuaJIT VM runs): 现在 CPU 的控制权在 LuaJIT 手上。它执行你的 Lua 代码(ngx.say, ngx.location.capture 等)。
专家完成工作,交还报告 (The Switch back to C): 当你的 Lua 脚本执行完毕(或者调用了 ngx.exit),LuaJIT VM 会将执行结果(比如状态码、响应体)返回给调用它的那个 Nginx C 函数。CPU 的控制权又回到了 Nginx 的 C 环境。
CEO 继续收尾 (Nginx in C): Nginx C 代码拿到 Lua 的执行结果,然后继续完成请求的收尾工作,比如发送响应、记录日志等。
为什么有开销?
这个“交接”过程虽然被 LuaJIT 优化得非常快,但它仍然涉及到函数调用栈的改变、状态的保存和恢复等底层操作,相比于 Nginx 一条路纯 C 代码执行到底,它必然会产生额外的、微小的性能开销。
FFI 的性能影响与举例
不使用 FFI,意味着你使用纯 Lua来实现功能。纯 Lua 的优势是跨平台和简单,但性能通常远不及 C。
例子:计算一个字符串的 MD5 哈希值
场景1:不使用 FFI (纯 Lua 实现)
你可能会找到一个 md5.lua 的库,它完全用 Lua 代码实现了 MD5 算法。
1 | local pure_lua_md5 = require("pure_lua_md5") |
性能影响:
MD5 算法涉及大量的位运算和循环。在纯 Lua 中执行这些操作,每一步都需要经过 Lua VM 的解释或 JIT 编译。对于大数据量的计算,这会产生很多临时的 Lua 对象,给 GC(垃圾回收)带来压力,并且运算速度远慢于原生机器码。
场景2:使用 FFI (调用 OpenSSL 的 C 函数)
Nginx 自身就链接了 OpenSSL 库 (libcrypto.so),我们可以用 FFI 直接调用它里面高度优化的 C 函数。
1 | local ffi = require("ffi") |
性能优势:
在这里,Lua 脚本只扮演了一个“指挥官”的角色。它负责分配 C 级别的内存 (ffi.new),然后调用 C 函数。所有真正密集的计算工作 (MD5_Update 等) 都由 libcrypto.so 里的原生 C 语言机器码完成,其速度和用 C 语言写程序几乎没有差别。性能比纯 Lua 实现快 1-2 个数量级都是很常见的。
如何定义“使用了 FFI”?
你的理解非常敏锐。是的,只要使用了 ffi 库的任何功能,就算是使用了 FFI。
FFI (Foreign Function Interface) 的核心是与 C 语言世界进行交互。这种交互分为两个层面:
数据层面交互 (C Data Interface):
这是 resty.limit.req 主要的使用方式。它使用 ffi.new, ffi.cast, ffi.copy, ffi.string 等函数来创建和操作 C 语言级别的数据结构 (struct)。这样做可以完全绕开 Lua 的 table 和 string,从而避免创建 Lua 对象,也就避免了 GC 的开销。resty.limit.req 将限速状态保存在 C struct 中,就属于这种最高效的用法。
函数层面交互 (C Function Interface):
这是更广为人知的用法,即调用 C 函数。这又分为两种:
调用 Nginx 内部或其依赖库(如 OpenSSL)的函数。
调用你自己编写的、编译成 .so 文件的外部 C 函数。
结论:
你不需要自己写 C 函数再用 ffi.load 才算用 FFI。仅仅是为了性能而直接在内存中操纵 C 数据结构,是 FFI 在 OpenResty 生态中更普遍、更巧妙的应用。resty.limit.req 正是这方面的典范。
log_by_lua 阶段写日志的问题
会带来什么问题?
主要问题是阻塞 (Blocking)。文件 I/O(磁盘写入)是一个典型的阻塞操作。Nginx 的高性能模型基于非阻塞的事件驱动。如果在 log_by_lua 里执行一个同步的、耗时的磁盘写入,那么这个 Nginx worker 进程就会被卡住,无法去处理其他成千上万的并发请求,导致整个 worker 的吞吐量急剧下降。
写日志的时间会算在请求时延里吗?
不会。 这是 log 阶段的一个关键特性。它在 Nginx 已经将完整的 HTTP 响应发送给客户端之后才执行。所以,log 阶段无论花费多长时间,客户端感受到的请求时延(TTFB, Time To First Byte)都不会受影响。
如何用 log 缓存优化?
Nginx 的原生 access_log 指令就自带了这个优化。它使用 buffer=size 和 flush=time 参数。
access_log /path/to/log buffer=32k flush=5s;
这意味着 Nginx 会先把日志条目写入一块 32KB 大小的内存缓冲区。只有当缓冲区满了,或者距离上次刷盘超过 1 秒钟,Nginx 才会把整个缓冲区的内容一次性通过 write() 系统调用写入磁盘。
优化原理: 这种“攒一批再写”的方式,大大减少了 write() 系统调用的次数,而系统调用是昂贵的。它用批处理的方式摊薄了单次请求的日志I/O开销。
wa = 0 + sy = 10% + 高 CPU 占用率 (您的 us 值应该也不低) = CPU 密集型负载,且与网络处理高度相关。
这描绘了一幅清晰的画面:
您的服务器没有被外部依赖(如数据库、磁盘)拖慢。它正在“全力以赴”地工作。CPU 的繁忙时间,一部分(sy)是被操作系统内核用来处理您压测带来的巨大网络流量,另一部分(us)则是被 Nginx worker 进程本身用来执行您的 Lua 代码(比如 JSON 解析、限速逻辑计算等)。
结论:您的性能瓶颈在于 CPU 的处理能力,特别是网络包处理和您的 Lua 代码执行。系统没有在“等待”,而是在拼命“计算”。要提高性能,您可以考虑:
优化 Lua 代码,减少每个请求的计算量。
升级 CPU 或增加 Nginx 的 worker_processes 数量(如果还没达到 CPU 核心数)。
横向扩展,增加更多的服务器来分担负载。
即便都写到 access.log 就可以避免 I/O 的消耗吗?
不是避免消耗,而是优化消耗方式,将 I/O 的“成本”从性能瓶颈中移除。
如我们之前所讨论的,Nginx 的 access_log 机制通过内存缓冲和批量写入,实现了以下两点:
让您的 Lua 代码不直接接触慢速 I/O:您的代码只需要快速地更新一个内存中的变量 (ngx.var),就可以“认为”日志任务已经完成了。
将 I/O 成本均摊:Nginx 把很多条日志攒在一起,用一次高效的批量写入来完成。
所以,虽然磁盘写入这个物理动作最终还是发生了,但它被 Nginx 安排得明明白白,不会阻塞您的 worker 进程处理新的请求。这对于提升并发处理能力至关重要。
LuaJIT使用增量式的标记-清除(mark-and-sweep)垃圾回收器 。虽然它避免了长时间的“世界暂停”(stop-the-world)问题,但频繁的GC活动表明存在很高的内存分配压力,这会消耗本可用于应用逻辑的CPU周期。
GC活动会以对应其内部C函数的矩形形式出现。虽然具体的标记和清除函数是深层内部实现,但GC过程通常是分步执行的。一个关键的函数是 lj_gc_step。
与GC过程相关的内存分配/释放函数 lj_alloc_malloc 和 lj_alloc_free 也是驱动GC的源头 。
Lua 对象保留的时间比需要的稍长一些通常是没问题的。基本上,在进程的生命周期内看到 GC 计数(或 GC 分配的内存)上升和下降是正常的。
这就是典型的增量式 GC 的工作原理。LuaJIT 的 GC 周期由多个不同的阶段组成。所有这些阶段又被划分成许多小段,与正常的 Lua 代码执行交织在一起。例如,当 GC 周期处于“sweep-string”阶段时,非字符串类型的 GC 对象将不会被释放,直到 GC 周期随后进入“sweep”阶段。
taskset -c 1 env STP_MAXMEMORY=2048 STAP_OPTS=”-DMAXMAPENTRIES=100000” /opt/profiling-tools/openresty-systemtap-toolkit/sample-bt -p 13789 -u -t 10 > stacks.bt
taskset -c 1 env STP_MAXMEMORY=2048 STAP_OPTS=”-DMAXMAPENTRIES=100000” /opt/profiling-tools/openresty-systemtap-toolkit/sample-bt-off-cpu -p 13789 -u -t 10 -min 1000 > stacks.bt
–min
重要命令
taskset -c 1 openresty-systemtap-toolkit/sample-bt -p 7337 -u -t 20 -a ‘-DMAXMAPENTRIES=20000’ > stacks.bt
生成火焰图
FlameGraph/stackcollapse-stap.pl stacks.bt > stacks.folded
FlameGraph/flamegraph.pl stacks.folded > stacks.svg
./wrk2 -t4 -c200 -d50s -R1000 -s /mnt/c/Users/Iridescent_zlc/request.lua http://strumcode.com/?action=DescribeLoadBalancers&appId=251394366&subAccountUin=700001857252&RequestId=123456789
./wrk2 -t4 -c200 -d30s -R1000 -s /mnt/c/Users/Iridescent_zlc/request.lua http://strumcode.com/?action=DescribeLoadBalancers&appId=251394366&subAccountUin=700001857252&RequestId=123456789
./wrk2 -t4 -c200 -d80s -R1000 -s /mnt/c/Users/Iridescent_zlc/request.lua http://strumcode.com/?action=DescribeLoadBalancers&appId=251394366&subAccountUin=700001857252&RequestId=123456789
./configure –prefix=/usr/local/openresty-1.17.8.2
–with-luajit
–with-debug
–with-cc-opt=’-O0 -g’
–without-luajit-gc64
–without-http_redis2_module
–with-http_iconv_module
生成火焰图
–skip-badvars 标志告诉 SystemTap 在遇到无法读取的变量或无效的内存地址时,不要崩溃退出,而是跳过这个错误,并用 0 或空字符串来代替。 2493 是进程
stap++ –arg time=20 -x 2493 –skip-badvars stapxx/samples/lj-lua-stacks.sxx > out.stap
FlameGraph/stackcollapse-stap.pl out.stap > out.folded
FlameGraph/flamegraph.pl out.folded > lua-level.svg
代码的哪个部分在疯狂地创建这些对象?为了回答这个问题,我们可以引入一种强大的可视化技术——分配火焰图(Allocation Flame Graph)。
标准的CPU火焰图通过在固定时间间隔(如99Hz)对CPU上正在执行的函数调用栈进行采样来工作,图的宽度代表了CPU时间的消耗比例 。而分配火焰图的原理略有不同:它不是基于时间的采样,而是基于事件的采样。我们让每一次内存分配事件(即lj_alloc_malloc或lj_alloc_realloc的调用)触发一次Lua调用栈的采样 。
通过修改stapxx工具集中的lj-lua-stacks脚本,将其采样触发器从probe timer.profile改为probe process(…).function(“lj_alloc_malloc”).return,就可以收集到以分配次数为权重的调用栈数据。将这些数据输入Brendan Gregg的FlameGraph工具集进行处理,生成的火焰图中,每个矩形的宽度将不再代表CPU耗时,而是代表该函数及其调用链所产生的分配次数占总分配次数的比例 。
解读分配火焰图非常直观:图中那些宽阔的“平顶山”就是分配热点。沿着这些最宽的矩形从下往上追溯,就可以清晰地看到从哪个请求入口,经过哪些函数调用,最终在哪个具体函数中产生了大量的内存分配。这种可视化方法能够极其高效地将分析人员引导至造成内存抖动的代码根源。
生成 x 轴代表其对应的函数以及它调用的所有子函数所产生的内存分配次数的
你可以通过命令行的 –arg probe=”…” 参数来动态指定任何你想要的探针作为触发器。
我们把内存分配事件探针作为参数传递给脚本,脚本内部的 $^arg_probe 变量就会被替换成这个值,从而将采样触发器从默认的 timer.profile 切换为我们指定的内存分配事件。
甚至是针对某个特定函数(例如 lj_tab_resize)的调用火焰图,以专门分析 table 扩容的来源。
–skip-badvars
1 | stap++ stapxx/samples/lj-lua-stacks.sxx \ |

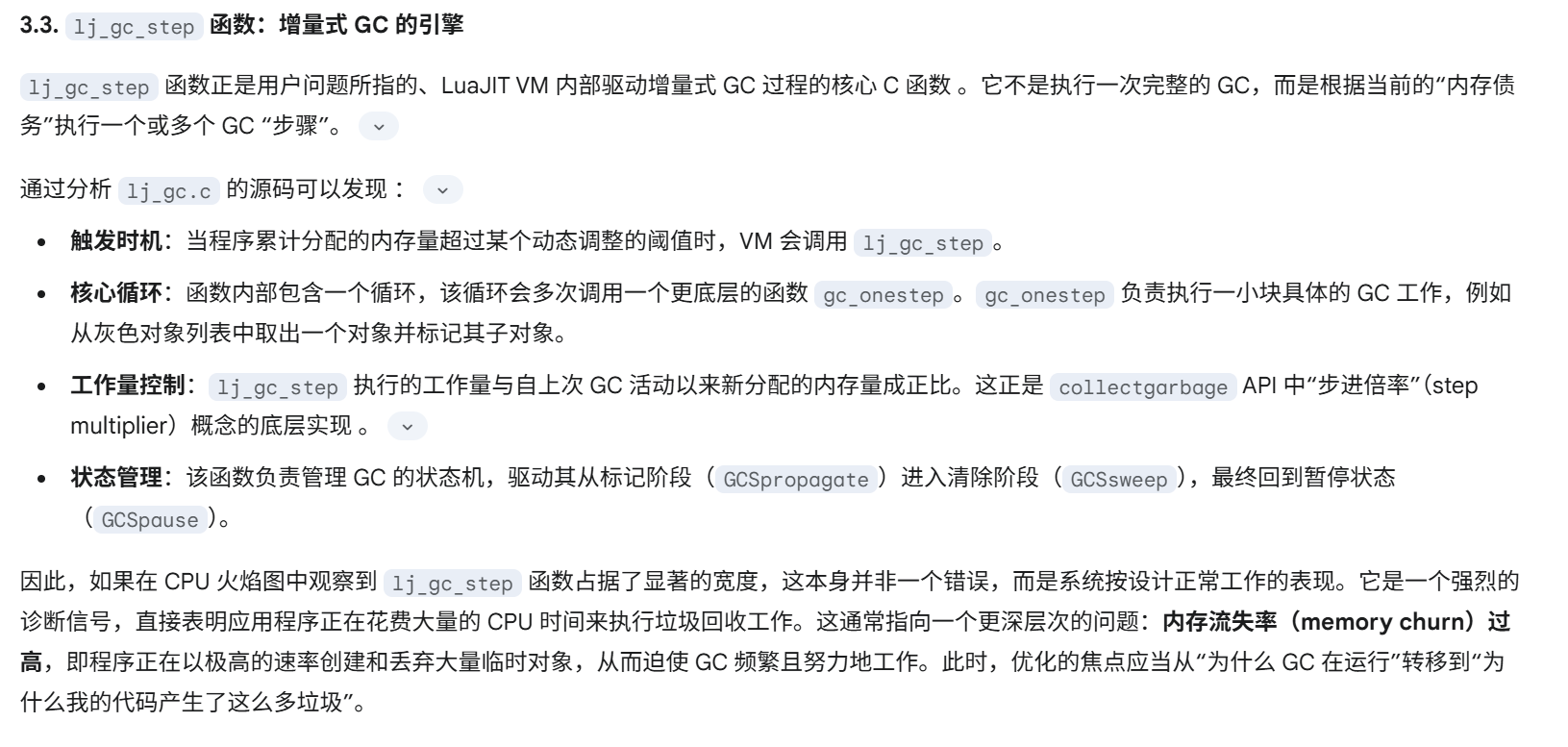
stap++ stapxx/samples/ngx-lj-trace-exits.sxx -x 2493 –arg time=20
这份报告提供了丰富的信息:
JIT 覆盖率:86 out of 18692 requests used compiled traces 这一行至关重要。它表明在采样期间,只有极少数请求(约 0.22%)实际运行了 JIT 编译的代码。这本身就是一个强烈的信号,说明大部分工作负载可能由于某种原因未能触发 JIT 编译。
退出次数分布:直方图显示了那 86 个进入 JIT 模式的请求的具体表现。value 列代表每个请求的退出次数,count 列代表具有该退出次数的请求数量。
1 |@@@@ 4:表示有 4 个请求,每个请求都发生了 1 次跟踪退出。
2 |@ 1:表示有 1 个请求,发生了 2 次跟踪退出。
这种按请求的分布统计,远比一个简单的总退出次数更有价值。一个较高的平均退出次数固然是坏消息,但一个带有长尾的分布(例如,大多数请求只有 1-2 次退出,但少数请求有上百次退出)则更能说明问题。它精确地指出了性能问题可能与特定类型的请求或特定的业务逻辑分支相关,从而允许开发者进行靶向优化,而不是进行泛泛的、猜测性的代码调整。该工具赋予了开发者一种更精确、数据驱动的 JIT 优化能力。
stap++ stapxx/samples/lj-gc-objs.sxx -x 7337 -D MAXACTION=90000000
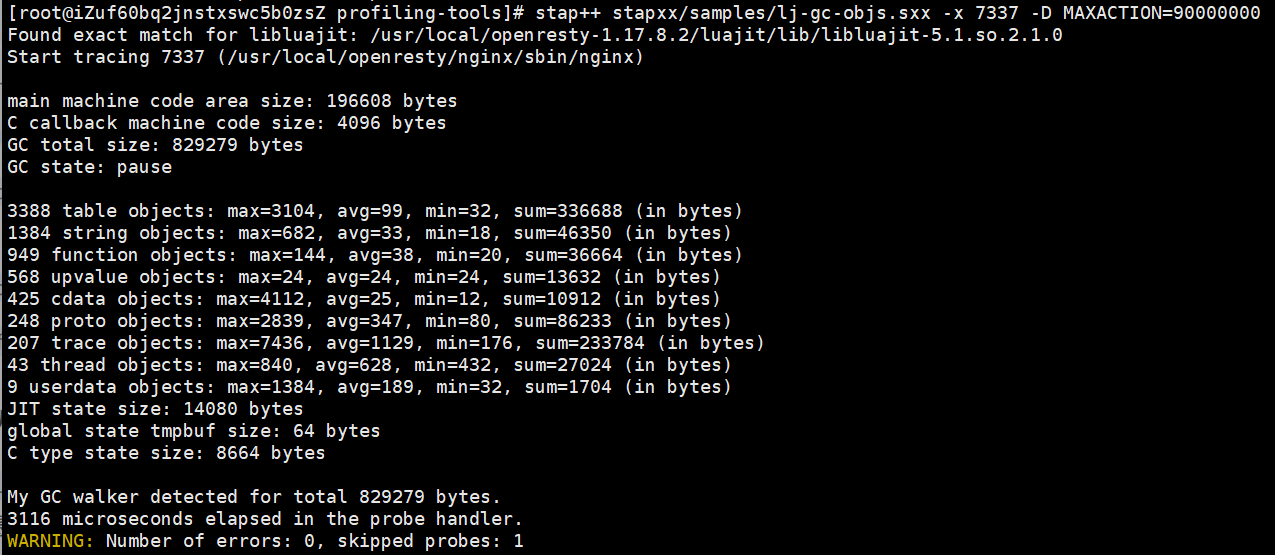
stap++ scripts/lj-alloc-rate.stp -x 7337 –arg INTERVAL=20
在脚本中可以引用变量 $^arg_INTERVAL 。
stap++ scripts/lj-alloc-by-type.stp -x 7337 –arg INTERVAL=20
在 OpenResty 开发中,开发者经常会遇到一些不被 JIT 支持的特性 。例如:
使用 pairs()/next() 迭代表的哈希部分。
在某些上下文中使用 table.insert 或 table.remove。
使用带函数参数的 string.gsub。
使用复杂模式的 string.match 。
使用 ngx-lj-trace-exits.sxx 识别问题:首先运行该工具,确认特定工作负载下是否存在大量的追踪退出。
启用详细 JIT 日志:通过在 Lua 代码中调用 jit.v.on() 或使用 -jv / -jdump 标志运行 luajit 来获取详细的追踪信息 。
复现并分析转储文件:重新运行有问题的负载,并检查日志输出。例如,一条 `` 的日志清晰地指出了追踪中止的原因(NYI)、发生问题的源文件和行号(a.lua:22),以及具体的不兼容函数(string.match) 。Kong 的一个性能回归案例就是一个典型的例子,工程师们通过分析 JIT 日志,最终定位到 FNEW 字节码是导致追踪中止和性能下降的罪魁祸首 。
令牌桶与漏桶之间的选择不仅仅是技术上的,更是一个产品和业务决策。令牌桶对用户更友好,允许合法用户有偶发的突发操作。漏桶则更为严格,将后端服务的稳定性和可预测性置于首位。API 的用户可能在一段时间空闲后,需要执行一批突发操作(例如,上传多个文件),令牌桶允许这样做,从而改善了用户体验 。从服务器的角度来看,这种突发意味着它必须能够处理高达桶容量的流量峰值,而不仅仅是平均速率。然而,漏桶保证了后端服务接收请求的速率永远不会高于泄漏速率 。这简化了容量规划并保护了服务,但对于那些合法突发请求被节流或拒绝的用户来说,可能会感觉过于严格。因此,一个面向公众的 API 可能会选择令牌桶以提供更好的开发者体验,而一个内部的关键服务可能会使用漏桶来强制执行严格的稳定性保证。
HTTP 的演进史,实际上是一个不断识别并解决队头阻塞(HOL blocking)问题的过程。HTTP/1.1 的管道化技术是一个不完整的解决方案,HOL 阻塞问题依然存在。HTTP/2 通过多路复用在应用层解决了 HOL 阻塞,但这却暴露了同样的问题存在于传输层(即 TCP)。HTTP/3 转向 QUIC(基于 UDP)是合乎逻辑的下一步:在传输层本身解决 HOL 阻塞问题。HTTP/1.1 引入了持久连接,但在该连接上是串行处理请求的,一个慢请求会阻塞所有其他请求,这是应用层的 HOL 阻塞。HTTP/2 引入多路复用,允许在单个 TCP 连接上交错处理多个请求/响应流,解决了应用层的 HOL 阻塞。然而,TCP 本身保证其字节流的有序传递。如果单个 TCP 数据包丢失,操作系统 TCP 协议栈会扣留所有后续的数据包(即使它们属于不同的 HTTP/2 流),直到丢失的数据包被重传。这就是传输层的 HOL 阻塞。解决这个问题的唯一方法是放弃 TCP,转向一个不强制单一有序字节流的传输协议。建立在 UDP 之上的 QUIC 实现了独立的流,一个流中的数据包丢失不会影响其他流。这展示了一个经典的系统设计模式:优化协议栈的某一层,往往会暴露其下一层的瓶颈。
如果数据包2(可能属于“肉”这个流的一部分)在路上丢失了。
TCP 协议规定,接收方(服务器)必须停下来,等待发送方(客户端)重传数据包2。在此期间,就算数据包 3、4、5(可能属于“水”和“纸巾”的流)已经顺利到达,它们也不能被组装和交付给上层应用(HTTP/2)。它们都被阻塞在 TCP 的接收缓冲区里。
结论: 这就是 HTTP/2 的队头阻塞。它发生在传输层 (TCP)。一个 TCP 数据包的丢失,会导致整个 TCP 连接上的所有流 (Stream) 都必须停下来等待,即使丢失的数据包只影响了其中一个流。HTTP/2 在应用层把队伍分开了,但底层的 TCP 协议又把大家捆绑在了同一条必须按顺序前进的路上。
性能: epoll_wait 只返回已就绪的文件描述符。内核使用一种基于事件的机制(回调)将就绪的文件描述符添加到一个列表中,因此检查操作的复杂度相对于被监视的总文件描述符数量是 O(1)。
UPDATE 语句流程与两阶段提交:
当在启用了二进制日志(用于主从复制)的 InnoDB 中执行 UPDATE 语句时,MySQL 使用内部的两阶段提交 (2PC) 来确保存储引擎日志和服务层日志之间的一致性。
阶段一:准备阶段 (Prepare Phase)
InnoDB 引擎首先将数据的“前镜像”写入 undo log(用于回滚和 MVCC)。
然后,它将变更应用到内存中的缓冲池,并将数据的“后镜像”写入 redo log 的缓冲区。
接着,InnoDB 调用 innobase_xa_prepare,将 redo log 刷新到磁盘,并将事务在引擎内部标记为“已准备”状态 。此时,即使服务器崩溃,InnoDB 也能恢复该事务。
阶段二:提交阶段 (Commit Phase)
MySQL 服务器(作为事务协调者)将该事务写入 binlog 。
binlog 成功写入磁盘后,服务器指示 InnoDB 提交事务。
InnoDB 在 redo log 中记录一个“提交”标记,并完成事务 。
中肯
使用 sample-bt 生成的火焰图是 C 层面的。对于 LuaJIT 程序,这意味着火焰图的顶端要么是 JIT 编译后的一段原生机器码地址,要么是 Lua VM 解释器的内部 C 函数,如 lj_BC_ADDVV(执行加法字节码的函数)。这种视图对于 VM 开发者来说信息量巨大,但对于应用开发者来说,它无法直接映射到具体的 Lua 函数名,缺乏直观性。
为了解决这个问题,stapxx 工具集提供了 lj-lua-stacks 这样的工具,它能够在采样时重建 Lua 层面的调用栈,生成一张直接显示 Lua 函数名、文件名和行号的火焰图 。这对于定位业务逻辑中的性能瓶颈极为有用。
最高级的性能分析,是将这两种火焰图结合起来看。例如,C 层面的火焰图显示大量时间消耗在 lj_gc_step,而与之对应的 Lua 层面火焰图则清晰地显示出是哪个 Lua 函数(及其调用链)触发了大量的内存分配。这种跨层面的关联分析,能够提供最直接、最无可辩驳的性能问题证据。
拥抱数据驱动:性能优化不应基于猜测。熟练运用本报告中讨论的工具,建立一套数据驱动的性能分析和调优文化。
理解底层机制:编写高性能 Lua 代码的前提是理解其运行时的行为,特别是 JIT 编译器和 GC 的特性。例如,了解跟踪 JIT 的工作原理,可以帮助开发者写出“JIT 友好”的代码。
LuaJIT 的即时(Just-In-Time, JIT)编译器采用了一种独特的跟踪(Tracing)模式,这与传统的基于方法(Method-based)的 JIT 编译器有所不同 。它并非编译整个函数,而是通过运行时监控,识别出程序中被频繁执行的代码路径,即所谓的“热点路径”(Hot Path),通常是循环或高频调用的函数体 。
一旦识别出热点,JIT 编译器便开始“记录”(Record)该路径上执行的字节码指令序列,形成一个线性的“跟踪”(Trace)。这个跟踪随后会经过一系列复杂的优化,最终被编译成高度优化的、与平台相关的原生机器码 。应用程序的性能提升,正源于其大部分时间都在这些快速的原生机器码跟踪中执行。因此,性能优化的一个核心目标就是确保关键业务逻辑能够尽可能长时间地在这些已编译的跟踪内运行,避免回退。
“跟踪退出”(Trace Exit)或“跟踪中止”(Trace Abort)指的是虚拟机(VM)在执行过程中,因无法继续沿着已编译的原生代码路径执行,而被迫退出该路径,并回退到相对较慢的字节码解释器模式的事件 。
首先,LuaJIT采用的是增量式标记-清除(Incremental Mark-and-Sweep)垃圾回收器 1 。这意味着GC的工作被分解成多个小步骤,穿插在应用程序(即“mutator”)的执行流程中 2 。当对象分配的频率非常高时,会更频繁地触发GC阈值,导致GC步骤被更频繁地执行。这些GC步骤,由C函数lj_gc_step驱动,会中断正常的Lua代码执行,直接占用宝贵的CPU时间片 3 。因此,即使总内存没有增长,大量的对象创建和销毁也会让CPU疲于奔命,执行GC相关的标记、扫描和清理工作。
要精确地分析内存抖动,需要能够在不侵入、不重启目标应用的前提下,观测其内部的内存分配行为。SystemTap是一个功能强大的Linux动态追踪框架,它允许用户编写脚本来探测(probe)内核和用户空间的事件,例如函数调用、返回等,并执行相应的处理程序 。
stapxx是基于SystemTap的一个增强型工具集,它提供了一套丰富的、专门为OpenResty和LuaJIT优化的“探针集”(tapset)和示例脚本 。这使得分析LuaJIT虚拟机的内部状态变得异常简单和高效,是解决本文所述问题的首选开源工具。
内存抖动的第一个量化指标是总分配率,即单位时间内分配的对象数量和字节数。通过直接探测LuaJIT的底层内存分配函数,我们可以精确地测量这一指标。LuaJIT中所有GC对象的内存分配都通过lj_alloc_malloc和lj_alloc_realloc这两个核心C函数进行 。
我们可以编写一个简单的SystemTap脚本来挂载探针到这两个函数的返回点,并结合定时器来计算速率。
在LuaJIT中,每个被GC管理的对象都有一个通用的头部结构GCobj。这个结构体中包含一个名为gch的头部,其中又有一个gct字段,它存储了该对象的类型标签(Type Tag)。
知道了哪种类型的对象在剧烈抖动后,下一个问题是:代码的哪个部分在疯狂地创建这些对象?为了回答这个问题,我们可以引入一种强大的可视化技术——分配火焰图(Allocation Flame Graph)。
标准的CPU火焰图通过在固定时间间隔(如99Hz)对CPU上正在执行的函数调用栈进行采样来工作,图的宽度代表了CPU时间的消耗比例 。而分配火焰图的原理略有不同:它不是基于时间的采样,而是基于事件的采样。我们让每一次内存分配事件(即lj_alloc_malloc或lj_alloc_realloc的调用)触发一次Lua调用栈的采样 。
通过修改stapxx工具集中的lj-lua-stacks脚本,将其采样触发器从probe timer.profile改为probe process(…).function(“lj_alloc_malloc”).return,就可以收集到以分配次数为权重的调用栈数据。将这些数据输入Brendan Gregg的FlameGraph工具集进行处理,生成的火焰图中,每个矩形的宽度将不再代表CPU耗时,而是代表该函数及其调用链所产生的分配次数占总分配次数的比例 。
解读分配火焰图非常直观:图中那些宽阔的“平顶山”就是分配热点。沿着这些最宽的矩形从下往上追溯,就可以清晰地看到从哪个请求入口,经过哪些函数调用,最终在哪个具体函数中产生了大量的内存分配。这种可视化方法能够极其高效地将分析人员引导至造成内存抖动的代码根源。
lj-gc.sxx是专门为检测LuaJIT GC管理而设计的SystemTap脚本 。它的核心思想是追踪每一个内存块的生命周期,找出那些“有始无终”(只分配不释放)的内存块。
这里的Total GC count表示在脚本退出时,尚未被释放的GC内存总量 。如果这个值在多次运行或长时间运行中持续增长,就表明存在内存泄漏 。
与追踪内存生命周期的lj-gc.sxx不同,lj-gc-objs.sxx工具提供的是一个即时快照,它在某一瞬间遍历整个LuaJIT的GC堆,并按对象类型对所有存活的对象进行统计和汇总 。这个工具对于理解应用程序在稳定运行时的内存分布非常有用,可以回答诸如“我的内存主要被什么类型的数据占用了?”这类问题。
Lua语言本身没有内置的类(class)概念。面向对象编程通常是通过metatable(元表)模拟实现的 。一个“类”通常是一个表,其中包含方法;一个“实例”或“对象”则是另一个表,其元表的__index字段指向这个“类”表,从而实现方法继承 。
从LuaJIT的垃圾回收器视角来看,不存在“类实例”这种特殊的GC对象类型。一个Lua的“对象”或“实例”本质上就是一个table 。因此,在lj-gc-objs.sxx的输出中,你不会看到名为class instance的条目。所有的“实例”都会被统计在table objects这一类别下。如果你的应用创建了大量的对象实例,那么你会在报告中看到table objects的数量和总大小相应地增加。
JIT
一个没有内部循环的请求,即使被重复执行一百万次,其代码路径本身也可能永远不会被 JIT 编译。
追踪式 JIT vs. 方法级 JIT:不同的哲学
首先,我们需要区分两种主流的 JIT 编译模式:
方法级 JIT (Method-based JIT):这是像 Java HotSpot VM 中常见的模式。它的分析器观察哪个函数或方法被调用得最频繁。一旦某个方法变“热”,编译器就会尝试编译整个方法。
追踪式 JIT (Tracing JIT):这是 LuaJIT 所采用的模式 。它不关心哪个函数是热点,而是关心哪条执行路径是热点 。它通过运行时监控,像录像一样记录下一条被高频执行的线性代码序列(通常是循环),我们称之为“追踪”(Trace),然后将这条“追踪”编译成高度优化的原生机器码 。
问题在于,LuaJIT的跟踪JIT编译器(Tracing JIT Compiler)目前不支持FNEW这条字节码指令 。它被标记为“尚未实现”(Not Yet Implemented, NYI)。
LuaJIT的JIT编译器通过“跟踪”热点代码路径来工作。当一个循环被执行足够多次后,JIT会启动一个“跟踪器”来记录这个循环中的字节码序列,然后将这个序列编译成高效的本地机器码 。然而,当跟踪器在记录过程中遇到一个它不支持的NYI字节码(如FNEW)时,它会立即中止跟踪(Trace Abort) 。
跟踪中止意味着JIT编译器放弃了对这条热点路径的编译尝试。其直接后果是,这个本应被高度优化的热循环,将永远只能在相对慢得多的解释器模式下执行 。性能差异可能达到一个数量级甚至更多。
LuaJIT 如何发现“热点路径”?它依赖一个名为“热点计数器”的内部机制 。
主要触发器是循环:LuaJIT 的设计基于一个核心假设——程序的大部分时间都消耗在循环中 。因此,它的性能分析器主要关注字节码中的后向跳转指令,这是循环的典型特征 。
计数与阈值:每当解释器执行一次后向跳转(即循环的一次迭代),它就会为一个与该跳转相关的计数器减一。这个计数器初始时有一个阈值(例如默认是 56)。当计数器被减到零时,这条路径就被标记为“热点” 。
开始记录:下一次当代码执行到这个“热点”跳转时,解释器不会再继续执行,而是启动 JIT 的“记录器”(Recorder)。记录器会开始记录接下来执行的每一条指令,直到本次循环结束或遇到无法编译的指令,从而形成一条完整的“追踪” 。
为什么一百万次相同的请求没有触发 JIT?
因为在典型的 Web 服务器模型(如 OpenResty)中,每个请求都在一个独立的上下文(协程)中处理。从 JIT 的角度看,这一百万次请求是一百万个独立的、短暂的、线性的执行过程。在任何单个请求的处理过程中,由于没有循环,后向跳转指令没有被重复执行,热点计数器从未达到触发阈值。因此,JIT 编译器根本没有收到“开始工作”的信号。
理解了上述机制后,我们就能明白 JIT 的真正威力所在。它并非为“重复的宏观任务”(百万次请求)设计,而是为“重复的微观操作”(单个请求内的循环)设计的。
JIT 在以下场景中会发挥巨大作用:
数据处理循环:当您的单个请求需要处理大量数据时。例如:
从数据库获取了 2000 行数据,并在一个 for 循环中对每一行进行处理和格式化。
解析一个包含大量元素的 JSON 数组或对象。
对一个长字符串进行复杂的模式匹配或转换。
复杂的业务逻辑:在单个请求中,如果业务逻辑涉及到算法(如路径查找、排序)或者状态机,这些通常包含循环,会被 JIT 极大地加速。
追踪链接 (Trace Stitching):一旦一个热循环被成功编译成一个“根追踪”,JIT 还会变得更智能。如果从这个已编译追踪的出口频繁地跳转到另一段代码,这个出口也会变“热”,JIT 会创建新的“旁路追踪”并将其链接(stitch)到主追踪上 。通过这种方式,JIT 可以将多个代码片段连接起来,逐步扩大编译代码的覆盖范围,甚至覆盖那些本身不包含循环的代码。
一旦识别出热点,JIT 编译器便开始“记录”(Record)该路径上执行的字节码指令序列,形成一个线性的“跟踪”(Trace)。这个跟踪随后会经过一系列复杂的优化,最终被编译成高度优化的、与平台相关的原生机器码 。应用程序的性能提升,正源于其大部分时间都在这些快速的原生机器码跟踪中执行。因此,性能优化的一个核心目标就是确保关键业务逻辑能够尽可能长时间地在这些已编译的跟踪内运行,避免回退。
table.concat函数在内部会预先计算出最终字符串所需的总长度,然后只进行一次内存分配和一次数据拷贝,从而避免了产生大量的中间字符串垃圾 。
表达式 buffer = buffer.. “some_string”都会执行以下步骤:
分配一块足以容纳buffer旧内容和”some_string”的新内存。
将buffer的全部内容复制到新内存中。
将”some_string”的内容复制到新内存的末尾。
让buffer变量引用这个新创建的字符串。
旧的buffer字符串成为垃圾,等待GC回收。
核心问题:Table 扩容风暴 (The Core Problem: A Table Resizing Storm)
LUA_TTABLE (New): 53,506 次 (速率: ~2,675 次/秒)
LUA_TTABLE (Resize): 815,552 次 (速率: ~40,777 次/秒)
这是整个报告中最引人注目、最关键的信息。
您的程序每秒会创建约 2700 个新 table,但同时会发生高达 40,000 次的 table 扩容操作!
计算一下比例:815,552 (扩容) / 53,506 (新建) ≈ 15.2
这意味着,平均每个新创建的 Table,在其生命周期内被反复扩容了高达 15 次!
每一次 resize 都伴随着一次昂贵的 realloc 内存分配和对 table 内所有元素的重新哈希(rehash)与拷贝。这是一个巨大的 CPU 浪费,也是造成高 GC 压力的元凶。这完美印证了我们之前的推断:您的代码热点路径中,存在大量“在循环里向未预设大小的 table 添加元素”的性能陷阱。
另一个元凶:高频的小字符串分配 (The Other Culprit: High-Frequency Small String Allocation)
LUA_TSTRING: 896,257 次 (速率: ~44,812 次/秒)
Bytes: 17,676,861 字节 (流量: ~0.88 MB/秒)
您的程序每秒会创建近 45,000 个新的字符串对象。这是一个非常高的频率。我们可以计算一下平均字符串的大小:
17,676,861 / 896,257 ≈ 19.7 字节
平均每个字符串的长度只有约 20 字节。这通常意味着:
在循环中用 .. 拼接字符串:例如 local key = “prefix:” .. i,这种操作会产生大量短小的中间字符串。
lj_tab_new vs. lj_tab_resize
为了澄清这一点,我们需要理解 LuaJIT 内部的两个关键函数:
lj_tab_new:
目的:创建一个全新的、空的 GCtab 对象。
调用时机:当你执行 local t = {} 或 ngx.new_tab() 时。
结果:一个 fresh 的 table 对象诞生。
lj_tab_resize:
目的:对一个已经存在的 table 对象进行扩容,为其分配更大的数组或哈希空间。
调用时机:当你向一个已满的 table 中添加新元素时,例如 t[#t + 1] = value。
内部行为:它会调用底层的 lj_alloc_realloc 来获取一块更大的内存,然后将旧 table 中的所有元素 rehash 并拷贝到新空间。它不会调用 lj_tab_new。
所以,为了全面地分析 table 相关的内存分配,我们必须同时监控这两个事件:创建 和 扩容(专门为 lj_tab_resize 增加了一个探针)。
你的脚本探测的是 lj_alloc_malloc 和 lj_alloc_realloc 这两个底层内存分配函数的返回点 (return)。
请思考一下创建一个 Lua table 的完整过程:
上层函数 lj_tab_new 被调用。
lj_tab_new 调用 lj_alloc_malloc 来申请一块原始的、未初始化的内存。
lj_alloc_malloc 返回一个内存指针 ptr。(你的探针在此时触发!)
在这之后,lj_tab_new 函数才会开始初始化这块内存,比如写入 GCHeader,并将类型字段 gch->gct 的值设置为 LJ_TTAB (5)。
结论:你的探针在 gct 字段被正确赋值之前就触发了。 这意味着 @cast(ptr, “GCobj”, …)->gch->gct 读取到的是一块未初始化的内存,里面可能是任何随机的脏数据。这就导致你的类型统计完全错乱,结果自然和预期相差巨大。
为了准确地统计每种类型的分配,我们不应该探测底层的内存分配器,而应该去探测创建具体类型对象的那些函数。这样做有两个好处:
类型是确定的:探测 lj_tab_new 就意味着一个 table 被创建,无需再去内存里读取类型。
时机是准确的:在这些函数的返回点,对象已经初始化完毕。
策略改变:我们不再使用一个统一的探针,而是为 lj_tab_new, lj_str_new, lj_func_newC, lj_func_newL 等多个函数分别设置探针。
对大小统计的妥协:一个缺点是,在某些创建函数(如 lj_tab_new)的返回点,我们不容易像之前那样通过 @entry($nsize) 获取到准确的分配大小。因此在新脚本中,我对可以获取大小的类型(String, Userdata, CData)进行了统计,对不易获取的(Table, Function)只统计了次数。对于性能分析来说,分配次数和类型的分布通常比精确的字节数更重要。
有趣的是,GC 问题和 JIT 问题之间存在微妙的关联。解释器执行效率远低于 JIT 编译后的机器码,这意味着在 JIT 问题修复前,服务在达到 CPU 瓶颈时所能处理的流量上限较低。修复 JIT 问题会提升组件的吞吐能力,但这反过来又会给 GC 系统带来更大的压力。如果不同时解决 GC 问题,JIT 优化带来的吞吐量提升可能会被更频繁的 GC 停顿所抵消。这种相互关联性体现了对系统性能进行整体性思考的重要性,优化一个部分可能会暴露或加剧另一部分的瓶颈。
这两种火焰图的比例之所以不同,是因为它们从两个完全不同的抽象层面来观察同一个程序的运行。
- C on-CPU 火焰图:虚拟机的视角
它看到了什么:由 perf 等标准工具生成的 C 级别火焰图,看到的是 LuaJIT 这个 C 程序(虚拟机)本身在 CPU 上的执行情况。它通过采样指令指针并查看 C 语言的函数符号表来工作 。
它的“盲点”:当 LuaJIT 的 JIT 编译器运行时,它会动态生成没有标准符号的原生机器码 。perf 无法将这些机器码地址映射回具体的 Lua 函数。因此,大量本应属于 Lua 业务逻辑的 CPU 时间,在 C 火焰图中被错误地归类为某个通用的 VM 执行函数,或者干脆显示为未知的地址。
结果:C 火焰图的总样本(X 轴的总宽度)中,有很大一部分是“无法解释”或被错误归因的。因此,像 lj_gc_step 这样的 C 函数,其宽度是相对于这个不完整的、被扭曲的总量来计算的。这会导致它的相对比例被夸大。
- Lua on-CPU 火焰图:应用逻辑的视角
它看到了什么:由 SystemTap 配合 lj-lua-stacks 这类专用脚本生成的 Lua 级别火焰图,通过深入 LuaJIT 虚拟机内部,直接读取其状态信息来重建调用栈 。
它的优势:这种方法能够准确地识别出当前是在执行 JIT 编译后的 Lua 代码(显示为 trace#…)、解释执行的 Lua 代码,还是在执行 VM 的内部 C 函数(如 GC)。
结果:Lua 火焰图的总样本(X 轴的总宽度)是完整的、被正确定性的。它包含了所有部分:JIT 代码、解释器代码、C 函数调用以及 GC 等内部活动。因此,lj_gc_step 的宽度是相对于整个应用真实、完整的 CPU 消耗来计算的。这个比例真实地反映了 GC 在您整个业务逻辑中所占的开销。
对于性能优化,我们需要用基于统计的科学方法来看待,这也就是火焰图采样的意义。过早优化是万恶之源。对于那些调用次数频繁、消耗 CPU 很高的热代码,我们才有优化的必要。
在实际的生产应用中,我认为 shared dict 这一层缓存是必须的。貌似大家都只记得 lruca che 的好,数据格式没限制、不需要反序列化、不需要根据 k/v 体积算内存空间、worker 间独立不相互争抢、没有读写锁、性能高云云。
但是,却忘记了它最致命的一个弱点,就是 lru cache 的生命周期是跟着 worker 走的。每当Nginx reload 时,这部分缓存会全部丢失,这时候,如果没有 shared dict,那 L3 的数据源分分钟被打挂。
当然,这是并发比较高的情况下,但是既然用到了缓存,就说明业务体量肯定不会小,也就是刚刚的分析仍然适用。
大部分情况下,确实如你所说,共享字典在 reload 的时候不会丢失,所以它有存在的必要性。但也有一种特例,那就是,如果在 init 阶段或者 init_worker 阶段,就能从 L3 也就是数据源主动获取到所有数据,那么只有 lru cache 也是可以接受的。
举例来说,比如开源 API 网关 APISIX 的数据源在 etcd 中,它只在 init_worker 阶段,从 etcd 中获取数据并缓存在lru cache 中,后面的缓存更新,都是通过 etcd 的 watch 机制来主动获取的。这样一来,即使 Nginx reload ,也不会有缓存风暴产生。
多年前,我负责的一个系统在每天凌晨 1 点钟左右时,数据库资源就会被耗尽,并导致整个系统雪崩。当时,我们白天排查代码中的计划任务,到了晚上,团队的同学们就蹲守在公司等 bug 复现,复现的时候再去查看各自子模块的运行状态。这样下来,直到第三个晚上才找到了 bug 的元凶。
我的这个经历,和 Solaris 几个系统工程师创造 Dtrace 的背景很类似。当时 Solaris 的工程师们,也是花了几天几夜的时间排查一个诡异的线上问题,最后才发现是因为一个配置写错了。但和我不同的是,Solaris 的工程师决定彻底避免这种问题,于是发明了 Dtrace,专门用于动态调试。
动态调试,也叫做活体调试。和 GDB 这种静态调试工具不同,动态调试可以调试线上的服务,而对调试的程序而言,整个调试过程是无感知、无侵入的,不用你修改代码,更不用重启。打一个比方,动态调试就像 X 光,可以在病人无感知的情况下检查身体,而不需要抽血和胃镜。
Dtrace 便是最早的动态追踪框架,受到它的影响,其他系统中也逐渐出现了类似的动态调试工具。比如,Red Hat 的工程师,就在 Linux 平台上创造了 Systemtap
Systemtap 有自己的 DSL,也就是小语言,可以用来设置探测点。
Systemtap 的工作原理,是将上述 stap 脚本转换为 C,运行系统 C 编译器来创建 kernel 模块。当模块被加载的时候,它会通过 hook 内核的方式,来激活所有的探测事件。
对于内核和性能分析工程师来说,只有 Systemtap 还是不够用的。首先, Systemtap 并没有默认进入系统内核;其次,它的工作原理决定了它的启动速度比较慢,而且有可能对系统的正常运行造成影响。
eBPF(extended BPF)则是最近几年 Linux 内核中新增的特性。相比 Systemtap,eBPF有内核直接支持、不会死机、启动速度快等优点;同时,它并没有使用 DSL,而是直接使用了 C 语言的语法,所以也大大降低了它的上手难度。
对于 on CPU 火焰图来说,色块的宽度是函数占用的 CPU 时间百分比,色块越宽,则说明性能消耗越大。如果出现一个平顶的山峰,那它就是性能的瓶颈所在。而色块的长度,代表的是函数调用的深度,最顶端的框显示正在运行的函数,在它之下的都是这个函数的调用者。所以,在下面的函数是上面函数的父函数,山峰越高,则说明调用的函数层级越深。
哪怕是动态跟踪这种无侵入的技术,也并不是完美的。它只能检测某一个单独的进程,而且一般情况下,我们只短暂开启它,以使用这段时间内的采样数据。所以,如果你需要跨越多个服务,或者是进行长时间的检测,还是需要 opentracing (类似Arthas?OpenTracing可以在系统的各处埋点,通过 Trace ID 把多个 Span 组成的调用链和埋点数据上报到服务端,进行分析和图形化的展现。这样就可以发现很多隐藏的问题,而且历史数据都会保存下来,方便我们随时对比和查看。)这样的分布式追踪技术。
不过,ngx.balancer 还比较底层,虽然它有设置上游的能力,但动态上游的实现远非如此简单。所以,在 ngx.balancer 前面还需要两个功能:
一是上游的选择算法,究竟是一致性哈希,还是 roundrobin;
二是上游的健康检查机制,这个机制需要剔除掉不健康的上游,并且需要在不健康的上游变健康的时候,重新把它加入进来。
而OpenResty 官方的 lua-resty-balancer 这个库中,则包含了 resty.chash 和 resty.roundrobin 两类算法来完成第一个功能,并且有 lua-resty-upstream-healthcheck 来尝试完成第二个功能。
不过,这其中还是有两个问题。
第一点,缺少最后一公里的完整实现。把 ngx.balancer、lua-resty-balancer 和 lua-resty-upstream-healthcheck 整合并实现动态上游的功能,还是需要一些工作量的,这就拦住了大部分的开发者。
第二点,lua-resty-upstream-healthcheck 的实现并不完整,只有被动的健康检查,而没有主动的健康检查。
简单解释一下,这里的被动健康检查,是指由终端的请求触发,进而分析上游的返回值来作为健康与否的判断条件。如果没有终端请求,那么上游是否健康就无从得知了。而主动健康检查就可以弥补这个缺陷,它使用 ngx.timer 定时去轮询指定的上游接口,来检测健康状态。
所以,在实际的实践中,我们通常推荐使用 lua-resty-healthcheck 这个库,来完成上游的健康检查。它的优点是包含了主动和被动的健康检查,而且在多个项目中都经过了验证,可靠性更高。
压测的时间一定不能太短,几秒钟的压测是没有意义的,不然很有可能服务端的程序还没加载完热数据,压测就已经结束了。同时,在压测期间,你需要使用 top 或者 htop 这样的监控工具,来确认服务端目标程序是否跑满 CPU。
从现象上来看,如果 CPU 满载,而且压测停止后,CPU 和内存占用迅速降低,那么恭喜你,这次压测顺利完成。但如果有下面这样的异常,作为服务端开发的你就得特别留意了。
CPU 不能满载。这不会是 wrk 的问题,可能是网络的限制,更可能是你的代码中有阻塞的操作。你可以通过 review 代码来确定,也可以使用 off CPU 火焰图来确定。
CPU 一直满载,即使压测停止仍然如此。这说明在代码中存在热循环,可能是正则表达式引起的,也可能是 LuaJIT 的 bug 引起的,这两点都是我在真实的环境中遇到过的问题。这时,你就需要用 on CPU 火焰图来确定了。
最后再来一起看下 wrk 的统计结果。关于这个结果,我们一般会关注两个值:
第一个是 QPS,也就是 Requests/sec: 16582.76,这个数据很直接,表示服务端每秒钟处理了多少请求。
第二个是延时 Latency 595.39us 178.51us 22.24ms 90.63%,这个数据和 QPS 一样重要,它体现了系统的响应速度。比如对于网关的应用来讲,我们就希望能够把延时控制在 1 毫秒以内。
另外, wrk 还提供了 latency 参数,可以把延时的分布百分比详细地打印出来,比如:
Latency Distribution
50% 134.00us
75% 180.00us
90% 247.00us
99% 552.00us
不过,wrk 的延时分布数据并不准确,因为它人为地加入了网络和工具的扰动,放大了延时,这一点需要你特别注意。
一般来说,我们肯定希望排除所有网络的干扰,单独测试出服务的性能极限来。出于这个目的,我们可以有两种搭建网络的方法来做压测。
第一种方法,把 wrk 和服务端程序都部署在同一台性能比较好的机器上。比如, 我们在 Nginx 中开启 8 个 worker,剩下的几个 CPU 资源分给 wrk。这样一来,就只有本地的网络通信,可以把网络的影响降到最低。
第二种方法,用专门的路由器搭建一个局域网,把 wrk 所在的机器和服务端所在的机器连在一起。
之所以不推荐你在已有的网络中直接测试,是因为大部分的网络中都存在交换机和防火墙,它们可能会对大流量的压测进行限制,造成测试结果的不准确。
另外,关于性能测试工具,我还想再多提几句。性能测试工具可能存在 Coordinated Omission 问题,在分析工具的延时数据的时候,你一定要特别留意。
简单地说,Coordinated Omission(协调遗漏) 是指,在做压力测试时,对于响应来说,只统计发送和收到回复之间的时间是不够的,这只是服务时间,这样统计会遗漏很多潜在的问题。因此,我们还需要把测试请求的等待时间也计算在内,这个整体才算是用户关心的响应时间。当然,如果你的服务端程序可能会出现阻塞,一定需要考虑这个问题,否则就可以忽略掉了。
作为服务端开发工程师,我们并不会对动态调试的工具集做深入的学习,大都是停留在使用的这个层面上,最多去编写一些简单的 stap 脚本。更底层的,比如 CPU 缓存、体系结构、编译器等,那就是性能工程师的领域了。
在 OpenResty 中有两个开源项目:openresty-systemtap-toolkit 和 stapxx 。它们是基于 Systemtap 封装好的工具集,用于 Nginx 和 OpenResty 的实时分析和诊断。它们可以覆盖 on CPU、off CPU、共享字典、垃圾回收、请求延迟、内存池、连接池、文件访问等常用的功能和调试场景。
OpenResty 的最新版本 1.15.8 默认开启了 LuaJIT GC64 模式,但是 openresty-systemtap-toolkit 和 stapxx 并没有跟着做对应的修改,这就会导致里面的工具都无法正常使用。
ngx-lua-shdict 是一个 perl 的脚本,但具体的实现和 perl 并没有关系,perl 只是被用来生成了 stap 脚本并运行起来
要生成 C 级别的 on CPU 火焰图,你需要使用 systemtap-toolkit 中的sample-bt;而 Lua 级别的 on CPU 火焰图,则是由 stapxx 中的 lj-lua-stacks 来生成的。
sample-bt 这个脚本,可以对你指定的任意用户进程(不仅限于 Nginx 和 OpenResty 进程),来进行调用栈的采样。
接着我们再来看下如何采样 off CPU,你需要使用的脚本是 systemtap-toolkit 中的 sample-bt-off-cpu。它的使用方法和 sample-bt 类似。
在stapxx 中,分析延迟的工具是epoll-loop-blocking-distr,它会对指定的用户进程进行采样,并输出连续的 epoll_wait 系统调用之间的延迟分布:
ngx-single-req-latency 这个工具和工具集里面的大部分工具并不太一样。其他工具,多是基于大量的采样和统计分析,得出一个数学上的分布结论。而 ngx-single-req-latency 分析的却是单个的请求,跟踪出单个请求在 OpenResty 中各个阶段的耗时,比如 rewrite、access、content 阶段以及上游的耗时。
其实,在追踪技术方面,OpenResty 和其他的开发语言、平台相比,还有一个比较大的不同之处,希望你可以慢慢体会:
保持代码基的简洁和稳定,不要在其中增加探针,而是通过外部动态跟踪的技术来进行采样。
你可以看到, color 的第一个元素变为了 orange。当然,你也可以不指定下标,这样就会默认插入队尾。
这里我必须说明的是,table.insert 虽然是一个很常见的操作,但性能并不乐观。如果你不是根据指定下标来插入元素,那么每次都需要调用 LuaJIT 的 lj_tab_len 来获取数组的长度,以便插入队尾。正如我们在 table.getn 中提到的,获取 table 长度的时间复杂度为 O(n) 。
# 获取数组长度的时间复杂度也是 n
LuaJIT 的 table 扩展函数。LuaJIT 在标准 Lua 的基础上,扩展了两个很有用的 table 函数,分别用来新建和清空一个 table
第一个是table.new(narray, nhash) 函数。这个函数,会预先分配好指定的数组和哈希的空间大小,而不是在插入元素时自增长,这也是它的两个参数 narray 和 nhash 的含义。自增长是一个代价比较高的操作,会涉及到空间分配、resize 和 rehash 等,我们应该尽量避免。
我们来看清空函数table.clear() 。它用来清空某个 table 里的所有数据,但并不会释放数组和哈希部分占用的内存。所以,它在循环利用 Lua table 时非常有用,可以避免反复创建和销毁 table 的开销。
OpenResty 自己维护的 LuaJIT 分支,也对 table 做了扩展,它新增了几个 API:table.isempty、table.isarray、 table.nkeys 和 table.clone。
Lua 并不是一个面向对象(Object Orientation)的语言,但我们可以使用 metatable 来实现 OO。
lua-resty-mysql 是 OpenResty 官方的 MySQL 客户端,里面就使用元表模拟了类和类方法,它的使用方式如下所示:
1 | $ resty -e 'local mysql = require "resty.mysql" -- 先引用 lua-resty 库 |
这几行代码很好理解,唯一可能给你造成困扰的是:
在调用类方法的时候,为什么是冒号而不是点号呢?
其实,在这里冒号和点号都是可以的,db:set_timeout(1000) 和 db.set_timeout(db, 1000) 是完全等价的。冒号是 Lua 中的一个语法糖,可以省略掉函数的第一个参数 self。
1 | local _M = { _VERSION = '0.21' } -- 使用 table 模拟类 |
你可以看到,_M 这个 table 模拟了一个类,初始化时,它只有 _VERSION 这一个成员变量,并在随后定义了 _M.set_timeout 等成员函数。在 _M.new(self) 这个构造函数中,我们返回了一个 table,这个 table 的元表就是 mt,而 mt 的 __index 元方法指向了 _M,这样,返回的这个 table 就模拟了类 _M 的实例。
为什么 lua-resty-mysql 库要模拟 OO 来做一层封装呢?
luajit 创建 GCStr 的时候是使用 lj_mem_newt(L, size+len+1)来申请内存,len 是payload 的长度。
在 OpenResty 的请求处理模型中,协程的生命周期与请求的生命周期紧密绑定。它在请求处理的早期阶段(如 access_by_lua*)被创建,在 I/O 操作期间可能多次挂起和恢复,最终在请求结束时被销毁。然而,一个核心的挑战在于,OpenResty 本身并未向用户代码暴露一个简单、稳定且唯一的协程 ID。
直接在纯 Lua 代码层面追踪每一次对象创建是困难且低效的。一个更强大、更彻底的方法是在更低的层次上拦截内存分配行为。LuaJIT 的内部内存管理器在需要内存时,最终会调用底层的系统内存分配器,例如 glibc 库提供的 malloc、realloc 和 free 等函数 。这个调用点就是我们进行拦截(hook)的理想位置。
目标更为具体:不仅要记录分配事件,还要将每一次分配与当前正在处理的特定请求关联起来。这是我们的方法与通用全局分析器的核心区别。
实现这一目标的关键技术是 LuaJIT FFI 。FFI 是一个强大的机制,它允许 Lua 代码直接调用 C 语言函数和使用 C 语言的数据结构。我们将利用 FFI 来构建我们的自定义分析器,并与底层的 C 函数进行交互。值得注意的是,通过 ffi.C.malloc 分配的内存是不受 LuaJIT 垃圾回收器(GC)管理的,除非显式地使用 ffi.gc 进行包装,这一点对于理解内存行为至关重要 。
最直接且功能最强大的方法是使用 Lua 的 C API lua_setallocf 来替换 LuaJIT 默认的内存分配函数。我们可以编写一个 C 库,其中包含我们的自定义分配器逻辑,然后通过 FFI 在 OpenResty 启动时加载并执行它。
这个 Lua 模块是用户与分析框架交互的接口。它将负责管理分析的生命周期,并处理从 C 层回调上来的数据。
通过 lua_setallocf 建立了一个从最底层的内存分配到 Lua 层的回调通道。然后,利用 ngx.ctx 存储的请求 ID,在 Lua 层将这些底层的、无上下文的分配事件,精确地归属到每一个具体的请求上。
然而,这个手动实现的框架也暴露了软件工程中的“观察者效应”。测量系统本身的行为会改变被测系统的行为。首先,为每一次内存分配增加 C 函数和 Lua 函数的调用开销,会给系统带来不可忽视的性能损耗。其次,用于存储统计信息的全局 profiler_stats 表,在高并发下可能会迅速膨胀,给 LuaJIT 的垃圾回收器带来巨大压力,甚至自身成为一个新的性能瓶颈 。垃圾回收的性能本身就是一个复杂问题,频繁的 GC 周期会消耗 CPU 资源并可能导致服务暂停 。最后,在 C 层和 Lua 层之间安全、高效地传递上下文(例如,通过一个线程不安全的全局变量 current_req_id)是一种复杂的、容易出错的实现方式。
综上所述,虽然这个手动框架在技术上是可行的,并且是一个极好的学习和调试工具,但其固有的侵入性、性能开销和复杂性,使其不适合在生产环境中长期运行。它揭示了构建此类工具的内在困难,并为讨论更先进、非侵入式的生产级解决方案(如动态追踪)奠定了基础。
我们框架的核心产出是两个关键指标:total_bytes(净内存分配字节数)和 alloc_count(内存分配次数)。通过分析这两个指标的组合,可以识别出多种典型的低效代码模式。
高 alloc_count,低 total_bytes:
模式:这种情况是循环中存在低效操作的典型标志。代码在短时间内进行了大量的小内存分配。
常见原因:在 Lua 中,最常见的原因是循环内的字符串拼接。例如,local str = “”; for i=1,1000 do str = str.. “data” end。每一次 .. 操作都会创建一个新的字符串对象,导致大量的内存分配和回收。
诊断路径:当日志中出现这种模式时,应立即审查请求处理路径中的所有循环,特别是涉及字符串处理、table 创建或闭包生成的部分。
高 total_bytes,低 alloc_count:
模式:这表明代码在一次或几次操作中分配了非常大的内存块。
常见原因:
一次性从文件或网络读取大量数据到内存中。
解码一个非常大的 JSON 或其他格式的数据负载。
从数据库或缓存中获取了一个包含大量数据的巨大结果集。
诊断路径:应检查与外部数据源交互的代码,分析返回数据的大小。确认是否有必要一次性加载所有数据,或者是否可以采用流式处理或分页的方式来降低单次内存峰值。
高 alloc_count 且高 total_bytes:
模式:这是最严重的情况,表明代码可能正在以一种低效的方式处理大量数据。
常见原因:例如,从数据库获取了大量记录,然后在循环中对每条记录进行复杂的字符串处理和对象转换。
诊断路径:需要结合以上两种模式的分析方法,既要优化循环内的操作,也要考虑减少一次性加载的数据量。
像 openresty-systemtap-toolkit 中包含的工具,以及更现代的 eBPF 技术,它们在操作系统内核或接近内核的层面运行,提供了一种全局的、“上帝视角”的系统视图 。
“在整个 Nginx 工作进程中,哪个 C 函数或 Lua 函数消耗的 CPU 时间最多?”
“系统是否在内核空间花费了大量时间等待 I/O?”
“内存分配主要发生在哪些代码路径?”
例如,SystemTap 可能会发现函数 lj_BC_TSETM(LuaJIT 中用于 table 赋值的字节码)非常热门

penResty XRay 是一个商业级的性能分析平台,它旨在解决用户所面临的这类复杂问题,但其实现方式与手动框架完全不同:它完全是非侵入式的 。这意味着使用 XRay 时,无需修改任何一行应用代码,无需重新编译程序,甚至无需重启正在运行的服务进程 。
该技术的核心是动态追踪。它利用操作系统底层的能力(如 SystemTap、eBPF 等,但在其上封装了强大的抽象层和分析引擎),从外部“探查”正在运行的进程,而不是像手动框架那样从内部“植入”代码 。这种“由外而内”的分析方法,从根本上保证了生产环境的安全性和稳定性。
动态追踪工具不仅能收集数据,更重要的是能以极其直观的方式呈现数据。火焰图(Flame Graph)是其中最具代表性的一种可视化技术,它能够将海量的性能样本数据转换成一张易于理解的图形,帮助工程师快速定位性能瓶颈 。
CPU 火焰图: CPU 火焰图展示了 CPU 时间在不同函数调用栈上的分布情况。在图中,每个矩形代表一个函数,其宽度与该函数(及其调用的所有子函数)占用的 CPU 时间成正比。Y 轴代表调用栈的深度,上层函数由下层函数调用。通过观察图中那些“宽大的平顶山”,工程师可以立即识别出消耗 CPU 最多的代码路径 。这比手动添加计时器并分析日志要直观和高效得多。
内存火焰图: 这是火焰图的一个强大变种 。在内存火焰图中,矩形的宽度不再代表 CPU 时间,而是代表由该函数调用路径所分配的内存大小。通过内存火焰图,可以一目了然地回答“谁在分配内存?”这个问题。这正是我们在第 2 节中试图通过复杂的手动框架来收集的数据,而动态追踪工具可以自动、无侵入地生成这种可视化结果。
拿回调洪峰举例,最重要的目的则是“削峰填谷”,这一秒不能同时处理那么多,就放到下一秒处理,只要这类请求允许一定的延迟,那就没必要当下全部处理掉,把收敛点放后面些也没事。这样也有利于让更多系统资源抽身去处理其他的“洪峰”。
因此,PID控制器的思想其实是契合的。
反馈理论的要素包括三个部分:测量、比较和执行。测量关键的是被控变量的实际值,与期望值相比较,用这个偏差来纠正系统的响应,执行调节控制。
用户洪峰需要考虑的因素:
允许访问的速率:令牌发放的速度r
系统承受的最大洪峰:当令牌桶满的时候,洪峰到达,这时候应用承受最大的QPS冲击 = 桶的容量 + 该秒令牌桶发放的速度r
洪峰爆发的间隔时间:下一次洪峰爆发前,尽量填满令牌桶
而 sentinel 的实现其实是参考了 TCP 中的 BBR 算法,在 BBR 的基础上加上了 load 作为启发阈值的判断
这里还体现出一个单机限速相较于分布式的优势点:我通过单机限速可以平滑到单个后端服务的流量,而分布式限速做不到这一点,一个集中式漏桶中心可以平滑经过这个漏桶的流量,而如果分布式限速,那这个分布式漏桶的速率等于它下面的 pod 的速率之和(比如 3 个 pod,每个 10qps 的能力,分布式漏桶应该设置为 30),各个 pod 会去漏桶中申请,于是瞬时的 30 流量被平滑成 1/30s 间隔的请求队列,所以极端情况下,三个 pod 都要承受间隔为 1/30 的请求序列,过载保护不成立。而单机限速就能很好地解决这个问题
虽然后者增加了请求的 RTT,但确保了服务的高可用和整体吞吐量的稳定。
新加坡
诱因是某个用户的请求量突增,但也暴露了apiv3的处理性能问题。结合现网和线下测试的情况看,8c16的apiv3的吞吐量大概是 100qps/s, 容易被突发请求打满。
IAS 服务大量查询请求 DescribeTargets 导致DB高负载(只读库被打满)
导致DB高负载导致请求成功率下降,排查发现有慢查询,但是api成功率还没有回复,开始限制IAS服务的DescribeTargets查询频率,db中kill积压sql,ro库负载已经恢复,成功率开始恢复。
广州
用户sql返回超大行。不一定是请求量最大的接口对系统的影响最大,有些接口虽然请求量小,但是逻辑较重,每分钟数百个请求就可以将系统打垮。
自研用户的CLB规则复杂,DescribeClusterResources 接口从数据库中查出的数据过大导致高负载。查找到是服务角色调用的该接口。
自研用户的CLB规则复杂,DescribeClusterResources 接口从数据库中查出的数据过大导致高负载。返回客户端json太长。
成功率有抖动,tmp收到单核高负载告警
广州
访问cam耗时增加。cam耗时增加会增加db连接保持时间,引起db连接数增加,引发连锁反应 clb-api-v3 cpu打满,数据库cpu也被打满,最后重启服务恢复。
8个slave 每个slave100个协程
DescribeLoadBalancers
单个请求耗时7.5秒左右,db连接数210左右,无async queue is full日志。cam延时增加导致任务积压,db连接数增加。
有async queue is full日志,
listen queue溢出,uwsgi来不及建连,调大listen=200后正常(冷重启才生效,热重启不生效),默认100,同时需要调大内核/proc/sys/net/core/somaxconn到200。
unix fd出现大量Resource temporarily unavailable
情况一 (最可能):处理“惊群”的副作用
情况二:边沿触发 (Edge-Triggered, ET) 模式下的标准操作
高性能服务器(如Nginx/uWSGI)更倾向于使用epoll的ET模式。
在ET模式下,当有新连接到来时,epoll只通知Worker一次。
Worker被唤醒后,它有责任在一个循环中不断调用accept4(),直到把Accept Queue中的所有连接都取干净为止。
那么,Worker怎么知道队列已经取干净了呢?它就是在最后一次accept4()调用时,收到 -1 (EAGAIN) 这个返回值。
所以,这个EAGAIN在ET模式下是一个必需的信号,它告诉Worker:“新连接已全部处理完毕,你可以回去继续等epoll通知了。”
这同样是epoll的ET(边沿触发)模式下的标准操作。
事件通知: Nginx向fd=16发送了一批数据。内核将数据放入RX缓冲区。epoll通知uWSGI的Worker:“fd=16有数据可读了!”(注意,ET模式只通知这一次)。
循环读取: Worker被唤醒,它知道自己必须一次性把fd=16的RX缓冲区读完,否则epoll不会再提醒它。
执行循环: Worker进入一个循环,不断调用 recvfrom(16, …)。
第一次调用,读到1024字节。
第N次调用,读到最后剩下的512字节。RX缓冲区现在空了。
获取“读完”信号: Worker并不知道缓冲区空了,它会尝试第N+1次调用 recvfrom(16, …)。
EAGAIN返回: 因为缓冲区已空,且socket是非阻塞的,recvfrom立即失败,返回-1,并将errno设置为EAGAIN。
循环结束: Worker捕获到这个EAGAIN,它就明白了:“OK,fd=16的数据我已经全部读完了。” 于是它跳出读取循环,开始去处理刚才读到的所有数据(例如,解析uwsgi协议包,调用Python应用)。
一个请求用一个协程处理,处理请求期间,协程和db保持长连接,cam耗时增加会增加db连接保持时间,引起db连接数增加。请求积压后,新增请求会卡在db读,进而引起db连接数进一步增加,随着请求进一步累计,cpu负载进一步增加,引起雪崩。cam接口耗时高,为啥引起高负载?
自测高负载可以在几秒内恢复,现网积压任务太多,且不断有新增请求,无法在预期时间内恢复。
并发连接数,根据运维扫描结果调整
现有方案依赖于uwsgi框架的队列进行流量削峰,但单个uwsgi实例的处理能力有限,无法满足高并发业务场景的需求,存在请求堆积、响应延迟甚至服务不可用的风险。为保障系统稳定性和业务连续性,需对V3组件进行能力优化,完善流控与过载保护机制。
过载检测阈值的参考标准(如基于历史峰值设定动态阈值)、
增加性能指标要求(如流控决策延迟≤10ms
线程(Thread)与 OpenResty 协程(Coroutine)的深层性能差异
线程比 OpenResty 的协程慢,其根本原因在于调度者、上下文切换的成本和内存开销这三个维度的巨大差异。
1.1. 调度者与切换机制
调度者与切换机制
线程 (Thread): 操作系统内核调度,抢占式
内核级操作: 线程是操作系统能够调度的最小单位。线程的创建、销毁和切换(Context Switch)完全由操作系统内核(Kernel)掌控 。当一个线程的时间片用完,或者因 I/O 操作阻塞时,会触发一个中断,执行流从用户态(User Mode)陷入内核态(Kernel Mode)。
抢占式 (Preemptive): 切换时机是不可预测的。内核调度器根据优先级和调度算法,随时可能中断一个正在运行的线程,将 CPU 时间分配给另一个线程 。 (可能切换次数还比较多)
高昂的模式切换: 从用户态到内核态的切换本身就是一个昂贵的操作,因为它需要 CPU 执行特权指令,并刷新部分指令流水线 。
协程 (Coroutine): 用户态调度,协作式
用户级操作: OpenResty 的协程(本质上是 Lua Coroutine)完全运行在用户态。它们的调度由 Nginx 的事件循环和 LuaJIT 虚拟机协同管理,完全不涉及内核 。
协作式 (Cooperative): 协程的切换只发生在代码中明确定义的“让出点”(Yield Points),例如执行 ngx.sleep、非阻塞 I/O 操作(如 cosocket 通信)等。程序主动放弃执行权,控制权交还给 Nginx 的调度器 。
无模式切换: 整个切换过程就是一次在用户态内部的函数调用,速度极快,几乎和普通函数调用的开销相当 。
上下文切换的成本 (Context Switch Cost)
这是性能差异的核心所在。
线程切换:
保存完整现场: 内核必须保存即将被换下线程的所有 CPU 状态。这包括:
所有通用寄存器、栈指针(Stack Pointer)、指令指针(Instruction Pointer)。
浮点数寄存器和 SIMD 寄存器状态 。
线程相关的内核数据结构(如 TCB - Thread Control Block)。
加载新现场: 内核随后加载即将运行线程的完整 CPU 状态。
缓存失效 (Cache Pollution): 这是巨大的间接成本。被换上来的线程,其代码和数据很可能不在 CPU 的 L1/L2/L3 缓存中,会导致大量的缓存未命中(Cache Miss),CPU 需要从慢速的主内存中重新加载数据,严重拖慢执行速度 。
协程切换:
保存最小现场: 切换时,仅需保存与 Lua 执行相关的少量上下文。这通常只是几个关键的寄存器(如 Lua 的指令指针、栈顶指针)和当前的 Lua 栈 。不需要保存整个 CPU 的寄存器状态到内存。
缓存友好:由于所有协程都在同一个 Nginx worker 线程内运行,它们共享相同的地址空间和 CPU 缓存。切换协程时,下一个协程需要的数据很可能已经在 CPU 缓存中,缓存命中率非常高,几乎没有缓存污染问题 。
内存开销
线程: 每个线程都需要一个独立的、由内核管理的栈空间。在 Linux 上,这个栈的默认大小通常是几兆字节(例如 8MB)。这意味着一个进程能创建的线程数量是有限的,几千个线程就可能耗尽系统内存 。
协程: 协程的栈是在用户态的堆(Heap)上分配的,非常小(通常只有几 KB),并且可以按需增长。一个 Nginx worker 进程可以轻松地同时管理成千上万个协程,内存开销极低 。
总结: 线程的慢,是慢在由内核主导的、抢占式的、保存完整 CPU 状态的“重型”上下文切换,以及它带来的巨大内存开销和严重的 CPU 缓存污染。而 OpenResty 的协程快,是快在用户态的、协作式的、仅保存少量必要信息的“轻量级”切换,它对 CPU 缓存极其友好,且内存占用极小。
这就是为什么协程切换更高效: 协程切换是协作式的,并且它发生在同一个线程(同一个项目组)内部。
指令缓存(L1i)命中率极高: 协程A和协程B都是Python应用的一部分。它们很可能在执行完全相同的代码(例如,同一个JSON解析库、同一个ORM框架、同一个Web框架的代码)。这些代码指令在协程A执行时就已经加载到CPU缓存中,协程B可以直接使用。
数据缓存(L1d/L2)命中率较高: 它们共享同一个线程的内存空间,可以共享一些应用级的缓存数据(如配置信息)。它们各自的私有数据(如不同的请求体)确实会T cache miss,但公用代码和数据的缓存命中,已经节省了巨量的开销。
内核无感知: “大老板”(内核)完全不知道“财务组”内部自己换了两个小任务在做。它始终认为就是“财务组”(线程A)在工作,因此不会发生内核级的上下文切换,TLB也不会被刷新。
开销一:切换独立的虚拟内存空间(“换大楼”)
这是进程和线程最根本的区别。
线程:同一进程下的所有线程,共享同一个虚拟内存空间(它们在同一栋“摩天大楼”里,只是楼层不同)。
进程:每个进程都有自己独立的、受保护的虚拟内存空间(每个公司都在一栋完全独立的“摩天大楼”里)。
当你(CPU)从进程A切换到进程B时,你必须从A大楼出来,进入B大楼。在CPU层面,这意味着:
切换页表(Page Tables):操作系统必须告诉CPU(的MMU,内存管理单元),“别再用A公司的地址簿(页表)了,现在开始改用B公司的地址簿(页表)”。(在x86上,这对应着 CR3 控制寄存器的更新)。
清空地址缓存(TLB Flush):这是最致命的开销。
开销二:TLB 刷新(“扔掉旧的地址簿速记”)
什么是TLB?
CPU去主内存(文件柜)里按“虚拟地址”找“物理地址”是一个很慢的过程(需要查询多级页表)。
为了加速,CPU内置了一个超高速缓存,叫TLB (Translation Lookaside Buffer),它相当于你(CPU)的一本“地址簿速记”,记着“虚拟地址A -> 物理地址X”这种最近用过的映射。
切换时发生什么?
当你从“A公司”切换到“B公司”时,你那本“A公司”的地址簿速记(TLB)瞬间变得一文不值,因为B公司的“财务室”和A公司的“财务室”在物理内存中完全不是一个地方。
操作系统会强制CPU“刷新”(Flush)整个TLB,把这本速记全部清空。
为什么慢?
当进程B开始运行时,它访问的每一个内存地址(无论是代码还是数据),在TLB里都找不到。
这会导致连续不断的“TLB Miss”。
每一次Miss,CPU都不得不暂停执行,去主内存(文件柜)里缓慢地查询页表,找到物理地址,然后再把它写回TLB,最后才能真正地访问数据。
这个“预热”TLB的过程,会给新切换上来的进程B带来巨大的初始性能惩罚。
Nginx 为什么如此之快?
Nginx 的高性能秘诀在于其颠覆传统的事件驱动、异步非阻塞的架构 。
Master-Worker 进程模型: Nginx 采用一个 Master 进程和多个 Worker 进程的架构。Master 进程负责管理配置和 Worker 进程,而真正处理请求的是 Worker 进程 。通常,Worker 进程的数量会设置为与服务器的 CPU 核心数相同,这可以充分利用多核 CPU 的性能,并避免了进程间不必要的上下文切换 。
事件驱动与事件循环: 与传统服务器(如 Apache 的 prefork 模式)为每个请求创建一个新进程或线程不同,Nginx 的每个 Worker 进程都是一个单线程的事件循环(Event Loop)。这个 Worker 进程可以同时处理成千上万个连接 。它不会为每个连接分配一个线程,从而极大地减少了内存消耗和上下文切换的开销 。
异步非阻塞 I/O: 这是 Nginx 高性能的核心。当一个请求需要进行 I/O 操作时(例如,读取客户端数据、向上游服务器转发请求、读取磁盘文件),Worker 进程不会傻傻地等待。它会发起一个非阻塞的 I/O 操作,然后将这个连接(文件描述符)注册到高效的事件通知机制中,接着立即去处理其他连接的事件 。 高效的事件通知机制 (epoll/kqueue): Nginx 充分利用了操作系统提供的最高效的 I/O 多路复用技术。在 Linux 上是 epoll,在 BSD/macOS 上是 kqueue 。这些机制允许单个进程高效地监控成千上万个文件描述符的状态。当某个连接的 I/O 操作完成时(例如,数据可读或可写),操作系统会通知 Nginx,Nginx 的事件循环再回过头来处理这个就绪的连接。这确保了 Worker 进程的 CPU 时间永远不会浪费在等待 I/O 上 。
一句话总结: Nginx 通过一个固定数量的 Worker 进程,利用 epoll/kqueue 实现了事件驱动的、异步非阻塞的 I/O 模型,从而可以用极低的内存和 CPU 资源,高效地处理海量的并发连接。
介绍 SystemTap?
是什么 (What it is): “SystemTap 是一个用于 Linux 系统的动态追踪和探测框架。您可以把它想象成一个给正在运行的 Linux 内核和应用程序做‘听诊’的工具。它允许我们实时、深入地观察系统内部的活动细节,而无需重新编译内核或重启目标程序。”
怎么做 (How it works): “它的工作原理是这样的:我们用一种专门的脚本语言编写一个探测脚本,定义我们感兴趣的‘探测点’(Probe Points)和当这些点被触发时要执行的‘处理函数’(Handler)。SystemTap 会把这个脚本动态地翻译成 C 代码,编译成一个临时的内核模块,然后安全地加载到正在运行的内核中。这些探测点可以是内核函数的入口/出口、系统调用、定时器事件,甚至是用户态程序的某个函数或代码行。当事件发生,我们的处理逻辑就会在内核上下文中执行,收集数据、进行过滤和聚合。脚本结束后,这个内核模块会被自动卸载,系统恢复原状,非常安全。”
为什么用 (Why it’s useful): “SystemTap 的核心价值在于它的灵活性和非侵入性。对于一些复杂的性能瓶颈或难以复现的 Bug,常规工具如 top、iostat 只能看到表面现象。例如,当发现磁盘 I/O 很高时,我们可以用 SystemTap 写一个简单的脚本,精确地定位到是哪个进程、哪个函数调用造成的 I/O,以及 I/O 的具体模式。它让我们能够回答‘为什么’,而不仅仅是‘是什么’。最关键的是,这一切都可以在生产环境的线上系统实时进行,而不需要停机或修改任何代码,这是它相比于传统调试手段(如加日志、重新编译)的巨大优势。”
C on CPU 与 Lua on CPU 火焰图的本质区别
虽然两者都是用于分析 CPU 性能瓶颈的火焰图,但它们的抽象层次和解读视角完全不同。
C on CPU 火焰图 (底层、虚拟机视角)
展示内容: 它展示的是原生机器代码的调用栈。图中的每一个函数块代表一个 C 函数。在 OpenResty 环境下,这些函数可能来自 Nginx 核心、第三方 C 模块、libc 等系统库,以及 LuaJIT 虚拟机自身的 C 实现(例如,负责垃圾回收的 lj_gc_ 函数,负责解释执行字节码的 lj_BC_ 函数等)。
解读: 这种火焰图告诉你 CPU 正在忙于执行哪些 C 代码。如果你看到一个很宽的 lj_gc_step 块,你知道 CPU 大量时间花在了垃圾回收上。但它无法直接告诉你是哪一段 Lua 代码导致了频繁的垃圾回收。它只能反映出 LuaJIT 这个“黑盒子”内部的繁忙之处,而无法揭示“黑盒子”繁忙的原因 。
Lua on CPU 火焰图 (高层、应用视角)
展示内容: 它展示的是Lua 语言层面的调用栈。图中的每一个函数块代表一个 Lua 函数,直接对应你的业务代码,例如 my_module.process_data 。
解读: 这种火焰图直接回答了“我的哪部分 Lua 代码最消耗 CPU?”这个问题。如果你看到 user_auth.lua 里的一个函数特别宽,那么性能瓶颈就一目了然。它甚至可以展示出 JIT 编译后的代码段(例如 trace#2:test.lua:8),告诉你 CPU 正在高效执行源于 test.lua 第 8 行的 JIT 编译路径 。这种图需要专门的、能够深入理解 LuaJIT 虚拟机的分析工具(如 OpenResty XRay)才能生成 。
一个形象的比喻:
C on CPU 火焰图就像是汽车修理工用热成像仪看引擎。他能发现引擎的某个部分特别热,但他不知道司机是在高速路上飞驰,还是在原地空挡踩油门。
Lua on CPU 火焰图则像是看汽车的行车电脑数据。它直接告诉你:“司机正挂在一档,把油门踩到了 7000 转”。它提供了业务逻辑层面的上下文。
总结: C on CPU 火焰图是从底层物理执行的角度看问题,告诉你“虚拟机在忙什么”。而 Lua on CPU 火焰图是从上层应用逻辑的角度看问题,告诉你“我的代码在忙什么”。两者是互补的:Lua 层的性能问题(比如循环里拼接字符串)最终会体现为 C 层的特定 VM 函数(比如内存分配和 GC)的繁忙。Lua 火焰图帮你定位业务代码,C 火焰图帮你理解其底层实现开销**。
系统调用 (System Call) 到底慢在哪里?
系统调用是应用程序(用户态,User Mode)请求操作系统(内核态,Kernel Mode)帮忙办事的“唯一通道”。
特权级切换(CPU模式切换)
这是最核心的开销。您的CPU必须从非特权的“用户态”(Ring 3)切换到全特权的“内核态”(Ring 0)。
这不是一个普通的函数调用(JUMP指令),而是一个特殊的、更慢的CPU指令(如syscall或int 0x80)。这个指令会清空CPU的一部分指令流水线,因为它是一个重大的“模式”变更。
保存用户态上下文(“存包”)
在您进入内核态之前,您必须把您手头所有的工作(CPU寄存器、程序计数器、栈指针等)全部保存起来。
内核需要把这些信息安全地保存在一个内核专属的内存区域(Kernel Stack)中。
为什么?因为CPU在内核态里要用它自己的寄存器和栈,它会完全覆盖您当前的工作。如果不保存,您就永远回不去了。
返回(再次“存包”和“切换”)
内核工作完成后,它需要恢复您之前保存的所有用户态寄存器。
再次执行一个特殊的“特权级切换”指令(如sysret或iret),CPU 从“内核态”(Ring 0)返回“用户态”(Ring 3)。
stap++ 脚本中用到的 lua_State 又是什么?
这是一个绝佳的问题,它揭示了“主动调用”和“被动观察”的天壤之别。
stap++(以及SystemTap, eBPF等)是一种外部的、内核态的、只读的追踪工具。它不是一个“额外的管理线程”。
回到我们的比喻: 如果说“管理线程”是试图冲进手术室、抢夺手术刀的另一个医生。
那么 stap++ 脚本就是站在手术室隔离窗外的“观察员”。
stap++ 脚本中用到的lua_State,不是一个让它去“调用”的对象,而是它“观察”的数据。
它是如何工作的?
“观察”而非“调用”:stap++ 永远不会去调用lua_call、lua_resume等任何lua_* API。它不会试图“重入”VM。
调试符号 (Debugging Symbols):stap++脚本(或其加载的工具集)会读取Nginx和LuaJIT的调试符号。它因此知道struct lua_State的内存布局。
被动读取 (Read-Only):当您的stap++探针(Probe)被触发时(例如,火焰图采样),操作系统会短暂地冻结Nginx Worker进程。
在进程被冻结的那一纳秒,stap++(在内核态)会像一个调试器(gdb)一样,去读取lua_State结构体在内存中的内容。
堆栈回溯 (Stack Walking):stap++脚本会读取L->ci(调用帧指针)、L->base(栈基址)、L->top(栈顶指针),然后通过这些指针去遍历Lua的调用栈,并从Proto结构体中读取函数名,从而“拼凑”出您在火焰图上看到的Lua层面的调用栈。
结论: stap++(火焰图工具)对lua_State的访问是“被动的、只读的、外部的”。它只是一个观察者,它在内核态读取lua_State的内存,以分析它当时的快照。
而您设想的“抢占式调度器”对lua_State的访问是“主动的、读写的、内部的”。它试图成为一个参与者,去修改lua_State的内部状态。
这就是为什么stap++可以安全地“使用”lua_State来生成火焰图,而“抢占式调度器”却会因“不可重入”而导致崩溃的原因。
线程调度本身是内核的功能,它不需要用户态发起系统调用。但是,一个导致调度的常见原因是用户态发起了阻塞型系统调用。
场景:一个阻塞的线程切换
假设线程T1(属于进程P1)正在运行。
阶段 1: 系统调用 (User -> Kernel)
线程T1在用户态执行,它需要读取一个文件,于是它调用了read()函数。
read()库函数会触发一个系统调用(例如syscall指令)。
CPU收到syscall指令,立即从用户态切换到内核态。
【保存 #1:用户态上下文】
目的:为了在系统调用返回时,能让T1在用户态继续执行。
保存了什么:CPU的最基本执行状态,主要包括:
RIP (Instruction Pointer / PC):用户态代码的下一条指令地址。
RSP (Stack Pointer):用户态栈的指针。
RFLAGS (Flags Register):CPU的状态标志。
保存在哪:保存在**线程T1的内核栈 (Kernel Stack)**上。
系统调用的消耗:
执行syscall和sysret指令的CPU开销。
保存和恢复上述“用户态上下文”的开销。
到此为止,只是一个系统调用,线程T1还在运行,只是换了模式。
阶段 2: 线程调度 (Kernel)
CPU在内核态执行read的内核代码。
内核发现要读的数据不在内存(Page Cache)中,必须从慢速硬盘读取。
内核决定T1必须休眠(阻塞)。
内核将T1的状态设置为BLOCKED,并将其从“运行队列”中移出,放入“等待队列”(等待I/O)。
内核直接调用内核函数 schedule()(这不是一个系统调用,因为我们已在内核态)。
schedule()函数决定换一个READY状态的线程T2来运行。
【保存 #2:内核态/完整上下文】
目的:为了在未来某个时刻(I/O完成后)能完整恢复T1。
保存了什么:T1的全部执行上下文,包括:
所有通用CPU寄存器(RAX, RBX, RCX…)。
FPU/SSE/AVX寄存器(浮点和向量计算单元的状态)。
指向其页表目录的指针(如CR3寄存器,即它的“内存地址簿”)。
T1的内核栈指针。
保存在哪:保存在Linux内核中线程T1的描述符(task_struct)中。
线程切换的消耗 (Context Switch):
直接消耗:执行schedule()调度算法的CPU时间 + 执行上述“保存T1完整上下文”和“加载T2完整上下文”的CPU时间。
间接消耗 (最昂贵的):
TLB 刷新: 如果T2和T1不属于同一个进程,内核必须刷新TLB(地址转译缓存)。导致T2刚运行时,所有内存访问都变慢(TLB Miss)。
CPU缓存失效:T2的代码和数据不在L1/L2/L3缓存中,导致大量的Cache Miss,CPU需要从主内存重新加载,性能急剧下降。
总结回答
线程调度需要系统调用吗?
抢占式调度(时间片用完)不需要。它由时钟中断(硬件中断)触发,直接在内核态完成。
阻塞式调度(如I/O等待)间接需要。它由一个阻塞型系统调用(如read)触发。
到底保存几次? 两次保存,目的不同。
保存 #1 (用户态上下文):每次系统调用都会发生。保存在内核栈。开销相对较小。
保存 #2 (完整上下文):只在线程切换时发生。保存在task_struct中。开销巨大。
到底有什么消耗?
系统调用消耗:特权级切换 + 保存/恢复用户态上下文。
线程切换消耗:保存/恢复完整上下文 + 调度器计算 + (最慢的) TLB刷新(如果跨进程)和CPU缓存失效。
- “用户态上下文”和“线程上下文”不是一回事对吧?
是的,您的理解是正确的。 它们不是一回事,它们是“子集”与“全集”的关系。
用户态上下文 (User-mode Context): 这是线程上下文的一个子集。它只包含线程在用户态执行时所需的最基本信息。它主要用于“进出内核”(即系统调用),而不是“切换线程”。
包含:程序计数器(PC/RIP,即下一条指令地址)、用户态栈指针(RSP)、CPU状态标志(RFLAGS)。
线程上下文 (Thread Context): 这是描述一个线程完整执行状态的全集。它包含了“用户态上下文”,还包含了它在内核态的所有状态。内核需要这个“完整快照”才能在未来任何时刻完美地恢复这个线程的运行。
包含:
用户态上下文(PC, RSP, RFLAGS)。
CPU通用寄存器(RAX, RBX, RCX… 所有的工作寄存器)。
FPU/SSE/AVX 寄存器(所有浮点和向量计算的状态)。
内核态上下文(例如,该线程的内核栈指针、指向其页表的指针CR3等)。
线程状态(如Running, Ready, Blocked等)。
总结:
系统调用(syscall)时,CPU硬件和内核只保存“用户态上下文”。
线程切换(Context Switch)时,内核必须保存“完整线程上下文”。
- 抢占式调度导致的线程切换(全流程)
您问的这个场景(抢占式)和我们之前讨论的(阻塞式)触发点完全不同,但切换的开销是类似的。
阻塞式切换是由线程主动调用read()等系统调用触发的。而抢占式切换是由硬件(时钟)被动触发的。
以下是当线程T1(属于进程P1)被线程T2(属于进程P2或P1)抢占时的详细步骤:
阶段 1:硬件中断(Hardware Interrupt)
时钟中断 (Timer Interrupt):
线程T1正在用户态快乐地执行CPU密集型计算。
CPU的时钟(Timer)发出一个硬件中断信号(例如“10毫秒到了”),通知CPU该“时间片”已用完。
CPU响应中断:
CPU立即停止执行线程T1的当前指令。
CPU立即从用户态切换到内核态。
【保存 #1:用户态上下文】
目的:为了处理完这个中断后,有可能会返回T1继续执行(如果调度器决定不切换)。
保存了什么:CPU硬件自动保存T1的用户态上下文(RIP, RSP, RFLAGS)。
保存到哪:压入线程T1的内核栈(Kernel Stack)。
跳转到中断处理器:
CPU跳转到内核中预先设定的“时钟中断处理器”代码。
阶段 2:内核调度与上下文切换
中断处理:
内核的时钟中断处理器运行。它首先更新系统时钟。
然后它会检查当前运行的线程T1的时间片是否真的用完了。
它发现T1的时间片确实用完了。
调用调度器 schedule():
内核决定需要进行一次抢占式调度。
内核在内核态调用schedule()函数。
调度器算法(例如CFS)运行,它根据优先级和公平性,决定T1应该“下CPU”,而线程T2(状态为READY)应该“上CPU”。
【保存 #2:完整线程上下文】
目的:为了在未来某个时间片能完整地恢复T1。
保存了什么:T1的全部执行状态。
所有CPU通用寄存器(RAX, RBX… T1在用户态的计算中间值)。
所有FPU/SSE/AVX寄存器(T1的浮点计算状态)。
T1的内核栈指针(KSP,这样T1下次被唤醒时,才知道自己在内核里干到了哪一步)。
指向T1页表的指针(如CR3寄存器中的值)。
保存到哪:保存在内核数据区中,线程T1的进程/线程控制块(task_struct)里。
【加载 #2:完整线程上下文】
调度器现在开始加载T2的完整上下文。
它找到T2的task_struct,将T2之前保存的所有寄存器(通用寄存器、FPU寄存器等)恢复到CPU中。
(关键开销点) 它加载T2的页表指针到CR3寄存器。
如果T1和T2属于不同进程:这个操作会导致CPU的TLB(地址转译缓存)被完全刷新。这是极其昂贵的开销。
如果T1和T2属于同一进程:它们的页表相同,此步骤被跳过。这是“线程切换”比“进程切换”快的主要原因。
返回与恢复:
T2的上下文已完全加载。
内核执行sysret或iret指令。
CPU从内核态切换回用户态。
CPU从T2的用户态上下文(RIP, RSP)中取出指令地址和栈指针,开始执行T2的代码。
总结消耗:
抢占式调度的消耗几乎等同于阻塞式调度的消耗,因为它们最终都执行了阶段2(上下文切换)。
直接消耗:保存T1和加载T2的所有寄存器(几百个字节的数据)所花费的CPU时间。
间接(最昂贵)消耗:
TLB 刷新(如果跨进程)。
CPU 缓存失效(Cache Pollution):T1运行时,L1/L2缓存里装满了T1的数据。T2被换上来后,它需要的数据全都不在缓存里,导致大量的Cache Miss,CPU必须从慢速的主内存中重新加载数据,性能急剧下降。这个开销是最大的。
- 为什么只保存KSP?User RSP(用户态栈指针)呢?
您问得太对了!User RSP (用户态栈指针) 绝对被保存了。
我之前的回答可能造成了歧义,让我们来澄清这个至关重要的两阶段保存过程:
User RSP 是在 阶段1(进入内核时) 被保存的。
KSP 是在 阶段2(切换线程时) 被保存的。
详细流程:
阶段 1: “进入”内核 (硬件/内核入口完成)
触发: 无论是抢占式的时钟中断,还是阻塞式的系统调用,CPU都会发生一次用户态 -> 内核态的切换。
保存 User RSP: 在CPU切换到内核态的瞬间,CPU硬件(或内核的入口汇编代码)会做一件关键的事:
找到当前线程T1的内核栈 (KSP)。
将T1的用户态上下文(RIP、RFLAGS 以及 RSP)压入(push)到T1自己的内核栈上。
此时状态:T1正在内核态运行(执行中断处理器或系统调用代码),它自己的用户态栈指针(User RSP)已经安全地躺在它自己的内核栈的底部。
阶段 2: “切换”线程 (内核调度器完成)
触发: 内核调度器(schedule())决定T1必须停止,换T2上。
保存 KSP: 现在要保存T1的“完整上下文”。
T1的用户态上下文(User RSP等)已经在T1的内核栈里了,很安全。
T1的CPU寄存器(RAX, RBX等)被保存到T1的task_struct中。
关键:内核现在需要保存的是T1在内核态的执行位置,也就是当前内核栈的栈顶指针 (KSP)。
保存在哪:T1的这个KSP被保存在T1的task_struct中。
为什么这个机制是完备的?
保存 KSP 就等于保存了 User RSP: task_struct (T1的档案) -> 保存了 KSP (T1的内核栈顶) KSP (内核栈) -> 包含了 User RSP (T1的用户栈)
您可以把task_struct想象成一个保险箱的登记册,KSP是您在银行的那个保险箱的钥匙。内核通过KSP(钥匙)就能打开T1的内核栈(保险箱),而T1的用户态上下文(User RSP,您的房产证)就安全地存放在这个保险箱里。
恢复时的流程(T2 -> T1):
内核从T1的task_struct中加载T1的KSP。
CPU的栈指针立即指向T1的内核栈。
内核恢复T1的寄存器(RAX等)。
内核执行iret(中断返回)或sysret(系统调用返回)指令。
这个指令会自动从T1的内核栈中弹出(pop)之前保存的User RSP和RIP,CPU切换回用户态,T1在用户态完美恢复。
- 线程切换也是会发生用户态内核态切换的对吧?
是的,但更精确的说法是: 线程切换 (Context Switch) 本身是一个纯粹的、只在内核态执行的动作,但它必须由一次“用户态 -> 内核态”的切换来触发,并最终以一次“内核态 -> 用户态”的切换来结束。
您不能在用户态发起线程切换。内核(中央控制室)是唯一有权调度(换人)的地方。
一个完整的、有意义的线程切换(T1 -> T2)的全生命周期,必然包含了两次特权级切换:
“进入” (User -> Kernel)
路径A (抢占式):线程T1正在用户态运行。时钟中断发生。CPU被迫从用户态切换到内核态,开始执行“时钟中断处理器”。
路径B (阻塞式):线程T1在用户态调用read()。syscall指令主动将CPU从用户态切换到内核态,开始执行“系统调用处理器”。
此时:CPU处于内核态,并且“代表”T1在工作。
“切换” (Kernel-Only)
在内核态中,schedule()函数被调用(无论是被中断处理器还是系统调用处理器触发)。
调度器决定T1下,T2上。
内核执行上下文切换:保存T1的完整状态到T1的task_struct,加载T2的完整状态从T2的task_struct。
此时:CPU仍然在内核态,但它现在“代表”T2在工作(它加载了T2的内核栈和页表)。
“退出” (Kernel -> User)
T2的内核代码执行完毕(例如,iret或sysret)。
CPU被迫从内核态切换回用户态,开始执行T2的用户态代码。
总结: [ T1 用户态 ] -> (切换 #1: User->Kernel) -> [ T1 内核态 ] -> (切换 #2: 线程T1->T2) -> [ T2 内核态 ] -> (切换 #3: Kernel->User) -> [ T2 用户态 ]
所以,您的两个问题是相辅相成的。线程切换是一个重量级的操作,它以一次User->Kernel切换为前提,其核心是Kernel->Kernel的上下文保存与加载,并以一次Kernel->User切换为收尾。
最简单、最常用且经过实践检验的方法是基于阈值的 AIMD(加性增、乘性减) 控制律,它直接使用我们计算出的聚合排队延迟指标(例如P99或Max,我们称之为 QD_metric)作为信号。
核心思想:
设定一个目标排队延迟 (QD_Target),例如 5ms。这是我们认为系统“健康”时能容忍的最大排队程度。
如果 当前的 QD_metric 低于或等于 QD_Target,说明系统还有余量,我们可以缓慢地增加并发限制,以探索更高的吞吐量(加性增)。
如果 当前的 QD_metric 高于 QD_Target,说明系统已经过载,出现了不可接受的排队,我们必须快速地降低并发限制,以缓解压力(乘性减)。
具体算式与伪代码 (每秒执行一次)
假设您的后台定时器(ngx.timer.at)每秒运行一次,执行以下逻辑:
输入参数 (需要您配置和调整):
QD_Target: 目标排队延迟 (例如 5.0 毫秒)
Increase_Step: 加性增加的步长 (例如 1 或 5 个并发连接)
Decrease_Factor: 乘性减少的因子 (例如 0.8 或 0.9,表示降低10%-20%)
Min_Limit: 全局并发限制的最低值 (安全下限,例如 50)
Max_Limit: 全局并发限制的最高值 (可选,物理上限,例如 10000)
您的“比值”想法也可以调整后使用! 关键在于如何定义“基线”。与其用一个不稳定的Baseline_QD ≈ 0,不如直接使用我们设定的目标 (QD_Target) 来构造一个信号:
信号 S = Current_QD / QD_Target
当 S < 1 时,系统健康。
当 S > 1 时,系统过载。
S 的值直接反映了当前排队延迟超出目标的倍数。
这个信号 S 非常直观且易于计算!我们可以直接将这个 S (或 S-1,代表超出目标的比例) 输入到Sigmoid函数中,来决定我们的Decrease_Factor。
所以,最终方案可以是:
测量: Current_QD (聚合后的 P99/Max 排队延迟)。
计算信号: Signal = Current_QD / QD_Target (例如 15ms / 5ms = 3)。
决策:
if Signal <= 1: 执行“加性增”。
if Signal > 1: 使用 Signal 的值(例如3)通过Sigmoid函数计算出一个介于[MinFactor, MaxFactor]之间的Decrease_Factor,然后执行“乘性减”。
这种方法结合了您对“比值”的直觉和Gradient算法对“过载程度”的反馈,并且避免了计算Delta的复杂性和噪声问题。我认为这是一个非常好的、实用的折衷方案!
Sigmoid或Logistic函数的作用是将一个可能无限范围的输入(如Signal或Gradient,理论上可以从0到正无穷)映射到一个有限的输出范围(通常是0到1,或者我们需要的MinFactor到MaxFactor)。
标准Logistic函数: f(x) = 1 / (1 + exp(-k * (x - x0)))
x: 输入信号(例如我们计算的 Signal = Current_QD / QD_Target)。
x0: 曲线的“中心点”。当x = x0时,f(x) = 0.5。这代表我们认为的“典型”或“中等”过载程度。
k: 控制曲线的“陡峭”程度。k越大,从低响应到高响应的过渡越快。k是正数。
exp: 自然指数函数。
输出范围是 (0, 1)。
如何将其映射到 [MinFactor, MaxFactor] (例如 [0.7, 0.95]) 来计算 Decrease_Factor?
我们需要一个线性变换: Decrease_Factor = MaxFactor - f(x) * (MaxFactor - MinFactor)
将两者结合,并使用我们的 Signal 作为输入 x:
1 | # x0: 我们认为 Signal 达到多少时,应该开始显著降低并发? |
这个变体的行为:
当Signal刚刚超过1一点点时,sigmoid_output接近0(如果x0>1),decrease_factor接近MaxFactor(例如0.95,温和降低)。
当Signal等于x0(例如2.0)时,sigmoid_output为0.5,decrease_factor在MinFactor和MaxFactor的中间(例如 0.95 - 0.5 * (0.95 - 0.7) = 0.825)。
当Signal非常大时(严重过载),sigmoid_output接近1,decrease_factor接近MinFactor(例如0.7,激进降低)。
这个Sigmoid变体提供了一种平滑的、可配置的方式,将您计算出的“过载程度”(Signal)映射到具体的“降低力度”(Decrease_Factor),比简单的固定因子AIMD更精细。